[논문리뷰] Evaluation-driven Scaling for Scientific Discovery
링크: 논문 PDF로 바로 열기
저자: Haotian Ye, Haowei Lin, Jingyi Tang, Yizhen Luo, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- SIMPLETES (Simple Test-time Evaluation-driven Scaling): 평가 루프를 통해 과학적 발견을 수행하는 범용적 프레임워크로,
global width,refinement depth,local sample size의 세 가지 차원을 사용하여 최적화된 탐색을 수행함. - Evaluation-driven Discovery Loop: verifiers, simulators, 또는 task-specific scoring functions로부터 피드백을 얻어 후보 솔루션을 iteratively refine 하는 Trial-and-error 프로세스.
- RPUCG (Recursive Progressive Upper Confidence Grounding): 과거 경험(Historical nodes)을 기반으로 문맥을 선택하여 새로운 proposal을 생성하는 그래프 기반의 선택 알고리즘.
- Golden Metric: 연구자가 궁극적으로 달성하고자 하는 실제 성능 지표로, 평가 과정에서 사용되는 surrogate evaluator와는 잠재적인 불일치가 존재할 수 있음.
- RLVR (Reinforcement Learning with Verifiable Rewards): 최종 trajectory 성능을 보상으로 사용하고 중간의 myopic 신호를 배제하여 전역적인 최적화를 유도하는 학습 방법론.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 과학적 발견 과정에서 LLM을 활용한 Trial-and-error 루프의 확장성(Scaling) 문제를 공식화하고 이를 체계적으로 해결하고자 합니다. 기존의 연구들은 주로 생성 단계의 컴퓨팅이나 추론 토큰 수, 에이전트 턴(turns)의 확장에는 집중해 왔으나, 발견의 핵심인 평가 루프(Evaluation-driven loop)를 체계적으로 확장하는 방법론은 탐구되지 않았습니다. 결과적으로, 기존의 휴리스틱한 접근 방식들은 경로 의존적인 성격으로 인해 로컬 옵티마에 갇히거나 평가 피드백을 효과적으로 활용하지 못하는 한계가 있었습니다. 이를 해결하기 위해 저자들은 평가 기반 발견 루프를 세 가지 핵심 차원으로 분리하여 제어 가능한 탐색 공간을 구축하였습니다 [Figure 1].
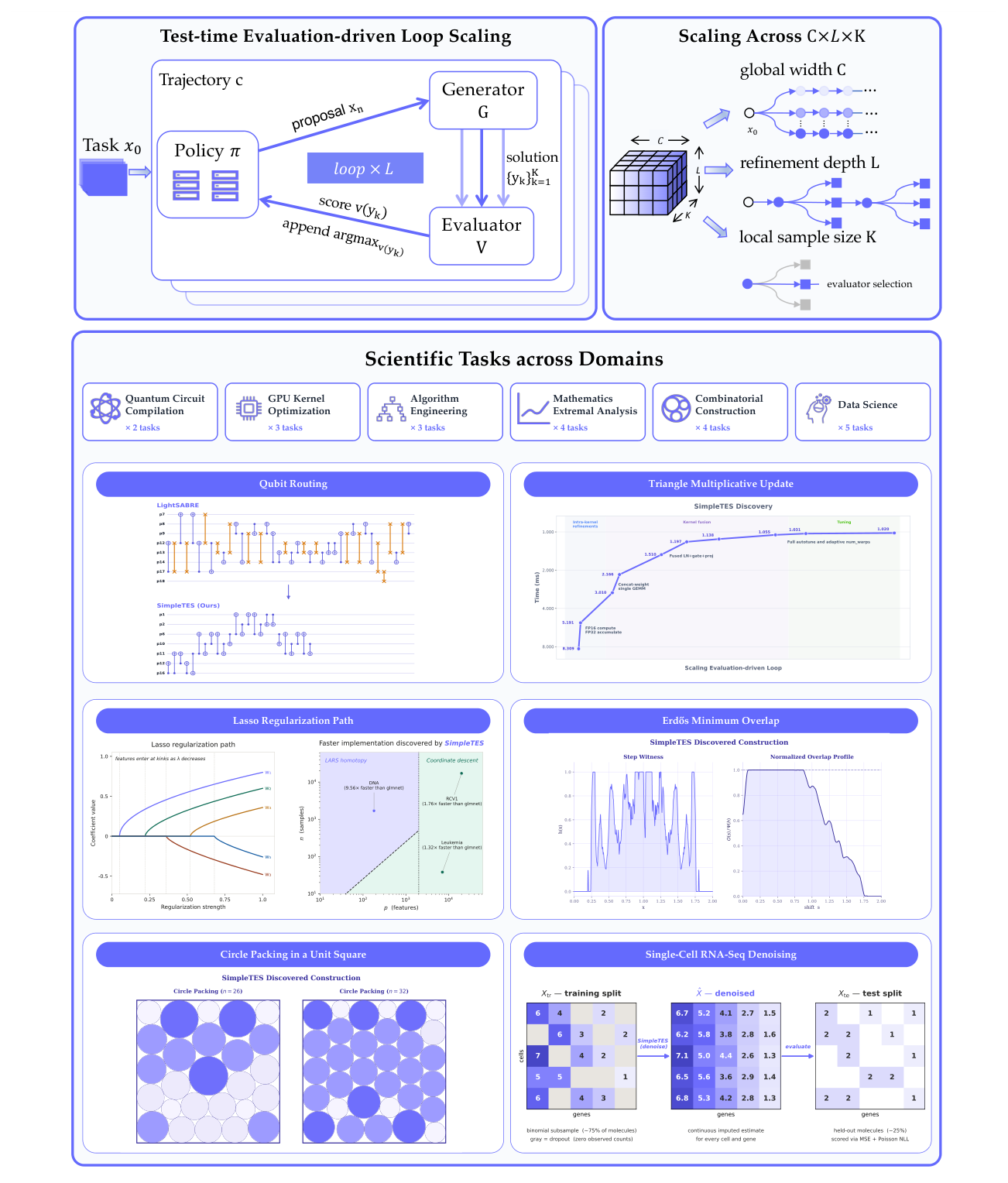
Figure 1 — SIMPLETES의 핵심 알고리즘과 3가지 스케일링 차원을 보여주는 아키텍처 다이어그램
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문이 제안하는 SIMPLETES 프레임워크는 평가 쿼리 예산 $N$을 global width $C$, refinement depth $L$, **local sample size $K$**에 효율적으로 할당하여 과학적 발견의 효율성을 극대화합니다. Global width는 병렬 탐색을 통해 경로 의존성을 극복하며, refinement depth는 피드백을 축적하여 점진적인 개선을 도모하고, local sample size는 후보 솔루션의 품질을 보장합니다 [Figure 1]. 또한, Trajectory-level post-training을 통해 모델이 개별적인 순간 보상이 아닌 전체 trajectory의 최대 성능을 학습하도록 함으로써 일반화 성능을 향상시켰습니다.
주요 실험 결과로서, SIMPLETES는 6개 도메인, 21개 문제에 걸쳐 gpt-oss-120b 모델만을 사용함에도 불구하고 SOTA급 성능을 달성하였습니다.
- Quantum Circuit Compilation: IBM Q20에서 SABRE 대비 24.5%의 CNOT 오버헤드 감소를 기록하였습니다.
- GPU Kernel Optimization: TriMul 연산에서 H100 기준 1.122ms의 성능으로 기존 AI baselines 및 GPUMode Triton 제출 기록을 상회하였습니다 [Table 4].
- Algorithm Engineering: LASSO 문제에서
glmnet대비 평균 2.17배,sklearn대비 14.08배의 속도 향상을 보여주며 고차원 데이터셋에서 뛰어난 알고리즘적 설계를 확인하였습니다.
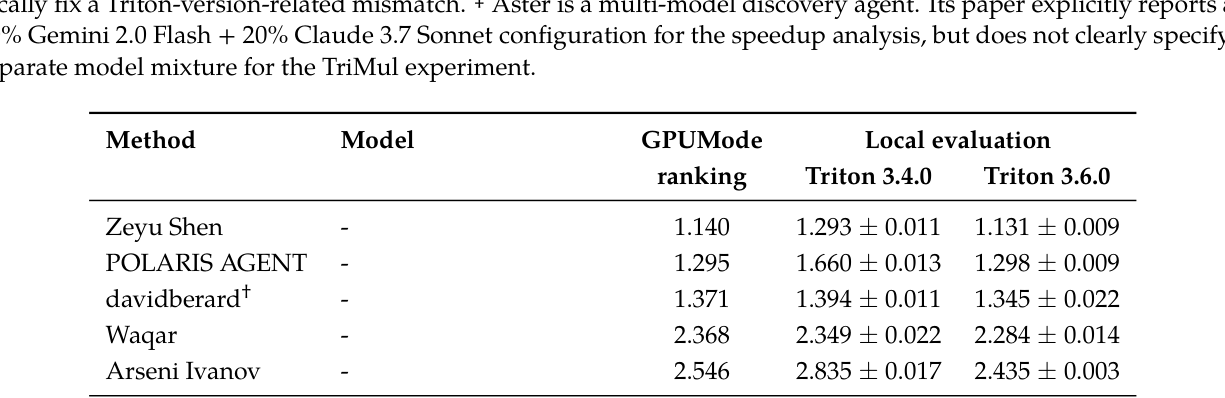
Table 4 — GPU Kernel Optimization 분야에서 제안 방법론의 우수성을 정량적으로 보여주는 핵심 결과 테이블
4. Conclusion & Impact (결론 및 시사점)
본 연구는 과학적 발견의 핵심인 평가 중심 루프를 원칙적으로 확장하는 것이 모델 자체의 성능을 확장하는 것만큼 중요함을 증명하였습니다. 제안된 SIMPLETES는 도메인 특화된 엔지니어링 없이도 수학, 공학, 데이터 과학 등 다양한 분야에서 일관된 성능 향상을 입증하였습니다. 특히, 평가 지표와 실제 성능 간의 격차(Reward hacking)를 분석하고, trajectory-level 피드백을 통해 모델이 일반화 가능한 발견 행동을 학습할 수 있음을 보였습니다. 이러한 성과는 향후 LLM 기반의 자율적 과학 연구 에이전트 개발을 위한 실질적인 프레임워크가 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] EconProver: Towards More Economical Test-Time Scaling for Automated Theorem Proving
- [vllm] vLLM에서 Lfm2VL 모델을 위한 Encoder CUDA Graph 최적화 적용
- [논문리뷰] ToolSense: A Diagnostic Framework for Auditing Parametric Tool Knowledge in LLMs
- [논문리뷰] MaxProof: Scaling Mathematical Proof with Generative-Verifier RL and Population-Level Test-Time Scaling
- [논문리뷰] EvoBrowseComp: Benchmarking Search Agents on Evolving Knowledge
Review 의 다른글
- 이전글 [논문리뷰] Dual-View Training for Instruction-Following Information Retrieval
- 현재글 : [논문리뷰] Evaluation-driven Scaling for Scientific Discovery
- 다음글 [논문리뷰] HP-Edit: A Human-Preference Post-Training Framework for Image Editing
댓글