[논문리뷰] Mega-ASR: Towards In-the-wild^2 Speech Recognition via Scaling up Real-world Acoustic Simulation
링크: 논문 PDF로 바로 열기
저자: Zhifei Xie, Kaiyu Pang, Haobin Zhang, Deheng Ye, Xiaobin Hu, Shuicheng Yan, Chunyan Miao
1. Key Terms & Definitions (핵심 용어 및 정의)
- Mega-ASR: 복합적인 실제 환경에서의 음성 인식을 향상하기 위해 제안된 통합 프레임워크로, Acoustic-to-Semantic Progressive Supervised Fine-Tuning 및 Dual-Granularity WER-Gated Policy Optimization을 포함함.
- Voices-in-the-wild-2M: 7개의 정형화된 음향 현상과 54개의 물리적으로 타당한 복합 시나리오를 포괄하는 대규모 음성 인식 데이터셋.
- A2S-SFT: 음향 신호로부터의 의미 추출과 의미적 재구성을 단계적으로 학습시켜, 고도로 왜곡된 신호에서의 인식을 강화하는 fine-tuning 기법.
- DG-WGPO: WER 기반 보상의 한계를 극복하기 위해 제안된 Dual-Granularity Dynamic Reward 체계로, 토큰 단위의 정교화 보상과 문장 단위의 구조적 재구성 보상을 동적으로 결합함.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 ASR 기술이 깨끗한 환경에서는 뛰어난 성능을 보이지만, 실제 환경의 복합적인 음향 왜곡(noise, reverberation, far-field, obstruction 등) 속에서는 WER이 급격히 상승하고 할루시네이션(hallucination)이나 문장 누락이 발생하는 'acoustic robustness bottleneck'을 해결하고자 한다. 기존 연구들은 주로 단일 환경 요인에 집중하여 실제 환경의 복합적 특성을 반영하지 못하며, 훈련 데이터와 실제 환경 간의 분포 불일치가 존재한다. 따라서 본 연구는 이러한 환경을 견고하게 처리할 수 있는 스케일러블한 데이터셋과 학습 패러다임이 필요하다는 점을 명시한다 [Figure 2].

Figure 2 — Voices-in-the-wild-2M 데이터셋 구성 방식
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 대규모 데이터셋 Voices-in-the-wild-2M을 구축하여 복합 음향 시나리오를 체계적으로 시뮬레이션하고, A2S-SFT를 통해 모델의 음향 인식을 단계적으로 강화한 후 DG-WGPO를 도입하여 강화학습을 수행한다. DG-WGPO는 특히 WER이 30%를 초과하는 고난도 환경에서 고정된 WER 보상이 효과적이지 않음을 인지하고, 토큰 단위와 문장 단위 보상을 동적으로 조절하는 WER-gated fusion 전략을 취한다 [Figure 4]. 실험 결과, Mega-ASR은 복합 환경 벤치마크인 Voices-in-the-Wild-Bench에서 기존 모델 대비 30% 이상의 상대적 WER 감소를 기록했다. 또한, NOIZEUS Sta-0 벤치마크에서는 21.49%의 WER로 최신 모델들(29.34%) 대비 우수한 성능을 보였으며, 일반적인 깨끗한 음성 인식 성능은 유지하면서 견고성을 비약적으로 향상했다 [Table 4].
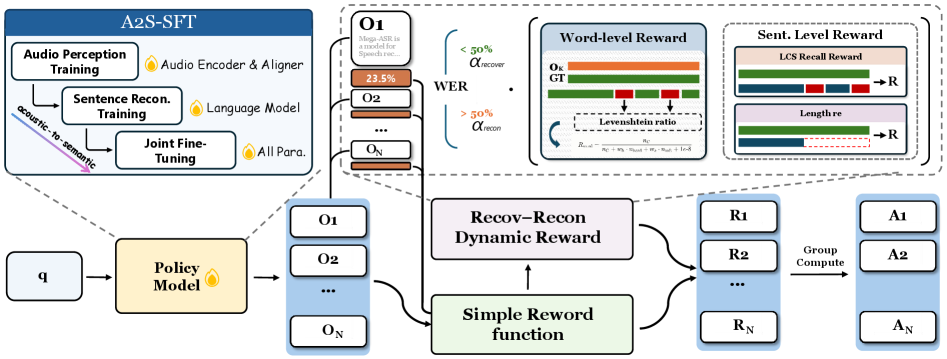
Figure 4 — DG-WGPO 프레임워크 개요
4. Conclusion & Impact (결론 및 시사점)
본 논문은 음성 인식 분야의 고질적인 문제인 복합적 왜곡 환경에서의 강인성 문제를 해결하기 위한 통합적이고 스케일러블한 프레임워크를 성공적으로 구축하였다. Voices-in-the-wild-2M 데이터셋과 DG-WGPO 기법은 복잡한 실제 환경에서도 문장의 의미론적 구조를 보존하고 할루시네이션을 최소화하는 새로운 표준을 제시한다. 이 연구는 산업계의 ASR 모델이 복합 음향 조건에서 인간 수준의 성능을 발휘하도록 견인하는 실질적인 시사점을 제공하며, 향후 음성 인식 분야의 robust deployment 기술 발전에 크게 기여할 것으로 기대된다.
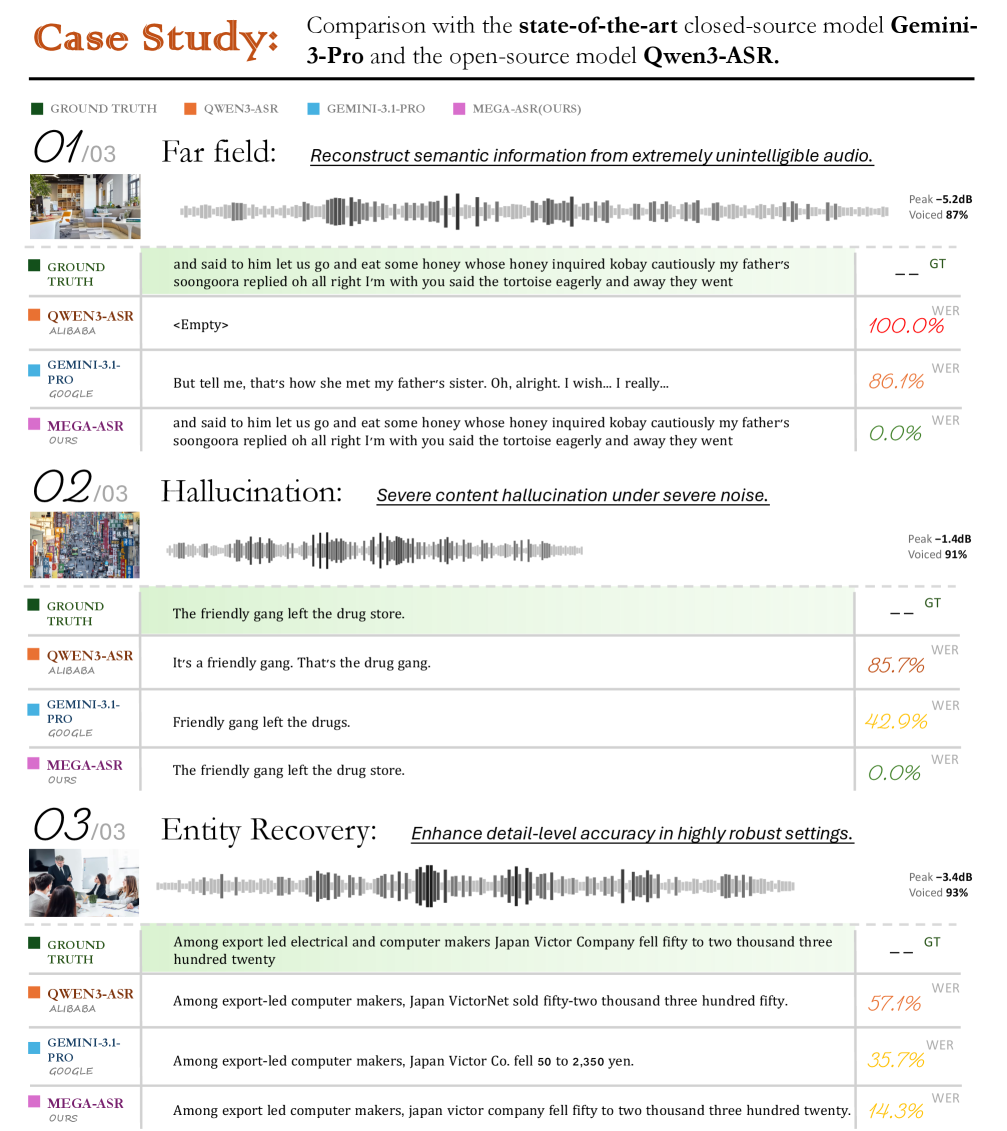
Figure 6 — 모델 성능 정성적 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] TREK: Distill to Explore, Reinforce to Refine
- [논문리뷰] The Mirage of Optimizing Training Policies: Monotonic Inference Policies as the Real Objective for LLM Reinforcement Learning
- [논문리뷰] EvoPolicyGym: Evaluating Autonomous Policy Evolution in Interactive Environments
- [논문리뷰] Denser neq Better: Limits of On-Policy Self-Distillation for Continual Post-Training
- [논문리뷰] MobileForge: Annotation-Free Adaptation for Mobile GUI Agents with Hierarchical Feedback-Guided Policy Optimization
Review 의 다른글
- 이전글 [논문리뷰] MOCHA: Multi-Objective Chebyshev Annealing for Agent Skill Optimization
- 현재글 : [논문리뷰] Mega-ASR: Towards In-the-wild^2 Speech Recognition via Scaling up Real-world Acoustic Simulation
- 다음글 [논문리뷰] Mem-π: Adaptive Memory through Learning When and What to Generate
댓글