[논문리뷰] FinMCP-Bench: Benchmarking LLM Agents for Real-World Financial Tool Use under the Model Context Protocol
링크: 논문 PDF로 바로 열기
저자: Jie Zhu, Yimin Tian, Boyang Li, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- LLM Agents : 사용자 요청을 해석하고, 외부 도구를 호출하며, 다단계 추론을 수행할 수 있는 Large Language Models입니다.
- Model Context Protocol (MCP) : 다양한 서버 간의 도구 호출을 위한 표준화된 스키마를 제공하는 금융 도구 통합 프로토콜입니다.
- Single-tool sample : 단일 대화 턴(turn)에서 단일 도구 호출로 해결되는 태스크 유형입니다.
- Multi-tool sample : 단일 대화 턴 내에서 여러 도구 호출을 포함하며, 순차적 또는 병렬적으로 실행될 수 있는 태스크 유형입니다.
- Multi-turn sample : 여러 대화 턴에 걸쳐 진행되며, 각 턴에서 하나 이상의 도구를 호출할 수 있는 태스크 유형입니다.
- Tool Recall (TR) : 예측된 도구 세트와 참조 도구 세트에서 정확하게 예측된 도구의 수를 참조 도구 세트의 전체 도구 수로 나눈 값입니다.
- Tool Precision (TP) : 예측된 도구 세트와 참조 도구 세트에서 정확하게 예측된 도구의 수를 예측 도구 세트의 전체 도구 수로 나눈 값입니다.
- Tool F1 (TF1) : Tool Precision과 Tool Recall의 조화 평균으로, 두 지표의 균형을 측정합니다.
- Exact Match Rate (EMR) : 예측된 도구 조직이 참조 도구 조직과 정확히 일치하는 예측의 비율입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 Large Language Models (LLMs)는 금융 애플리케이션에서 agent 로서 사용자 요청을 해석하고, 외부 도구를 호출하며, 다단계 추론을 수행해야 하는 역할을 점점 더 많이 맡고 있습니다. 기존의 금융 도메인 LLM 평가 연구들은 특정 태스크에 국한되거나 도구 사용을 포함하지 않아 실제 시나리오를 반영하는 데 한계가 있었습니다. 특히, 실제 금융 태스크는 주식 동향, 펀드 보유 내역, 시장 분석과 같은 정보를 검색하기 위해 여러 도구 호출을 연쇄적으로 수행하며, 각 단계가 이전 결과에 의존하는 복잡한 implicit dependencies 를 포함합니다. 이러한 배경에서 저자들은 real-world financial scenarios 에서 Model Context Protocol (MCP) 도구 사용을 통해 LLM agent 의 성능을 포괄적으로 평가할 수 있는 새로운 벤치마크의 필요성을 제기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
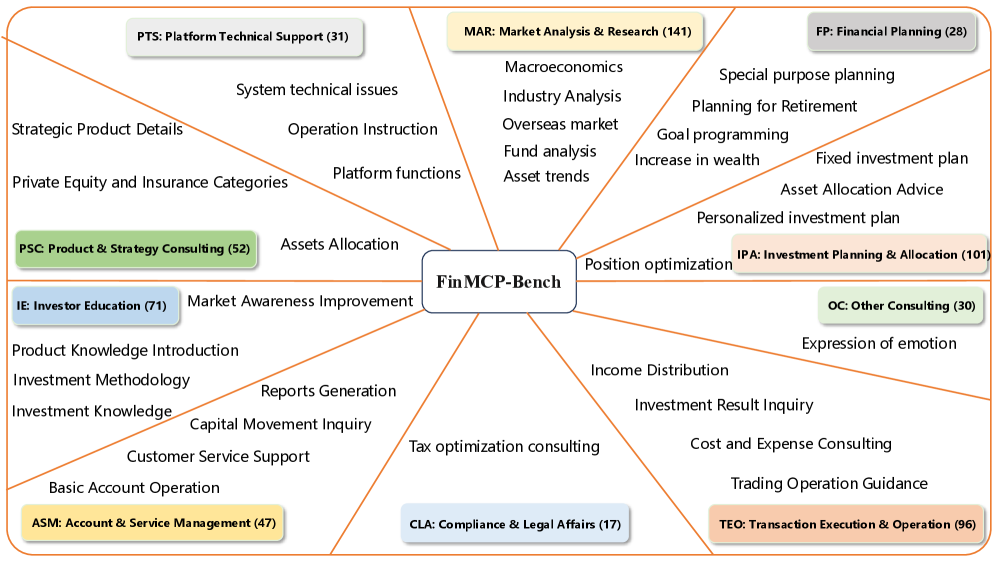
저자들은 LLM agents 가 실제 금융 문제 해결을 위해 financial model context protocols 를 활용하는 능력을 평가하기 위한 새로운 벤치마크인 FinMCP-Bench 를 제안합니다. 이 벤치마크는 10가지 주요 시나리오와 33가지 하위 시나리오에 걸쳐 총 613개 의 샘플을 포함하며, 실제 사용자 쿼리와 합성된 쿼리를 모두 활용하여 다양성과 진정성을 확보했습니다. 특히, 65개 의 실제 금융 MCPs 가 통합되었으며, Single-tool , Multi-tool , Multi-turn 세 가지 유형의 샘플을 통해 다양한 복잡성 수준의 태스크에서 모델을 평가할 수 있도록 구성되었습니다.
데이터셋 구축은 실제 운영 중인 금융 AI 보조장치인 XiaoGu AI assistant 의 10,000개 상호작용 기록에서 시작되었습니다. 이후 chain-based method 를 통해 tool dependency graph 를 구축하고 사용자 쿼리를 생성하여 Multi-tool sample 을 합성했으며
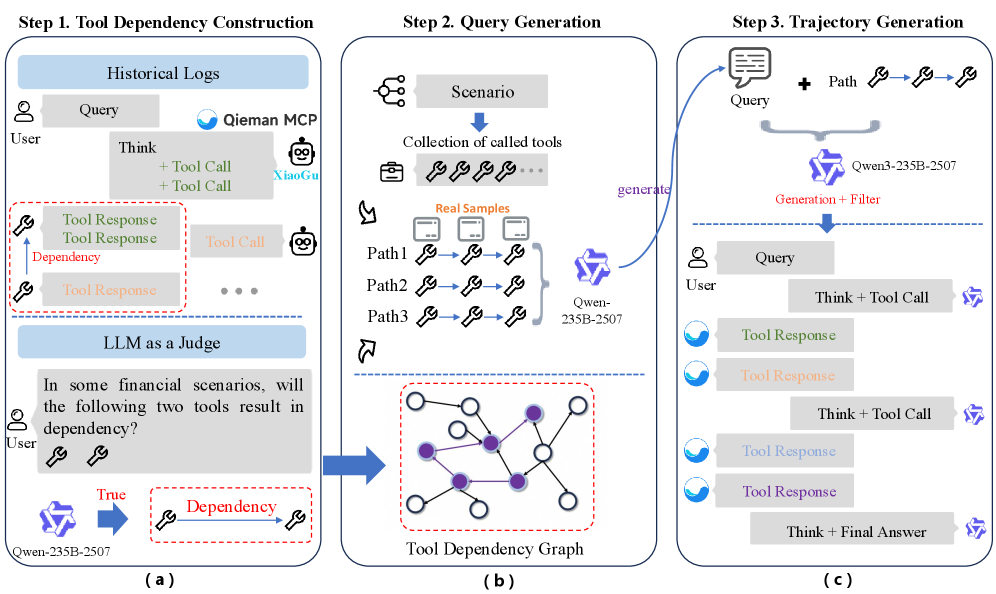
, role-playing-based method 를 통해 사용자 persona 와 goal 을 설정하고 Qwen3-235B-2507 을 활용하여 Multi-turn sample 을 합성했습니다 [Figure 3]. 벤치마크의 품질을 보장하기 위해 자동화된 유효성 검사 및 6명의 금융 도메인 전문가의 5-point Likert scale 기반 검토를 포함하는 2단계 Quality Control 파이프라인이 적용되었습니다.
평가 지표로는 Tool Recall (TR) , Tool Precision (TP) , Tool F1 (TF1) , 그리고 Exact Match Rate (EMR) 이 도입되었으며, 이는 최종 답변의 정확성보다는 도구 호출 능력에 초점을 맞춥니다. 실험 결과, FinMCP-Bench 는 Single-tool 샘플 145개, Multi-tool 샘플 249개 (평균 7.32개 MCP calls , 5.72단계), Multi-turn 샘플 219개 (평균 5.00개 도구, 5.95개 턴)를 포함합니다 [Table 1]. mainstream LLMs (예: Qwen3 family, DeepSeek-R1, GPT-OSS-20B, Seed-OSS-36B)에 대한 체계적인 평가에서 Qwen3 모델들이 전반적으로 높은 TF1 및 EMR 성능을 보였으며 [Table 2], 특히 Qwen3-30B-A3B-Thinking 및 Qwen3-235B-A22B-Thinking 이 10가지 주요 시나리오 전반에 걸쳐 강력하고 균형 잡힌 tool use 능력을 보여주었습니다
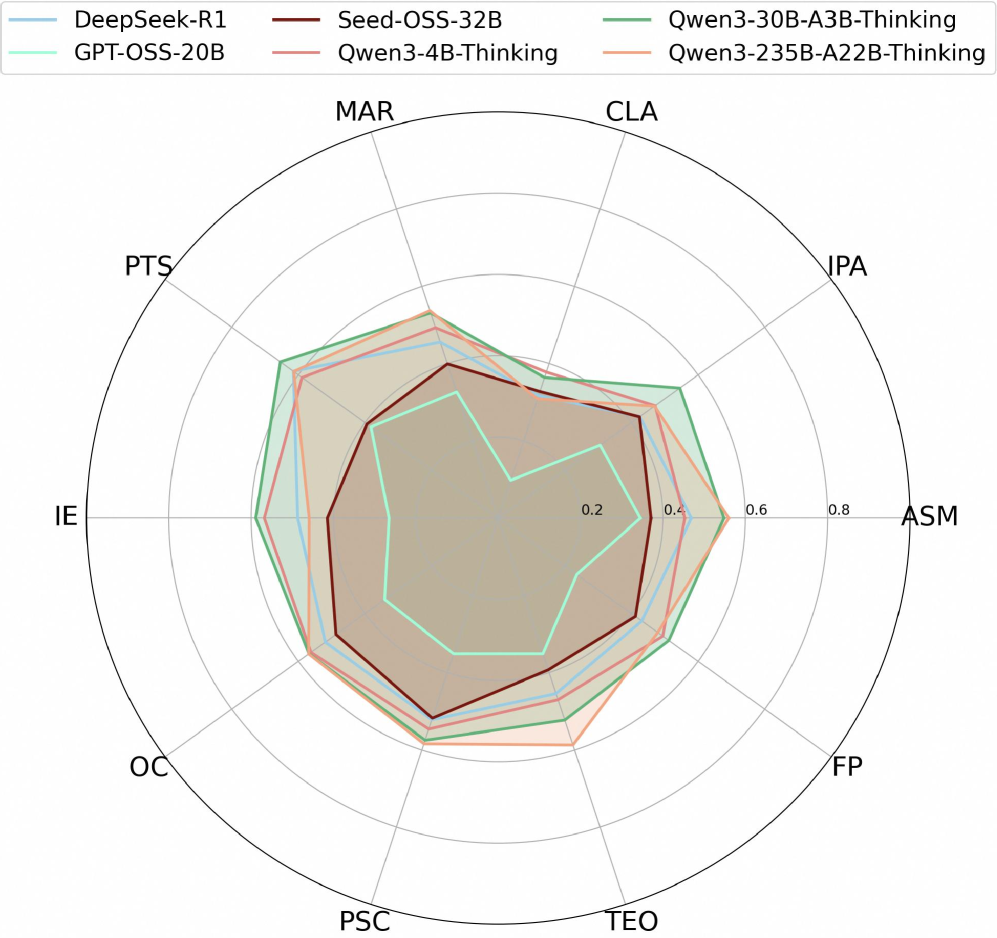
Multi-turn samples 는 모든 모델에서 가장 낮은 점수를 기록했는데, 특히 EMR 이 낮아 여러 도구 호출을 포함하는 긴 대화 처리의 어려움을 시사합니다. 흥미롭게도, 모델 크기가 항상 성능에 비례하지는 않았으며, 난이도별 분석에서 강력한 모델들은 Easy 에서 Hard 샘플로 갈수록 TF1 이 향상되는 경향을 보여, 더 복잡한 쿼리에서 풍부한 제약 조건과 Multi-tool opportunities 를 활용하는 능력을 나타냈습니다 [Figure 5].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Model Context Protocol (MCP) 도구 호출을 요구하는 실제 금융 시나리오에서 LLMs를 평가하기 위한 새로운 벤치마크인 FinMCP-Bench 를 소개합니다. 이 벤치마크는 Single-tool , Multi-tool , Multi-turn 세 가지 유형의 태스크를 포함하여 도구 사용 및 대화 상호작용의 다양한 복잡성 수준을 포괄합니다. 저자들은 여러 인기 있는 LLMs에 대한 광범위한 평가를 수행하고 다양한 차원에서 이들의 성능을 분석했습니다. 결과는 현재 모델의 강점과 함께, 특히 복잡한 Multi-tool dependencies 및 Multi-turn conversations 를 처리하는 데 있어 모델들이 직면하는 과제를 명확히 보여줍니다. FinMCP-Bench 는 금융 분야에서 tool-augmented LLMs 연구를 발전시키기 위한 표준화되고 도전적인 테스트베드 역할을 하며, 이 중요한 도메인에서 추론, 도구 조율 및 대화 능력 향상을 위한 미래 연구에 영감을 줄 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] MCP-Persona: Benchmarking LLM Agents on Real-World Personal Applications via Environment Simulation
- [논문리뷰] VitaBench: Benchmarking LLM Agents with Versatile Interactive Tasks in Real-world Applications
- [논문리뷰] SubtleMemory: A Benchmark for Fine-Grained Relational Memory Discrimination in Long-Horizon AI Agents
- [논문리뷰] OpenSkillEval: Automatically Auditing the Open Skill Ecosystem for LLM Agents
- [논문리뷰] SkillEvolBench: Benchmarking the Evolution from Episodic Experience to Procedural Skills
Review 의 다른글
- 이전글 [논문리뷰] Extending Precipitation Nowcasting Horizons via Spectral Fusion of Radar Observations and Foundation Model Priors
- 현재글 : [논문리뷰] FinMCP-Bench: Benchmarking LLM Agents for Real-World Financial Tool Use under the Model Context Protocol
- 다음글 [논문리뷰] IQuest-Coder-V1 Technical Report
댓글