[논문리뷰] optimize_anything: A Universal API for Optimizing any Text Parameter
링크: 논문 PDF로 바로 열기
메타데이터
저자: Lakshya A Agrawal, Donghyun Lee, Shangyin Tan, Wenjie Ma, Karim Elmaaroufi, Rohit Sandadi, Sanjit A. Seshia, Koushik Sen, Dan Klein, Ion Stoica, Joseph E. Gonzalez, Omar Khattab, Alexandros G. Dimakis, Matei Zaharia
1. Key Terms & Definitions (핵심 용어 및 정의)
- Text Artifact:
optimize_anything에서 최적화 대상으로 삼는 모든 형태의 텍스트 기반 결과물(코드, 프롬프트, 에이전트 아키텍처, 구성 파일 등). - Side Information (SI): 모델이 제안한 후보(Candidate)의 성능 향상을 돕기 위해 평가 단계에서 제공되는 진단 정보(에러 로그, 성능 지표, 시각화 데이터 등).
- Pareto-Based Search: 단일 스칼라 점수 대신 다중 목표(Objective)를 고려하여 Pareto frontier를 유지함으로써, 여러 목표 간의 균형 잡힌 성능 향상을 도모하는 탐색 기법.
- Multi-Task Search: 여러 관련 작업을 동시에 최적화하여 작업 간의 최적화 패턴을 교차 전이(Cross-transfer)시키는 최적화 모드.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 최적화 문제를 텍스트 아키텍처 개선으로 정의하고, 이를 통해 다양한 도메인에서 범용적으로 작동하는 통합 최적화 시스템을 제안한다. 기존의 프로그램 진화(Program Evolution) 시스템인 AlphaEvolve나 FunSearch는 특정 도메인이나 코드 artifact에 한정되어 있으며, 단일 작업 최적화에 머무르는 한계가 있다. 또한, 다양한 최적화 요구사항(단일 작업, 다중 작업, 일반화 등)을 통합적으로 수행할 수 있는 인터페이스가 부족한 실정이다. 이러한 한계를 극복하기 위해 저자들은 optimize_anything이라는 선언적 API를 도입하여, 도메인별로 파편화된 최적화 파이프라인을 하나의 프레임워크로 통합하고자 한다 [Figure 1].
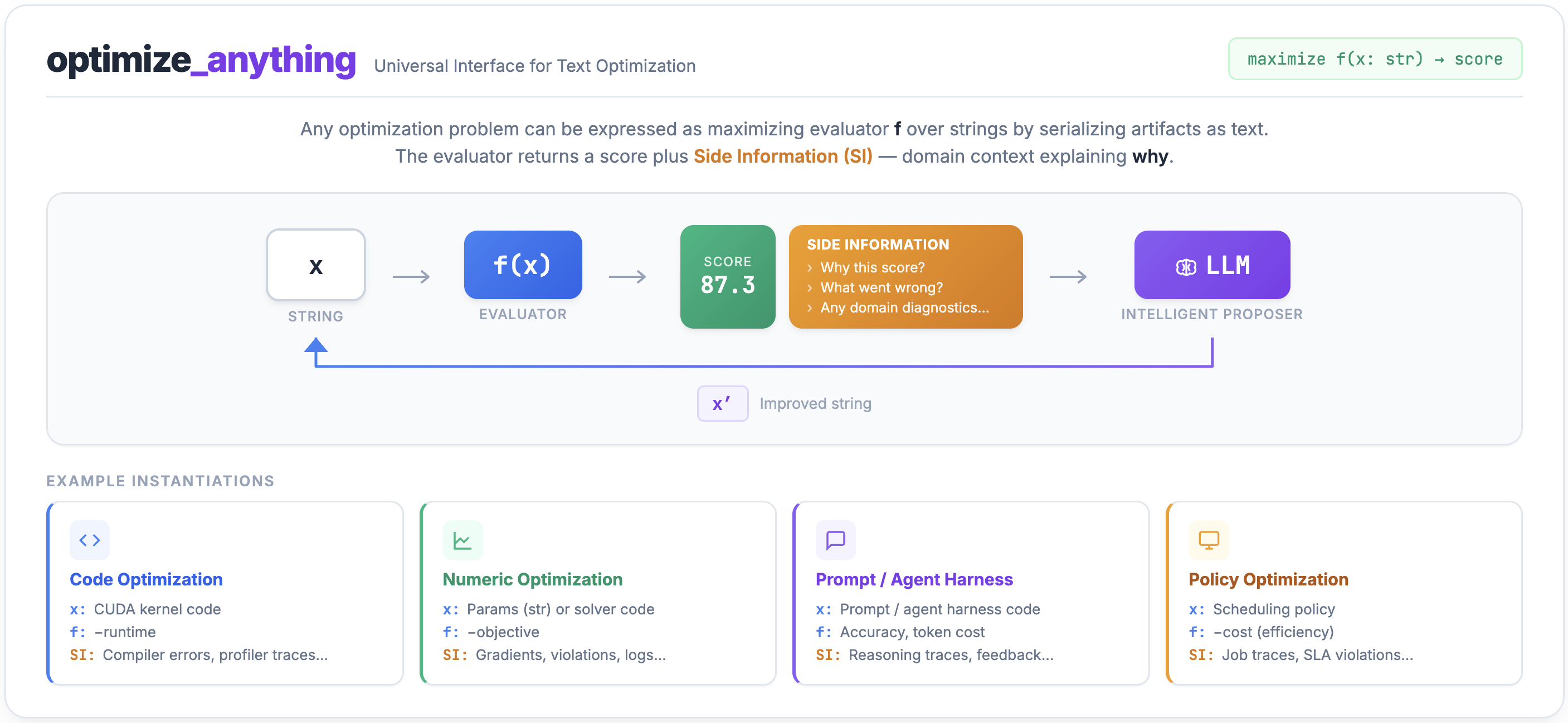
Figure 1 — optimize_anything 시스템 루프
3. Method & Key Results (제안 방법론 및 핵심 결과)
optimize_anything은 사용자가 seed artifact와 평가 함수(Evaluator)를 선언하면, 시스템이 알아서 제안(Proposal), 평가, 반영(Reflection) 단계를 거쳐 artifact를 반복적으로 개선하는 구조를 갖는다. 핵심적인 방법론으로 Side Information (SI)을 API 계약의 일환으로 격상하여, 단순한 점수 피드백을 넘어 상세한 진단 정보를 Proposer에게 전달한다 [Figure 1]. 또한, 단일 작업(Single-task), 다중 작업(Multi-task), 일반화(Generalization)의 3가지 모드를 통합하여 지원하며, Pareto-based search를 통해 탐색 효율을 극대화한다.
주요 실험 결과, ARC-AGI 과제에서 제안된 에이전트 아키텍처는 Gemini Flash 대비 정확도를 32.5%에서 89.5%로 대폭 향상시켰다 [Figure 4]. 클라우드 비용 절감 알고리즘인 CloudCast는 Dijkstra 대비 40.2%의 비용 절감 효과를 보였으며 [Figure 3], CUDA 커널 생성 실험에서는 87%의 결과물이 PyTorch 베이스라인을 능가하는 성능을 기록했다 [Figure 6]. 또한, SI를 활용했을 때 점수 기반 피드백 대비 4~6배 빠른 수렴 속도를 보이며, 최종 성능 또한 현저하게 높음을 확인하였다 [Figure 9].
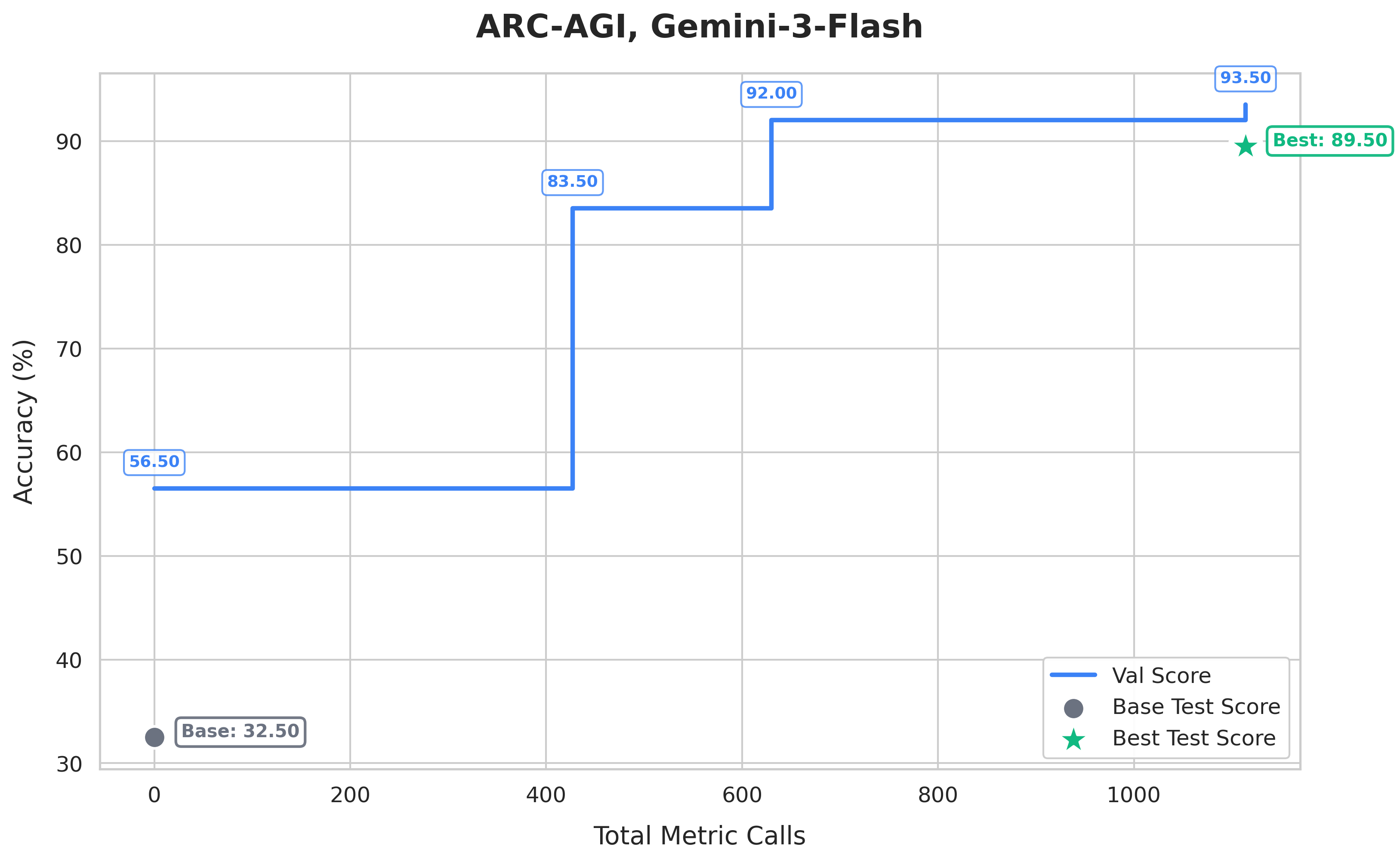
Figure 4 — ARC-AGI 에이전트 성능 변화
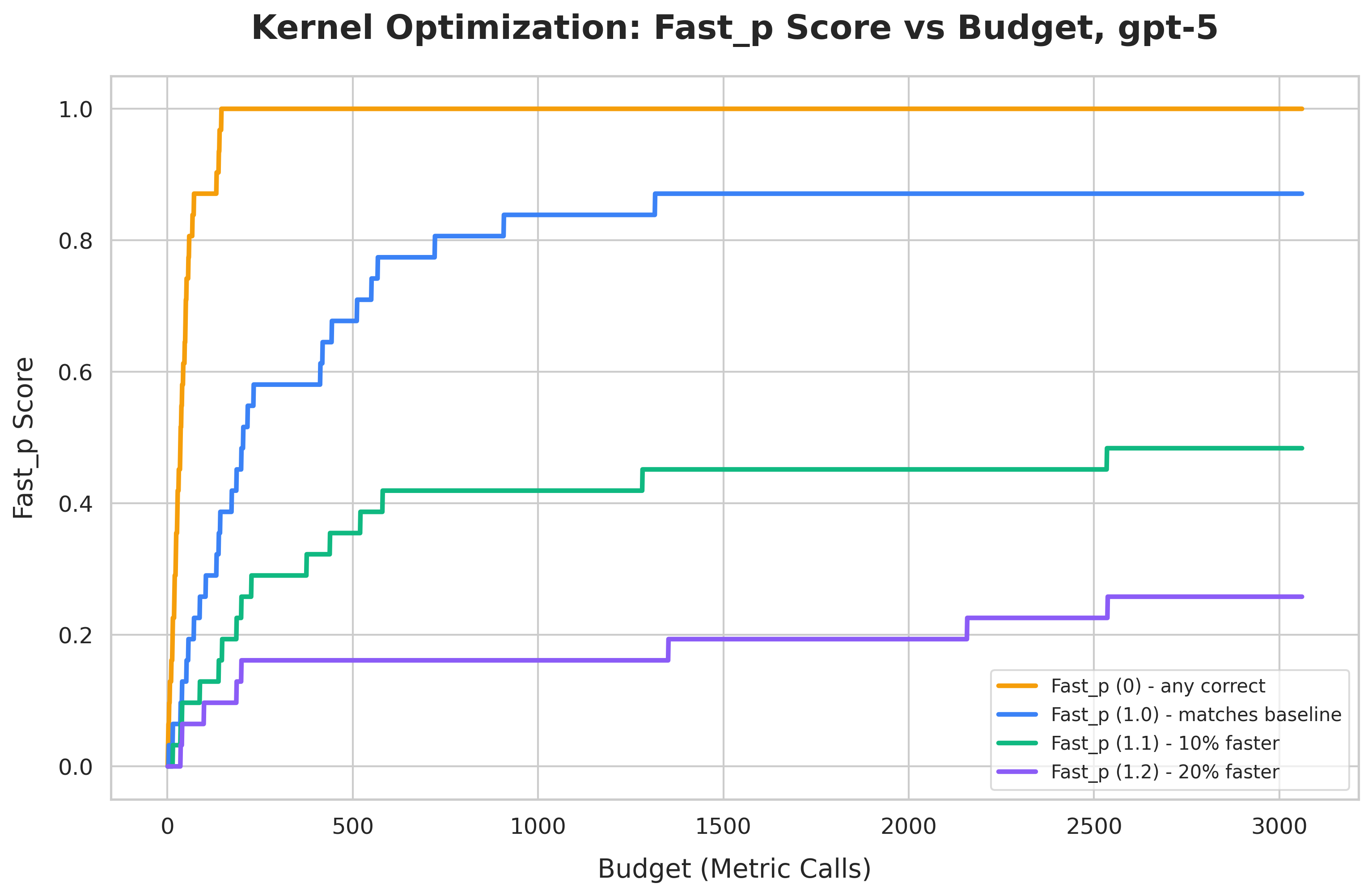
Figure 6 — CUDA 커널 생성 성능 결과
4. Conclusion & Impact (결론 및 시사점)
본 연구는 선언적 API 기반의 텍스트 최적화가 도메인 특화 알고리즘을 능가할 수 있는 범용적인 문제 해결 패러다임임을 성공적으로 입증하였다. 특히, 에이전트 아키텍처부터 수치 계산 커널까지 폭넓은 artifact를 하나의 시스템으로 최적화할 수 있음을 보였다는 점에서 학계 및 산업계에 큰 시사점을 준다. 이 연구는 최적화 과정에서의 도메인 지식 의존도를 낮추고, 시스템적인 진단 루프를 도입함으로써 AI 에이전트 및 시스템 연구의 새로운 방법론적 기반을 마련하였다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] xHC: Expanded Hyper-Connections
- [논문리뷰] Xiaomi-Robotics-1: Scaling Vision-Language-Action Models with over 100K Hours of Real-World Trajectories
- [논문리뷰] When Does Muon Help Agentic Reinforcement Learning?
- [논문리뷰] VideoRAE: Taming Video Foundation Models for Generative Modeling via Representation Autoencoders
Review 의 다른글
- 이전글 [논문리뷰] Where Does Authorship Signal Emerge in Encoder-Based Language Models?
- 현재글 : [논문리뷰] optimize_anything: A Universal API for Optimizing any Text Parameter
- 다음글 [논문리뷰] A Survey of Large Audio Language Models: Generalization, Trustworthiness, and Outlook
댓글