[논문리뷰] PhysicianBench: Evaluating LLM Agents in Real-World EHR Environments
링크: 논문 PDF로 바로 열기
메타데이터
저자: Ruoqi Liu, Imran Q. Mohiuddin, Austin J. Schoeffler, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- PhysicianBench: 실제 임상 상담 사례를 기반으로 설계된, 전자건강기록(EHR) 환경에서 LLM agent의 다단계 임상 워크플로우 수행 능력을 평가하는 벤치마크.
- FHIR (Fast Healthcare Interoperability Resources): 현대 EHR 시스템에서 의료 데이터 교환을 위해 널리 사용되는 표준 API 규격으로, 본 연구의 Agent-EHR 상호작용 매개체.
- Checkpoint-based Evaluation: 최종 결과물만 평가하는 대신, 작업 수행 과정상의 중간 단계(milestones)를 구조화하여 에이전트의 추론 및 행동 오류를 정밀 진단하는 평가 프레임워크.
- Pass@1 / Pass^3: 단일 시도 성공률(Pass@1) 및 3회 독립 시행 시 모든 회차의 일관된 성공을 측정하는 신뢰성 지표(Pass^3).
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 의료용 AI 벤치마크들이 정적 지식 회상이나 단일 단계 작업에 국한되어, 실제 의료 현장에서 요구되는 복합적이고 긴 호흡의 임상 워크플로우를 평가하지 못하는 한계를 해결하고자 한다. 기존 연구들은 실제 EHR 환경에서의 행동 실행(Action Execution) 및 검증(Verifiable Execution)이 결여되어 에이전트의 실질적 임상 유효성을 측정하기 어렵다는 문제가 있다. 이를 위해 본 연구는 실제 환자 기록과 표준 API를 사용하여 임상 워크플로우를 충실히 재현한 PhysicianBench를 제안한다 [Figure 2].
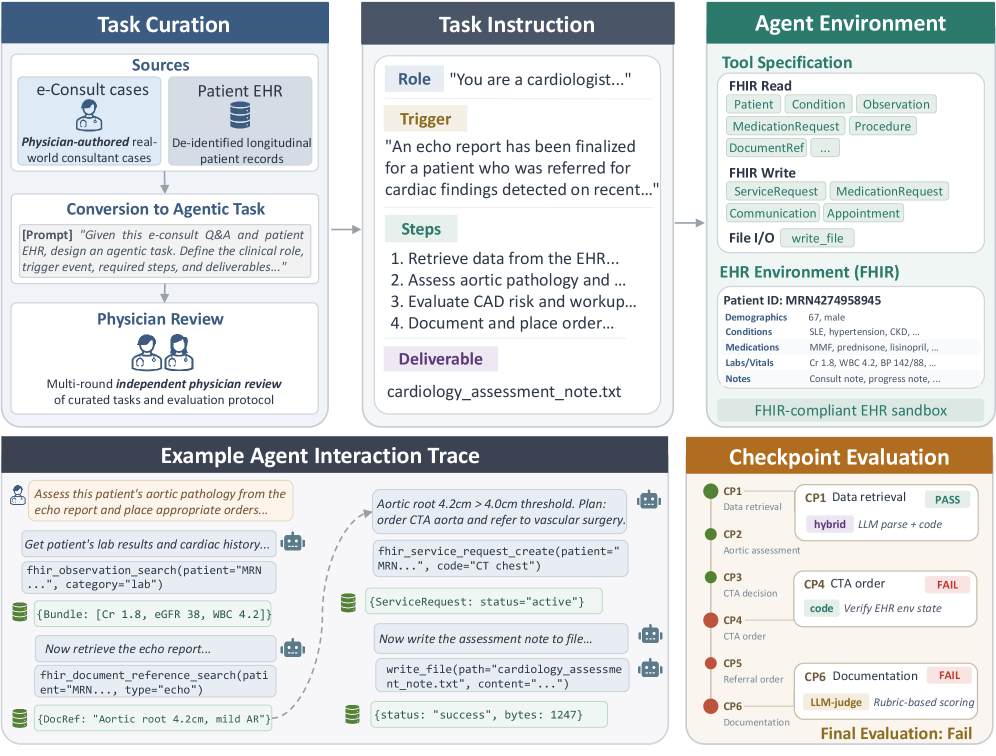
Figure 2 — 벤치마크 전체 파이프라인
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 임상 상담 사례에서 추출한 100개의 과제를 FHIR 표준을 따르는 EHR 환경에 배포하고, 의사 패널이 다단계 검증 파이프라인을 통해 임상적 정확성을 보장하는 평가 체계를 제안한다. 각 작업은 평균 27회의 툴 호출을 요구하며, 데이터 검색, 임상 추론, 행동 실행, 기록 작성이라는 실제 임상 과정을 평가한다. 총 12개의 LLM을 평가한 결과, 최고 성능 모델인 GPT-5.5조차 46.3%의 Pass@1 성능을 기록하는 데 그쳤으며, 오픈소스 모델은 최대 19% 수준에 머물렀다 [Figure 1]. 신뢰성 지표인 Pass^3 역시 최고 모델에서 28.0%로 나타나, 현존하는 에이전트 기술이 임상 현장에 자율적으로 투입되기에는 높은 성능 격차가 존재함을 확인했다. 오차 분석 결과, 가장 빈번한 실패 원인은 임상 추론 과정(Clinical Reasoning)에서의 오류로 나타났다 [Table 4].
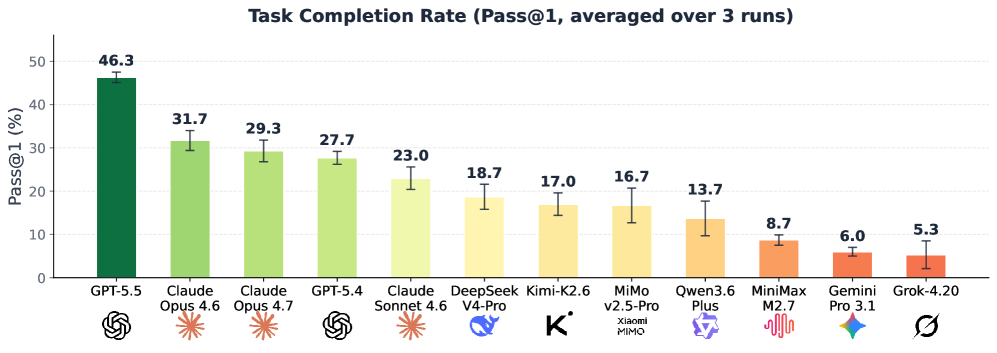
Figure 1 — 모델별 성공률 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 실제 임상 워크플로우에 기반한 실행 중심의 벤치마크를 제공함으로써 자율적 임상 에이전트 개발을 위한 정량적 이정표를 제시하였다. 연구 결과는 현재의 LLM 에이전트가 단편적인 임상 지식에는 능숙하나, 실제 EHR 환경에서 데이터를 통합하고 안전하고 일관된 임상 행동을 생성하는 데에는 여전히 상당한 개선이 필요함을 시사한다. 이 벤치마크는 향후 의료 현장에서 의사의 번아웃을 경감하고 효율적인 의사결정을 지원하는 임상 에이전트의 발전 속도를 가속화하는 핵심 도구로 활용될 것이다.
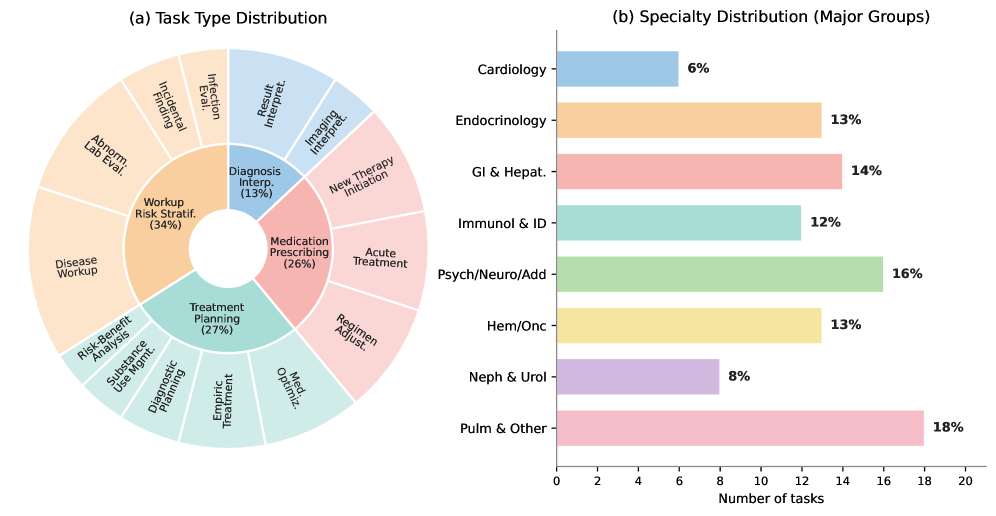
Figure 3 — 작업 유형 분포
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] PACE: A Proxy for Agentic Capability Evaluation
- [논문리뷰] Managing Procedural Memory in LLM Agents: Control, Adaptation, and Evaluation
- [논문리뷰] CoffeeBench: Benchmarking Long-Horizon LLM Agents in Heterogeneous Multi-Agent Economies
- [논문리뷰] Beyond Static Leaderboards: Predictive Validity for the Evaluation of LLM Agents
- [논문리뷰] When Tools Fail: Benchmarking Dynamic Replanning and Anomaly Recovery in LLM Agents
Review 의 다른글
- 이전글 [논문리뷰] Persistent Visual Memory: Sustaining Perception for Deep Generation in LVLMs
- 현재글 : [논문리뷰] PhysicianBench: Evaluating LLM Agents in Real-World EHR Environments
- 다음글 [논문리뷰] Repetition over Diversity: High-Signal Data Filtering for Sample-Efficient German Language Modeling
댓글