[논문리뷰] Representation Alignment for Just Image Transformers is not Easier than You Think
링크: 논문 PDF로 바로 열기
저자: Jaeyo Shin, Jiwook Kim, Hyunjung Shim
1. Key Terms & Definitions (핵심 용어 및 정의)
- REPA (Representation Alignment) : Latent space Diffusion Transformers (DiT)의 학습 속도를 가속화하고 샘플 품질을 향상시키기 위해 중간 Diffusion Transformer 활성화를 외부 Semantic Encoder의 피처와 정렬하는 방법론입니다.
- JiT (Just Image Transformers) : 사전 학습된 토크나이저에 대한 의존성을 제거하고 Latent Diffusion의 재구성 Bottleneck을 회피하며, 원본 이미지에 End-to-End로 학습될 수 있는 Pixel-space Diffusion Transformer 모델입니다.
- Feature Hacking : Pixel-space Diffusion에서 Compressed Semantic Target으로 직접 Regression을 강제할 때, 모델이 좁은 외부 Feature Space에 Overfitting되어 Semantic Feature가 매우 유사하지만 Pixel-wise로는 다양한 이미지들의 생성 다양성이 저하되는 현상입니다.
- PixelREPA : 표준 REPA의 MLP Projection을 Masked Transformer Adapter (MTA)로 대체하여 Pixel Space Diffusion 모델에 특화된 Representation Alignment 프레임워크입니다.
- MTA (Masked Transformer Adapter) : Shallow Transformer Adapter와 Partial Masking Strategy를 결합하여 Alignment Target을 변환하고 Alignment Pathway를 제약하는 PixelREPA의 핵심 구성 요소입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
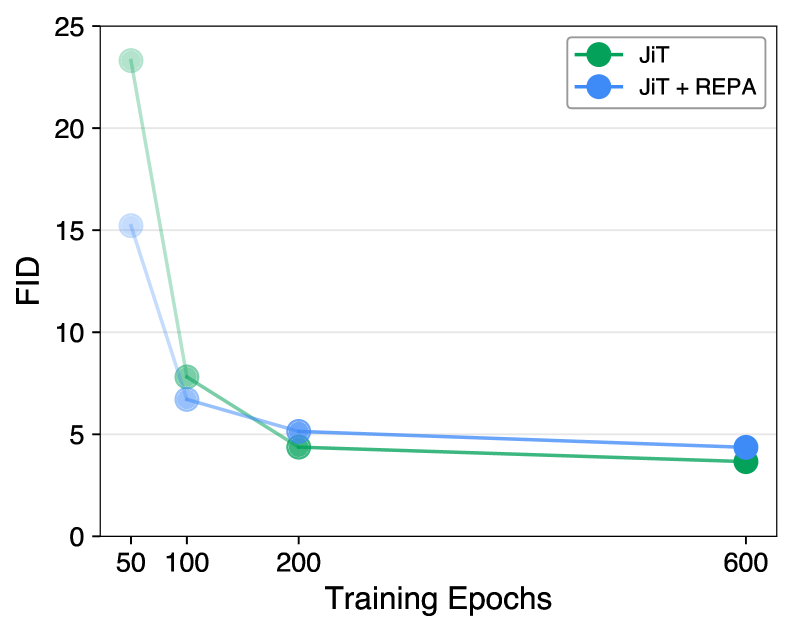
Representation Alignment (REPA)는 Latent Space Diffusion Transformer의 학습을 가속화하는 효과적인 방법으로 제시되었으나, Just Image Transformers (JiT)와 같은 Pixel-space Diffusion 모델에 이를 적용할 경우 오히려 성능 저하를 야기합니다. 구체적으로, 학습이 진행될수록 FID 가 악화되고, 사전 학습된 Semantic Encoder의 Representation Space에서 밀접하게 Clustering된 이미지 Subset에 대한 다양성이 붕괴되는 현상이 관찰되었습니다
저자들은 이러한 실패의 원인을 Denoising이 High-dimensional Image Space에서 발생하는 반면, Semantic Target은 강하게 Compressed되어 직접적인 Regression이 Shortcut Objective로 작용하는 정보 비대칭 (Information Asymmetry) 에서 찾습니다. Latent Diffusion Models (LDMs)에서는 Denoising Space와 Alignment Target 모두 정보 Bottleneck을 거쳐 Degrees of Freedom이 일치하지만, Pixel Space에서는 Denoising이 O(H×W)의 자유도를 가진 Image Space에서 이루어지고 Semantic Encoder는 Compact한 Bottleneck Representation을 생성하여 정보 격차가 크기 때문입니다
이로 인해 Pixel-distinct한 많은 이미지가 Semantic Encoder의 Feature Space에서는 유사한 영역에 매핑되어 Feature Hacking 이 발생하며, 이는 모델이 좁은 외부 Feature Space에 Overfit되어 다양성 있는 이미지 생성 능력을 상실하게 만듭니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구에서는 Pixel-space Diffusion에서의 REPA 실패를 해결하기 위해 PixelREPA 를 제안합니다. PixelREPA는 Alignment Target을 변환하고 Alignment Pathway를 Masked Transformer Adapter (MTA) 로 제약함으로써 문제를 해결합니다
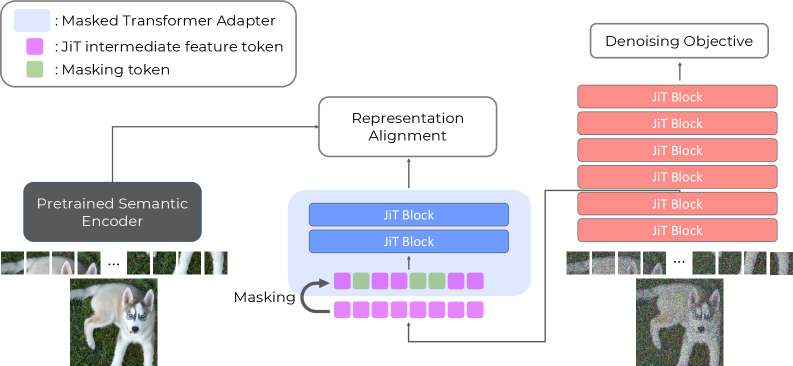
MTA는 두 가지 핵심 구성 요소로 이루어져 있습니다:
- Shallow Transformer Adapter : JiT Encoder의 중간 Feature를 외부 Semantic Feature Space로 변환하기 위한 2-Layer Transformer Adapter입니다. 이는 JiT Feature가 Compressed Target에 직접 강제되지 않도록 선택적으로 Semantic Content를 추출하고 Projection하여 Alignment Target을 변환합니다. 또한 Self-Attention을 통해 Contextual Aggregation을 수행하여 Per-token Correspondence에 대한 의존성을 줄여 Feature Hacking을 완화합니다.
- Partial Masking Strategy : Adapter Input에 랜덤하게 토큰의 일부를 Masking (Mask Ratio r=0.2 사용)하여 Shortcut Learning을 방지하고 Information Bottleneck 역할을 합니다. 이는 Adapter가 부분적인 관찰로부터 전체 Semantic Target을 예측하도록 강제하여 진정한 Contextual Reasoning을 요구하며, Pixel Representation과 Compressed Semantic Target 간의 정보 격차를 줄여 두 Space의 호환성을 높입니다. 이 Masking은 Alignment Branch에만 적용되며 Main Denoising Pathway는 수정하지 않아 추론 시 추가 비용이 발생하지 않습니다.
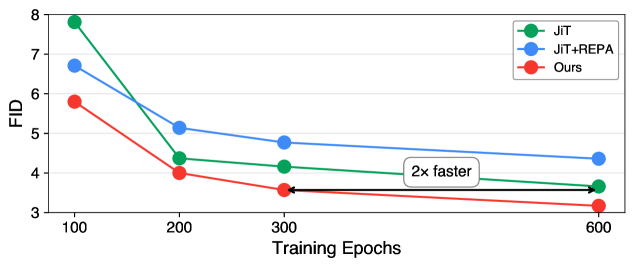
실험 결과, PixelREPA는 Vanilla JiT 대비 Convergence Speed와 Generation Quality 모두를 향상시켰습니다. ImageNet 256x256 에서 PixelREPA-B/16/16 은 JiT-B/16/16 대비 FID 를 3.66 에서 3.17 로 감소시켰고 ( 13.4% 향상), Inception Score (IS) 는 275.1 에서 284.6 으로 개선하며 2배 이상 빠른 수렴 을 달성했습니다. 특히 PixelREPA-H/16/16 모델은 FID 1.81 , IS 317.2 를 기록하며, 파라미터 수가 약 2배 많은 JiT-G/16/16의 FID 1.82 를 능가하는 성능을 보였습니다. 이는 PixelREPA가 모델 Scale에 강건하며 Parameter Utilization 효율이 높음을 입증합니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 High-resolution Pixel-space Diffusion에서 기존 REPA가 Compressed Semantic Target으로의 Alignment로 인해 Feature Hacking 을 유발하고 학습을 저해하는 문제점을 명확히 밝혀냈습니다. 이에 대한 해결책으로, Alignment Target을 변환하고 Shallow Transformer Adapter와 Partial Token Masking을 통해 Alignment Pathway를 제약하는 PixelREPA 를 제안했습니다. PixelREPA의 Masked Transformer Adapter (MTA) 는 최적화를 안정화시키고 모델 Scale에 따라 성능이 향상되며, ImageNet 256x256 에서의 JiT Backbone 결과들을 일관되게 개선합니다. 이 연구는 High-resolution Pixel-space Diffusion 모델의 학습 효율성과 생성 품질을 크게 향상시킬 수 있는 Practical하고 Robust한 Alignment Framework를 제공하며, 이는 향후 더욱 고해상도 이미지 생성 모델 개발에 중요한 시사점을 줍니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] MaskAlign: Token-Subset Representation Alignment for Efficient Diffusion Training
- [논문리뷰] High-Fidelity Two-Step Image Generation via Teacher-Aligned End-to-End Distillation
- [논문리뷰] Training-Free Multi-Concept LoRA Composition with Prompt-Aware Weighting
- [논문리뷰] DreamLite: A Lightweight On-Device Unified Model for Image Generation and Editing
- [논문리뷰] SeaCache: Spectral-Evolution-Aware Cache for Accelerating Diffusion Models
Review 의 다른글
- 이전글 [논문리뷰] RealRestorer: Towards Generalizable Real-World Image Restoration with Large-Scale Image Editing Models
- 현재글 : [논문리뷰] Representation Alignment for Just Image Transformers is not Easier than You Think
- 다음글 [논문리뷰] Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes
댓글