[논문리뷰] LongMINT: Evaluating Memory under Multi-Target Interference in Long-Horizon Agent Systems
링크: 논문 PDF로 바로 열기
메타데이터
저자: Hyunji Lee, Justin Chih-Yao Chen, Joykirat Singh, Zaid Khan, Elias Stengel-Eskin, Mohit Bansal
1. Key Terms & Definitions (핵심 용어 및 정의)
- MINTEval: Long-horizon 상황에서 발생하는 정보를 처리하는 memory-augmented agent의 성능을 평가하기 위해 제안된 분석적 벤치마크.
- Interference: 과거의 기억이 새로운 정보의 인코딩을 방해하는 proactive interference와, 새로운 정보가 기존의 기억을 수정하거나 삭제하는 retroactive interference를 모두 포함하는 개념.
- Multi-Target Aggregation: 여러 시점에 걸쳐 분산된 정보를 식별하고, 이를 통합하여 추론을 수행해야 하는 고난도 질의 유형.
- Long-range Lookback: 최근 상태가 아닌, 인터랙션 기록의 훨씬 이전 시점의 정보에 대한 질의를 수행하는 능력.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현재의 memory-augmented agent들이 현실 세계의 복잡하고 진화하는 long-horizon 환경에서 겪는 기억 오류 문제를 해결하고자 한다. 기존 벤치마크는 주로 정적이거나 독립적인 사건에 치중되어 있어, 실세계의 dense하고 상호 연결된 인터랙션이 야기하는 지속적인 정보 간섭을 충분히 포착하지 못한다 [Figure 1]. 저자들은 기존 모델들이 단순한 정보 덧붙이기에는 익숙하지만, 과거 기억의 수정이나 삭제, 그리고 시점 간의 충돌 해결에는 취약함을 지적한다. 이러한 한계로 인해 기존 연구들은 진정한 의미의 memory 효율성과 장기 기억의 일관성을 검증하는 데 실패하고 있다 [Table 1].
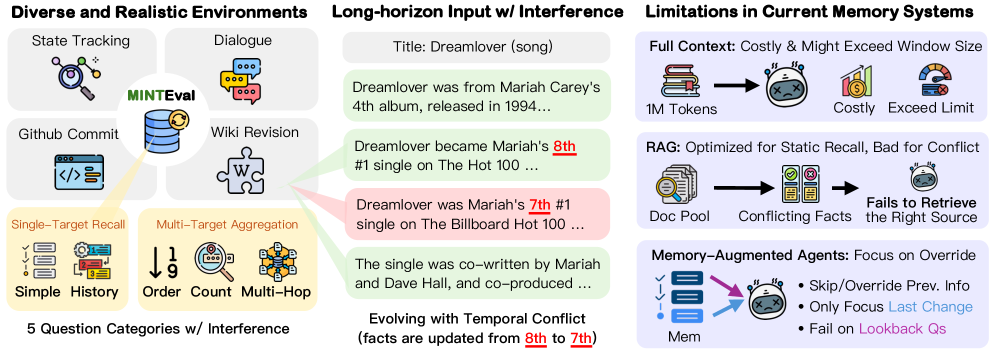
Figure 1 — MINTEval 벤치마크 개요 및 모델 실패 유형
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 State Tracking, Multi-turn Dialogue, Wikipedia Revisions, GitHub Commits 등 4개 영역에 걸쳐 15.6k개의 질의 쌍을 포함하는 MINTEval 벤치마크를 구축하였다 [Figure 1]. 본 연구는 vanilla long-context LLM, RAG 프레임워크, 그리고 MemAgent, AtomMem, Mem-α, SimpleMem과 같은 최신 memory-augmented agent 시스템들을 평가하였다. 실험 결과, 모든 시스템의 평균 정확도는 27.9%로, 가장 뛰어난 성능을 보인 MemAgent조차 33.4%에 그쳐 해당 분야의 난이도가 매우 높음을 확인하였다 [Table 4]. 분석 결과, 주요 병목 현상은 retrieval 및 memory construction 단계에 집중되어 있으며, 전체 오류의 41.7%가 이 단계에서 발생함이 밝혀졌다 [Figure 2]. 또한, lookback 거리가 멀어질수록 성능이 급격히 저하되나, 명시적인 temporal marker를 추가할 경우 성능 하락이 완화됨을 입증하였다 [Figure 3].
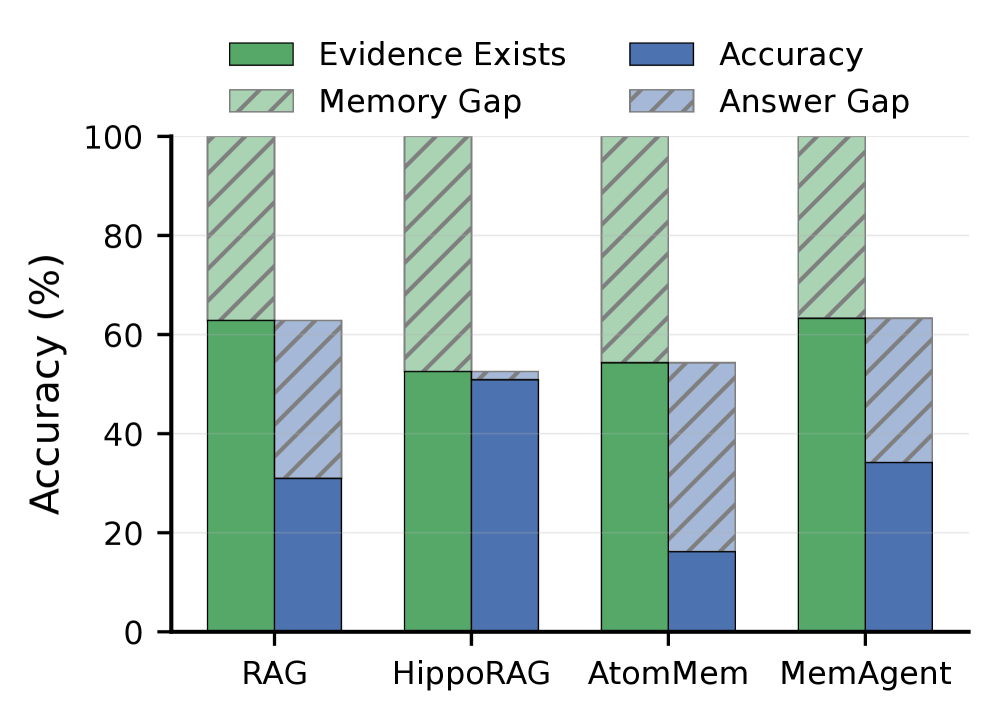
Figure 2 — 성능 저하 요인 분석 (메모리 구조 오류)
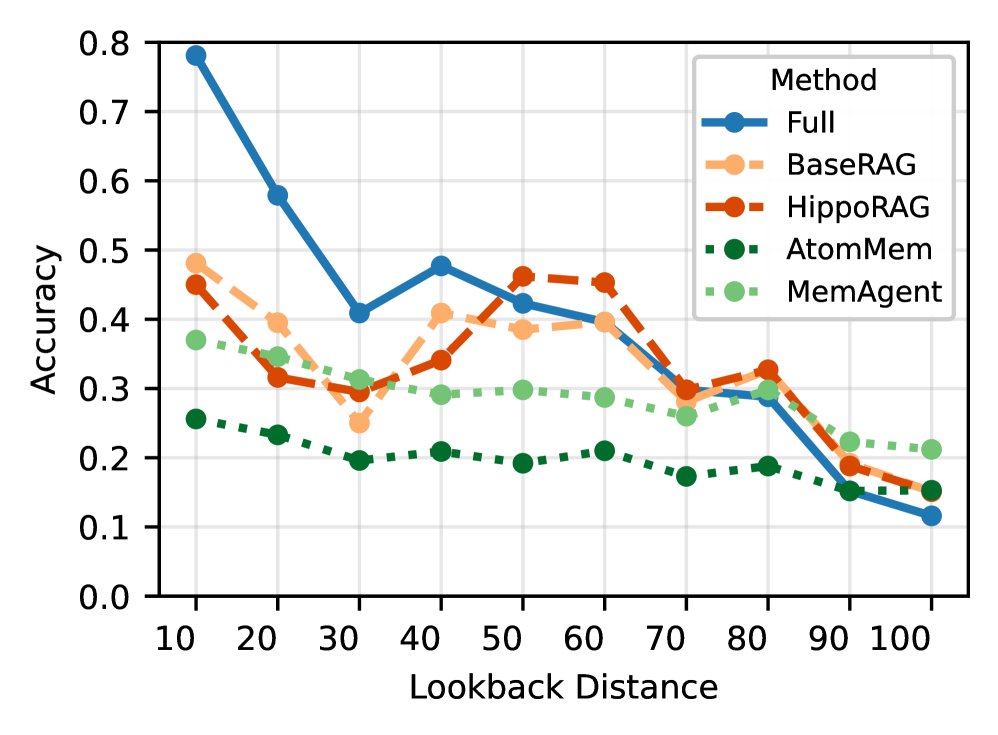
Figure 3 — Lookback 거리에 따른 정확도 변화
4. Conclusion & Impact (결론 및 시사점)
본 연구는 MINTEval을 통해 memory-augmented agent가 실세계의 복잡한 정보 간섭 환경에서 여전히 상당한 한계를 가지고 있음을 입증하였다. 이 연구는 학계에 memory 시스템이 단순히 정보를 축적하는 것을 넘어, 수정(update) 및 삭제(deletion)를 포함한 정교한 제어 능력이 필요함을 시사한다. 특히 aggregation 기반의 추론 능력 향상이 향후 차세대 agent 시스템 개발의 핵심 과제가 될 것으로 보인다. 본 벤치마크는 더 강력한 long-horizon 기억 및 추론 모델을 개발하기 위한 중요한 이정표가 될 것이다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] WildGraphBench: Benchmarking GraphRAG with Wild-Source Corpora
- [논문리뷰] BuildBench: Benchmarking LLM Agents on Compiling Real-World Open-Source Software
- [논문리뷰] Vinci2: Providing Proactive Assistance in Continuous Egocentric Videos
- [논문리뷰] AgentCompass: A Unified Evaluation Infrastructure for Agent Capabilities
- [논문리뷰] Blind-Spots-Bench: Evaluating Blind Spots in Multimodal Models
Review 의 다른글
- 이전글 [논문리뷰] Learn-by-Wire Training Control Governance: Bounded Autonomous Training Under Stress for Stability and Efficiency
- 현재글 : [논문리뷰] LongMINT: Evaluating Memory under Multi-Target Interference in Long-Horizon Agent Systems
- 다음글 [논문리뷰] MOCHA: Multi-Objective Chebyshev Annealing for Agent Skill Optimization
댓글