[논문리뷰] OCTOPUS: Optimized KV Cache for Transformers via Octahedral Parametrization Under optimal Squared error quantization
링크: 논문 PDF로 바로 열기
본 논문은 Long-context autoregressive inference에서 메모리 대역폭과 비용을 지배하는 KV cache 문제를 해결하기 위해, 팔면체 파라미터화를 활용한 새로운 압축 기법 OCTOPUS를 제안한다.
1. Key Terms & Definitions (핵심 용어 및 정의)
- KV Cache: Transformer 모델이 긴 문맥을 생성할 때 이전 토큰의 Key와 Value 상태를 저장하는 메모리 영역으로, 추론 속도와 메모리 사용량의 병목 지점이다.
- Octahedral Parametrization: 3차원 단위 벡터(S2)를 두 개의 스칼라 값으로 투영하는 매핑 기법으로, 압축 효율이 높고 데이터-오블리비언트(data-oblivious) 특성을 가진다.
- WHT (Walsh-Hadamard Transform): 입력 벡터의 엔트로피를 좌표 간에 균등하게 분산시키는 회전 프리컨디셔닝 기법으로, 양자화 효율을 극대화한다.
- Lloyd-Max Quantizer: 각 좌표의 마지널(marginal) 분포에 최적화된 비균등 양자화 방식으로, 압축 왜곡(MSE)을 최소화하는 전통적인 기법이다.
- QJL (Quantized Johnson-Lindenstrauss): 1비트 부호 스케치(sign sketch)를 통해 내적 결과의 편향(bias)을 제거하는 경량 잔차 추정 기법이다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Long-context 모델의 확장에 따라 KV cache의 메모리 점유율은 모델 서빙의 핵심적인 기술적 과제가 되었다. 기존의 rotation-preconditioned 방식인 TurboQuant와 PolarQuant는 1차원적인 좌표 기반 양자화에 의존하여 정보 손실이 발생하거나 높은 압축률에서 성능이 급격히 저하되는 한계가 있다. 이러한 방식들은 데이터의 통계적 특성을 충분히 활용하지 못하며, 특히 extreme compression 시 정확도 보존이 어렵다는 문제가 있다. 본 논문은 이러한 한계를 극복하기 위해 좌표 triplet을 공동으로 양자화하여 왜곡을 최소화하는 구조적 접근 방식을 제시한다 [Figure 1].
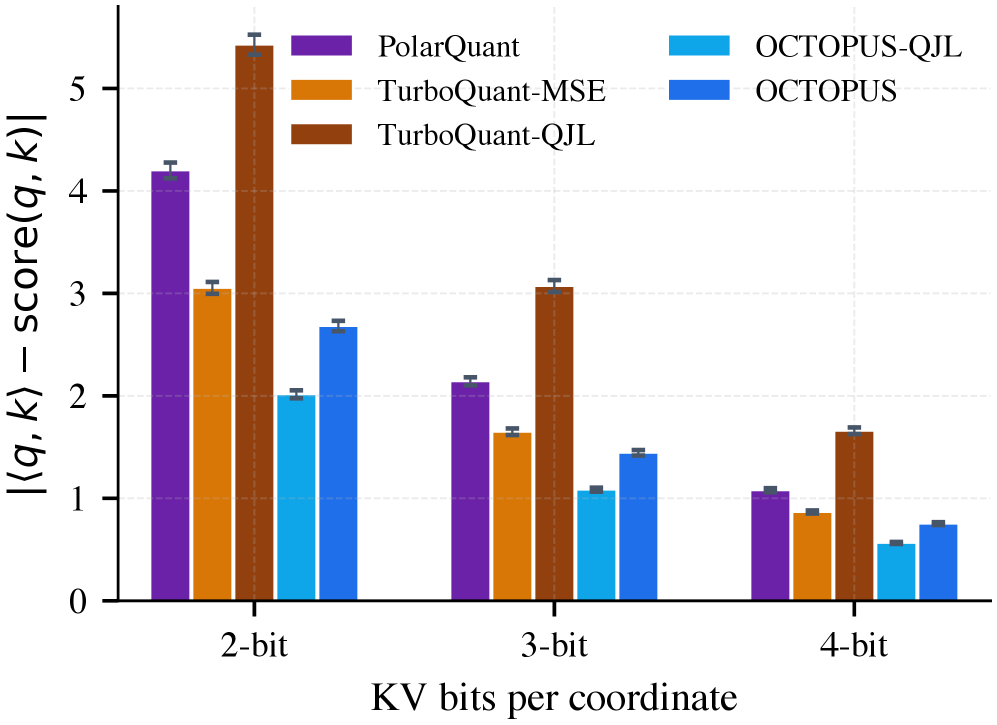
Figure 1 — OCTOPUS 인코딩 파이프라인
3. Method & Key Results (제안 방법론 및 핵심 결과)
OCTOPUS는 회전된 Key 벡터를 3개씩 묶은 triplet으로 분할하고, 이를 노름(norm)과 팔면체로 매핑된 방향성으로 각각 분리하여 양자화한다. 저자들은 라그랑주 승수를 사용하여 MSE-optimal 비트 할당을 유도하였으며, 실험을 통해 (b+1, b-1) 비트 분할 전략이 가장 우수한 성능을 보임을 확인하였다 [Figure 1]. 이는 방향 성분에 더 많은 비트를 할당함으로써 노름의 왜곡을 보완하는 구조이다.
주요 실험 결과는 다음과 같다:
- Synthetic fidelity: OCTOPUS는 TurboQuant 및 PolarQuant 대비 b=4 비트에서 1.3배, b=2 비트에서 2.4배 낮은 MSE를 기록하며 가장 우수한 복원 성능을 보였다 [Table 1].
- Long-context LM: Qwen2.5-7B-Instruct-1M 모델 기준, b=2 비트 상황에서 경쟁 모델들이 PPL(Perplexity) 측면에서 붕괴할 때도 OCTOPUS는 상대적으로 견고한 성능을 유지하였다 [Table 2].
- Needle-in-a-haystack: b=2 비트의 극한 환경에서 OCTOPUS는 81%의 recall을 달성하여, 거의 모든 성능을 상실하는 타 방식 대비 압도적인 우위를 점하였다 [Figure 3].
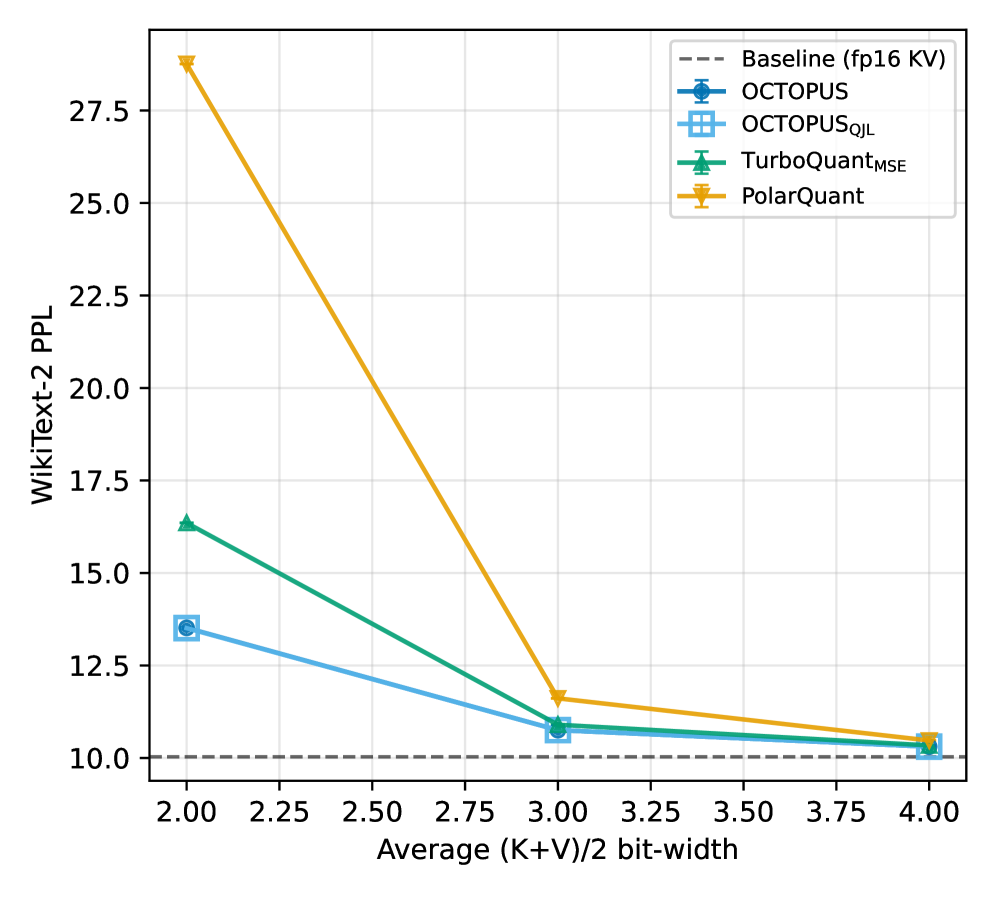
Figure 3 — Qwen2.5 추론 성능 및 recall
4. Conclusion & Impact (결론 및 시사점)
본 연구는 OCTOPUS를 통해 데이터 오블리비언트한 KV cache 압축 분야에서 새로운 SOTA(State-of-the-Art)를 수립하였다. 팔면체 투영을 통해 효율적으로 방향 정보를 캡처하고, 최적화된 비트 할당을 통해 저비트 환경에서도 정보 손실을 최소화하는 능력을 입증하였다. 이 연구는 LLM뿐만 아니라 비디오, 오디오와 같은 다양한 생성형 모델의 추론 성능을 향상시키는 데 기여하며, 특히 메모리 제약이 심한 환경에서 긴 문맥을 처리하기 위한 필수적인 프레임워크로 평가받는다.
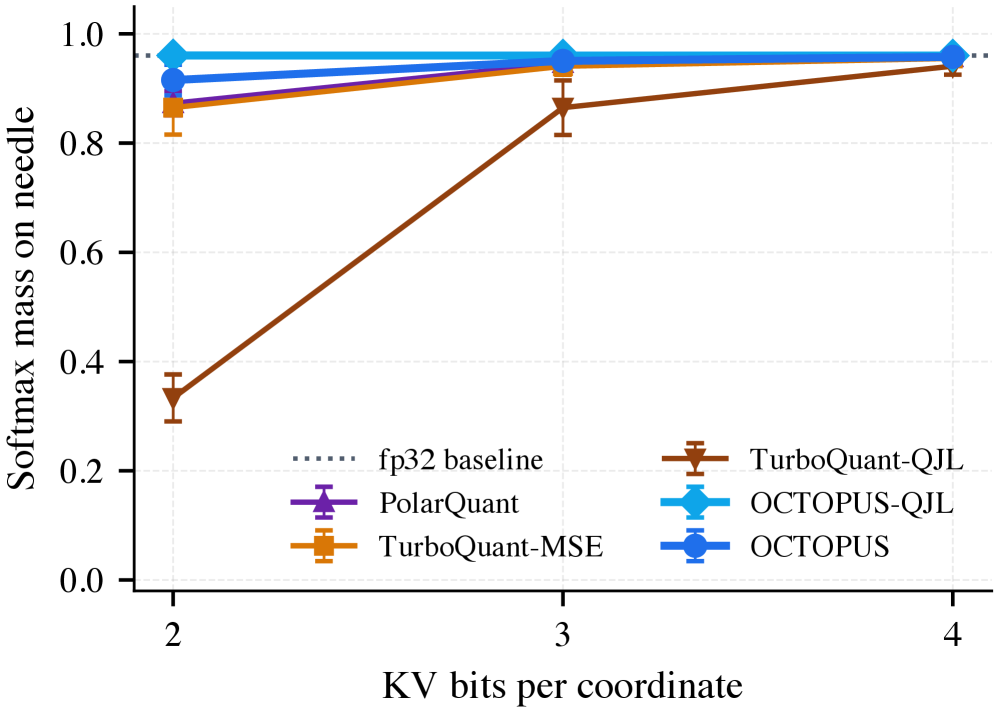
Figure 2 — 합성 데이터 복원 정확도
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] xHC: Expanded Hyper-Connections
- [논문리뷰] Xiaomi-Robotics-1: Scaling Vision-Language-Action Models with over 100K Hours of Real-World Trajectories
- [논문리뷰] When Does Muon Help Agentic Reinforcement Learning?
- [논문리뷰] VideoRAE: Taming Video Foundation Models for Generative Modeling via Representation Autoencoders
Review 의 다른글
- 이전글 [논문리뷰] Mix-Quant: Quantized Prefilling, Precise Decoding for Agentic LLMs
- 현재글 : [논문리뷰] OCTOPUS: Optimized KV Cache for Transformers via Octahedral Parametrization Under optimal Squared error quantization
- 다음글 [논문리뷰] OScaR: The Occam's Razor for Extreme KV Cache Quantization in LLMs and Beyond
댓글