[논문리뷰] WebGen-R1: Incentivizing Large Language Models to Generate Functional and Aesthetic Websites with Reinforcement Learning
링크: 논문 PDF로 바로 열기
저자: Juyong Jiang, Chenglin Cai, Chansung Park, Jiasi Shen, Sunghun Kim, Jianguo Li, Yue Wang
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- WebGen-R1: 프로젝트 수준의 다중 페이지 웹사이트 생성을 위해 제안된 end-to-end RL 프레임워크입니다.
- Scaffold-driven structured generation: 사전 검증된 React 템플릿을 골격으로 활용하여 생성 공간을 제한하고 아키텍처 무결성을 보장하는 방식입니다.
- GRPO (Group Relative Policy Optimization): 샘플 그룹 내에서 보상을 정규화하여 학습의 분산을 줄이고 안정성을 높이는 RL 최적화 알고리즘입니다.
- Cascaded Multimodal Reward: 구조적 무결성, 기능적 정확성, 미적 품질을 단계적으로 평가하는 결합형 보상 모델입니다.
- FSR (Functional Success Rate): 웹사이트의 상호작용 기능이 사전 정의된 테스트 케이스를 통과하는 비율을 측정하는 지표입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 기존 LLM 기반 웹사이트 생성 방식이 겪고 있는 확장성 및 품질 한계를 해결하고자 합니다. 기존 단일 페이지 중심의 생성 방식은 실제 웹 서비스에 필요한 동적 라우팅이나 복잡한 아키텍처 요구사항을 충족하지 못하며, 다중 에이전트 기반 프레임워크는 높은 토큰 비용과 brittle한 통합 문제라는 결함을 가집니다. 특히, 웹사이트 생성은 단위 테스트만으로는 평가하기 어려운 주관적 미학적 요소와 복잡한 기능적 요구사항이 결합되어 있어 효과적인 보상 신호를 설계하기 매우 어렵습니다. [Figure 1]에서 제시된 scaffold 기반 프레임워크는 이러한 문제를 해결하고 기능적 웹사이트 생성을 가능하게 하는 통합 솔루션을 제공합니다.
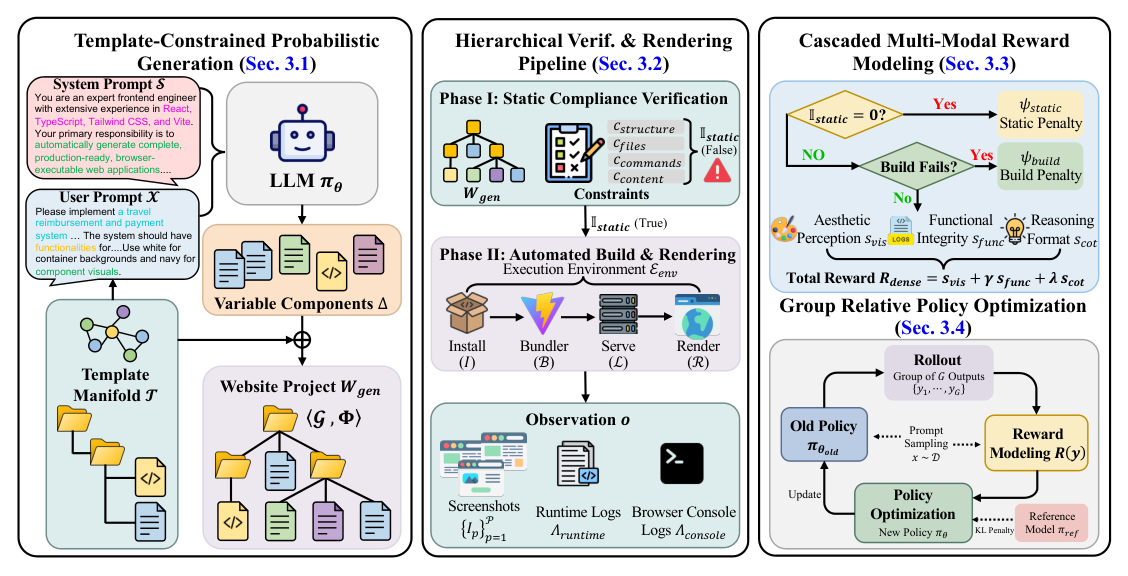
Figure 1 — WebGen-R1의 전체 프레임워크 구조와 워크플로우를 시각화한 핵심 다이어그램
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 논문은 scaffold-driven 생성 패러다임과 cascaded multimodal reward를 결합하여 WebGen-R1 프레임워크를 구축하였습니다. LLM은 전체 프로젝트를 처음부터 생성하는 대신, 사전 검증된 React 템플릿 내에서 필요한 컴포넌트만을 생성하며, 이는 hierarchical verification pipeline을 통해 구조적 할루시네이션을 제거합니다. 최종 보상 함수는 구조적 제약 준수, 런타임 기능 무결성, VLM을 활용한 미적 평가를 가중치 조합하여 산출됩니다. [Table 1]에 따르면, WebGen-R1-7B는 FSR 29.21%, AAS 3.94, VRR 95.89%를 기록하며, 베이스 모델인 Qwen2.5-Coder-7B-Instruct 대비 압도적인 성능 향상을 보였습니다. 이는 72B 규모의 오픈 소스 모델들을 상회하는 결과이며, 최상위 Proprietary 모델들과 견줄 수 있는 기능적 성공을 달성했음을 의미합니다.
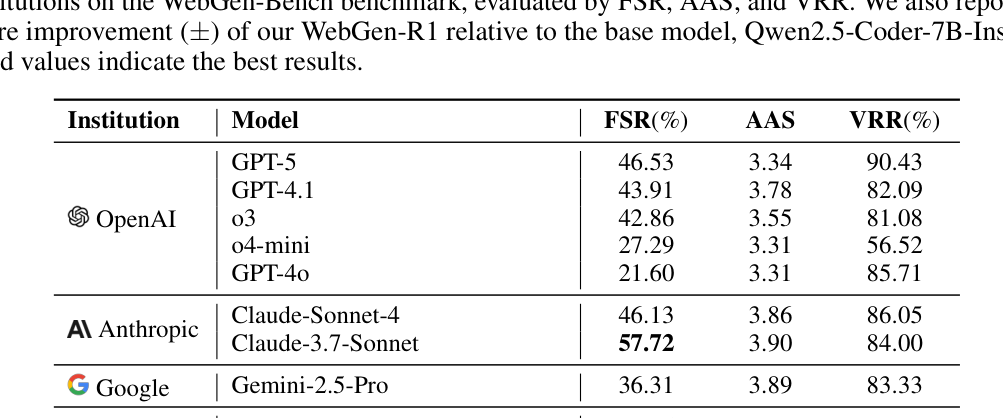
Table 1 — 주요 모델들과의 성능(FSR, AAS, VRR)을 비교한 핵심 결과 테이블
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 end-to-end RL 학습이 소규모 LLM의 기능적, 미적 웹사이트 생성 능력을 획기적으로 개선할 수 있음을 입증하였습니다. 제안된 scaffold 기반 구조와 다단계 보상 모델은 프로젝트 수준의 복잡한 소프트웨어 엔지니어링 문제를 LLM이 해결할 수 있는 새로운 가능성을 제시합니다. 이러한 접근 방식은 향후 full-stack 웹 개발 자동화 및 복잡한 구조적 제약이 필요한 코드 생성 분야에서 표준적인 RL 최적화 방법론으로 활용될 것으로 기대됩니다.
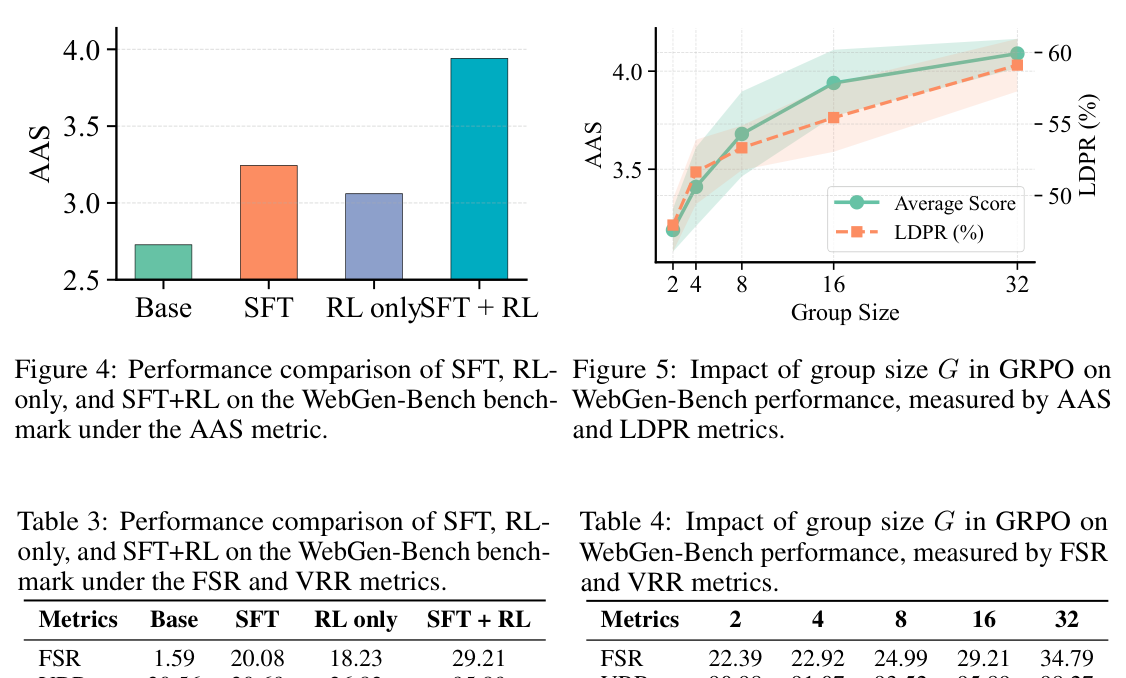
Table 3 — SFT와 RL 조합에 따른 성능 향상폭을 보여주는 핵심 방법론 검증 테이블
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] N-GRPO: Embedding-Level Neighbor Mixing for Enhanced Policy Optimization
- [논문리뷰] Verifiable Rewards Beyond Math and Code: Lightweight Corpus-Grounded Process Supervision for Factual Question Answering
- [논문리뷰] FIPO: Eliciting Deep Reasoning with Future-KL Influenced Policy Optimization
- [논문리뷰] RetroAgent: From Solving to Evolving via Retrospective Dual Intrinsic Feedback
- [논문리뷰] Self-Hinting Language Models Enhance Reinforcement Learning
Review 의 다른글
- 이전글 [논문리뷰] VLAA-GUI: Knowing When to Stop, Recover, and Search, A Modular Framework for GUI Automation
- 현재글 : [논문리뷰] WebGen-R1: Incentivizing Large Language Models to Generate Functional and Aesthetic Websites with Reinforcement Learning
- 다음글 [논문리뷰] WorldMark: A Unified Benchmark Suite for Interactive Video World Models
댓글