[논문리뷰] AutoGUI-v2: A Comprehensive Multi-Modal GUI Functionality Understanding Benchmark
링크: 논문 PDF로 바로 열기
메타데이터
저자: Hongxin Li, Xiping Wang, Jingran Su, Zheng Ju, Yuntao Chen, Qing Li, Zhaoxiang Zhang
1. Key Terms & Definitions (핵심 용어 및 정의)
- Functional Region: 개별 UI 요소(버튼, 아이콘 등)들의 집합으로, 사용자의 특정 목적을 수행하기 위해 함께 기능하는 계층적 영역을 의미함.
- Normalized Interference Density (NID): 대상 영역 주변에 존재하는 다른 UI 요소들의 밀도를 정량화하여, 모델이 겪는 시각적 간섭 수준을 측정하는 지표.
- Functionality-Oriented Grounding/Captioning: 단순히 외형(Appearance)이나 의도(Intent)를 기반으로 하지 않고, 요소가 가진 근본적인 기능(Functionality)을 이해해야만 정확한 위치 선정이나 결과 예측이 가능한 평가 태스크.
- Recursive "Divide-and-Verify" Pipeline: VLM을 사용하여 GUI 스크린샷을 계층적으로 분해하고, 별도의 스코어러 VLM을 통해 품질을 검증하는 반복적 데이터 생성 프로세스.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현재 GUI 에이전트 평가 방식이 단순한 시각적 요소 매칭에 치중되어 있어, 실제 디지털 환경에서의 복잡한 상태 변화와 GUI 동역학을 이해하는 능력을 측정하지 못한다는 문제를 해결하고자 한다. 기존 벤치마크들은 블랙박스식 태스크 완료 평가나 매우 단순한 요소 위치 선정에 국한되어 있어, 에이전트가 GUI의 함축적 기능이나 상호작용 후 발생할 결과(Digital World State)를 예측하는지 판단하기 어렵다. 저자들은 이러한 한계를 극복하기 위해 계층적 기능 이해와 예측 능력을 엄격하게 테스트할 수 있는 새로운 벤치마크가 필요하다고 주장한다 [Figure 2].
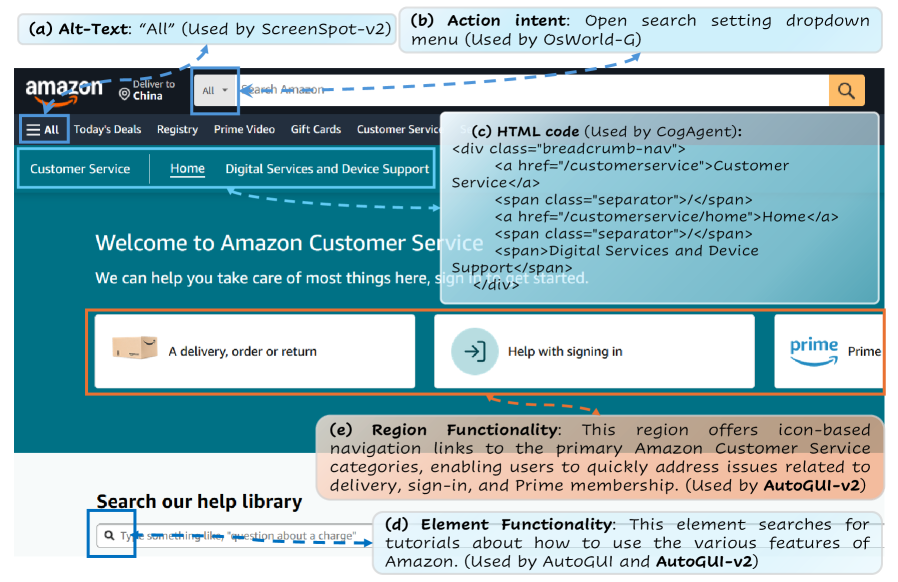
Figure 2 — 기능적 의미론 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Gemini-2.5-Pro-Thinking과 인간 피드백을 결합한 계층적 기능 영역 파싱 파이프라인을 통해 AutoGUI-v2 벤치마크를 구축하였다 [Figure 3]. 제안하는 방법론은 스크린샷을 재귀적으로 분해하여 고해상도 기능 영역을 정의하고, 이를 바탕으로 기능 기반의 위치 선정(Grounding)과 상호작용 결과 예측(Captioning) 태스크를 생성한다. 실험 결과, 모델 능력 간의 뚜렷한 이분법적 차이가 관찰되었다. 위치 선정(Grounding) 태스크에서는 Qwen3-VL-32B-Instruct와 같은 특화된 오픈소스 모델이 성능 우위를 점한 반면, 기능 설명(Captioning) 태스크에서는 Gemini-2.5-Pro-Thinking 등 상용 모델이 더 높은 성능을 보였다 [Table 3, Table 4]. 또한, 모든 모델들이 공통적으로 복잡한 상호작용 논리나 흔치 않은 액션 유형에서 급격한 성능 저하를 보였으며, 이는 기능 이해가 여전히 심각한 난제임을 시사한다 [Table 6, Table 7].
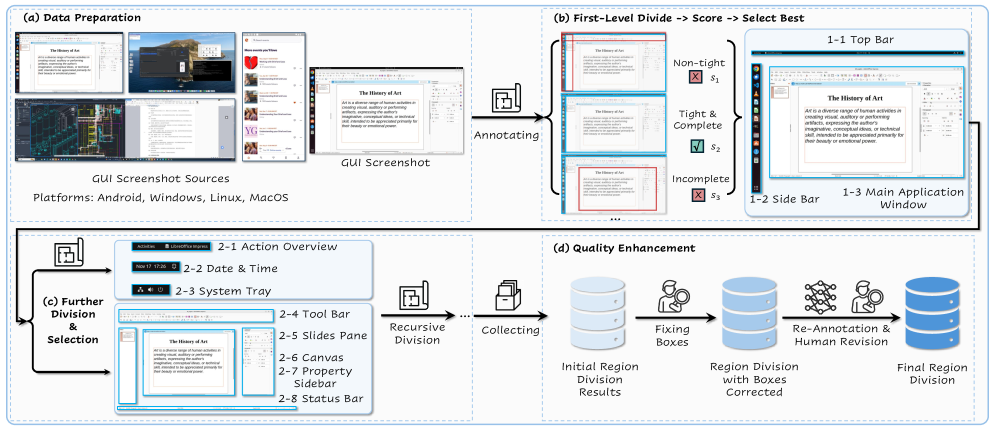
Figure 3 — 데이터 구축 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 논문은 GUI 에이전트의 심층적인 기능 이해도를 측정하는 포괄적인 벤치마크 AutoGUI-v2를 제안하여, 단순한 grounding을 넘어 동적 GUI 상황에 대한 모델의 추론 능력을 평가하는 새로운 기준을 제시한다. 연구 결과는 기능적 grounding과 reasoning 능력이 서로 다른 역량임을 시사하는 ‘grounding-reasoning divergence’ 현상을 포착하였다. 본 연구는 차세대 GUI 에이전트 개발을 위한 가이드라인을 제공하며, 학계와 산업계가 모델의 기초적인 인지 역량을 비판적으로 점검하는 도구로 활용될 것으로 기대된다.
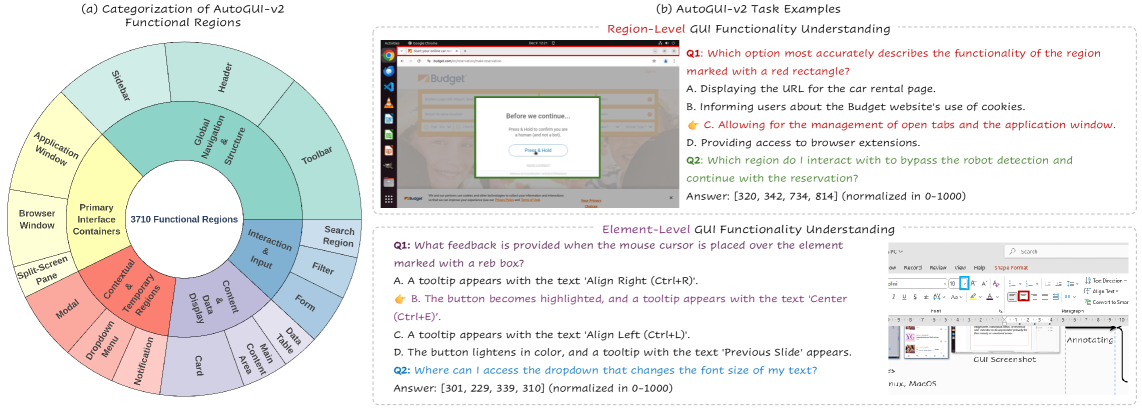
Figure 1 — AutoGUI-v2 개요
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] GUI-KV: Efficient GUI Agents via KV Cache with Spatio-Temporal Awareness
- [논문리뷰] MobiAgent: A Systematic Framework for Customizable Mobile Agents
- [논문리뷰] Thinking with Visual Grounding
- [논문리뷰] Trust the Right Teacher: Quality-Aware Self-Distillation for GUI Grounding
- [논문리뷰] Guava: An Effective and Universal Harness for Embodied Manipulation
Review 의 다른글
- 이전글 [논문리뷰] WorldMark: A Unified Benchmark Suite for Interactive Video World Models
- 현재글 : [논문리뷰] AutoGUI-v2: A Comprehensive Multi-Modal GUI Functionality Understanding Benchmark
- 다음글 [논문리뷰] GoClick: Lightweight Element Grounding Model for Autonomous GUI Interaction
댓글