[논문리뷰] On the limits and opportunities of AI reviewers: Reviewing the reviews of Nature-family papers with 45 expert scientists
링크: 논문 PDF로 바로 열기
저자: Seungone Kim, Dongkeun Yoon, Kiril Gashteovski, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- AI Reviewers: 연구 논문의 원고를 평가하기 위해
LLM기반으로 설계된 자율 에이전트 시스템입니다. - Review Item: 논문의 특정 측면을 다루는 개별적인 원자적 비판 단위입니다.
- Fully Positive: 전문가 평가에서
Correct,Significant,Evidence-Sufficient라는 세 가지 품질 지표를 모두 만족한 리뷰 아이템을 의미합니다. - PEERREVIEW BENCH: 본 연구에서 개발한 자동 평가 벤치마크로, AI 리뷰어의 성능을
Correctness,Significance,Evidence Sufficiency기준으로 측정합니다. - OpenHands: 논문 리뷰 에이전트를 구현하기 위해 사용된 자율 소프트웨어 에이전트 SDK 프레임워크입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 급증하는 과학 연구 논문 생산량에 따른 피어 리뷰 시스템의 확장성 문제를 해결하기 위해 도입된 AI Reviewers의 역량과 신뢰성을 객관적으로 평가하는 것을 목표로 합니다. 기존의 평가 방식은 전반적인 점수 상관관계나 수락 여부와 같은 총체적(Aggregate) 지표에 의존하여, AI 리뷰어가 실제로 기술적인 정밀함(Technical Scrutiny)을 제공하는지 아니면 표면적인 의견을 생성하는지 판별하지 못하는 한계가 있었습니다. 이를 해결하기 위해 저자들은 45명의 분야별 전문가들이 82편의 Nature-family 논문을 대상으로 2,960개의 리뷰 아이템을 직접 검증하는 대규모 주석 연구를 수행하였습니다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 연구는 GPT-5.2, Claude Opus 4.5, Gemini 3.0 Pro와 같은 최첨단 언어 모델을 OpenHands 기반 에이전트로 배포하여 실제 과학 논문에 대한 피어 리뷰를 생성하고, 이를 도메인 전문가들이 주석 처리하도록 설계하였습니다. 주요 결과에 따르면, GPT-5.2는 Fully Positive 아이템 구성에서 60.0%의 성적을 기록하며 논문 당 최우수 인간 리뷰어(48.2%)를 유의미하게 상회했습니다 [Table 4]. 또한 모든 AI 모델은 모든 차원에서 최하위 인간 리뷰어보다 우수한 성과를 보였습니다 [Table 3]. 특히, AI 리뷰어는 Code Inspection, 통계적 가정 검증, 전문 문헌 교차 검증 등 인간 리뷰어가 바쁜 일정으로 생략하기 쉬운 루틴한 업무에서 탁월한 강점(Strengths)을 보였습니다 [Figure 5]. 반면, 하위 필드별 방법론적 관습을 이해하지 못하거나, 긴 논문의 맥락을 놓치는 등의 고유한 약점(Failure Modes) 또한 16가지로 식별되었습니다.
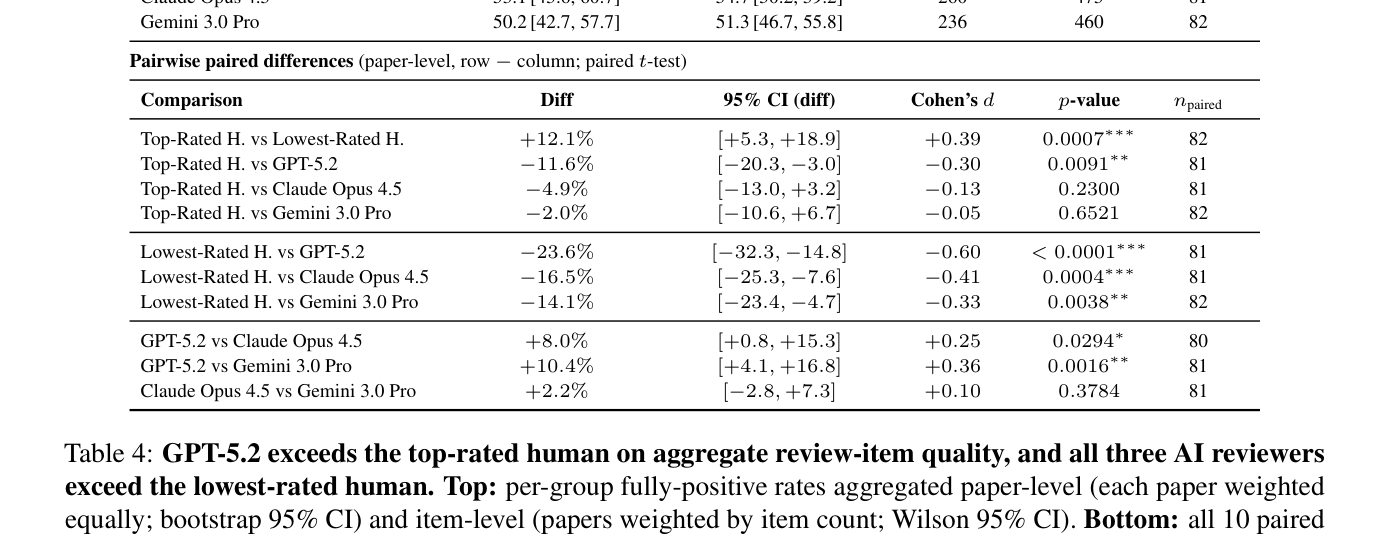
Table 4 — AI 모델별 Fully positive 성능 지표를 비교한 핵심 데이터 테이블입니다.
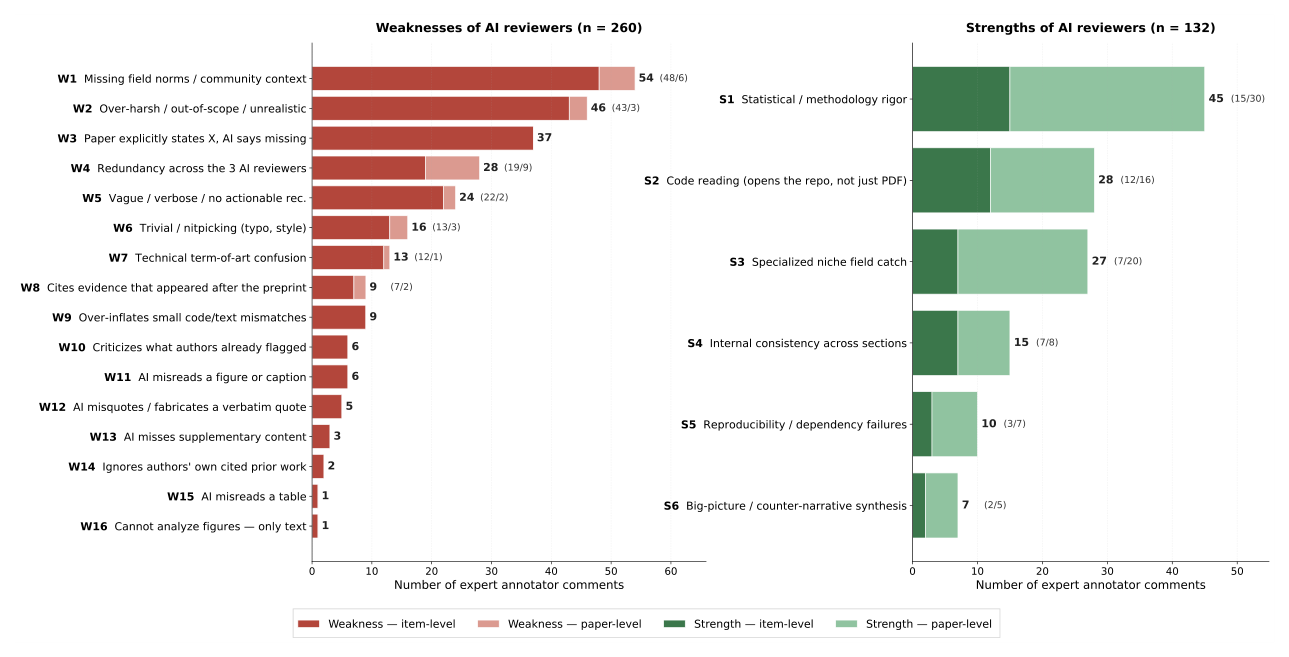
Figure 5 — AI 리뷰어의 주요 강점과 약점 유형을 카테고리별로 정량화하여 보여주는 그래프입니다.
## 4. Conclusion & Impact (결론 및 시사점)
본 연구의 결과는 현재의 AI 리뷰어가 인간 리뷰어를 완전히 대체하기보다는, 인간 리뷰어의 전문성을 보완하는 강력한 협력 도구로 기능할 수 있음을 시사합니다. 저자들은 AI 리뷰어의 활용을 위해 2H+1AI와 같은 패널 구성을 제안하며, 이를 통해 인간 전문가가 수동으로 관리해야 할 업무량을 획기적으로 줄일 수 있음을 증명했습니다. 결과적으로 본 연구가 제시한 PEERREVIEW BENCH와 CMU PAPER REVIEWER는 학계의 리뷰 프로세스 효율성을 높이고, 더 건설적이고 증거 기반의 연구 피드백을 제공하는 데 기여할 것으로 기대됩니다.
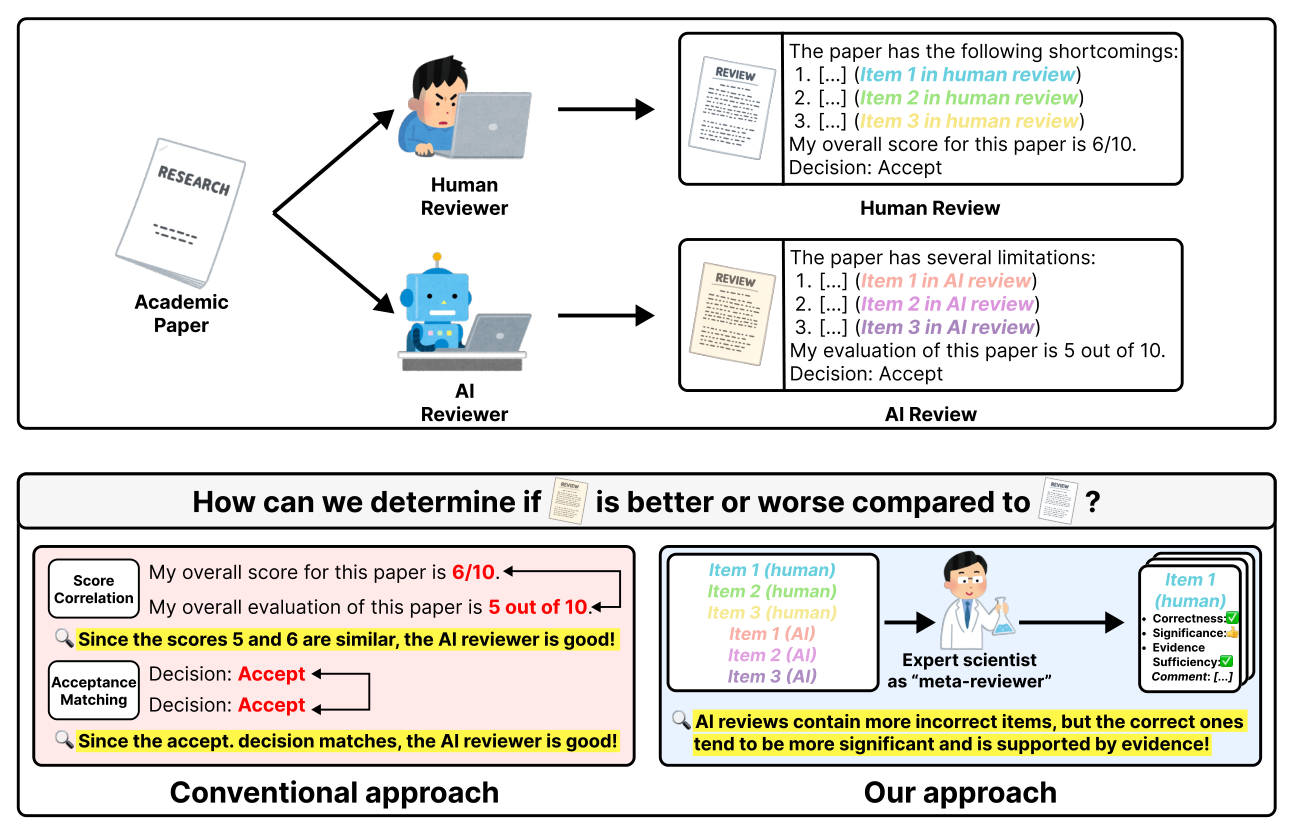
Figure 1 — AI 리뷰어의 기존 평가 방식(Conventional)과 본 연구의 새로운 평가 방식(Our approach)을 대비시킨 핵심 도식입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Paper2Rebuttal: A Multi-Agent Framework for Transparent Author Response Assistance
- [논문리뷰] ReviewerToo: Should AI Join The Program Committee? A Look At The Future of Peer Review
- [논문리뷰] Tracing Agentic Failure from the Flow of Success
- [논문리뷰] Automating the Design of Embodied Agent Architectures
- [논문리뷰] When Classic Cache Policies Fail: Learning-Augmented Replacement for Semantic Retrieval Buffers
Review 의 다른글
- 이전글 [논문리뷰] OcclusionFormer: Arranging Z-Order for Layout-Grounded Image Generation
- 현재글 : [논문리뷰] On the limits and opportunities of AI reviewers: Reviewing the reviews of Nature-family papers with 45 expert scientists
- 다음글 [논문리뷰] PanoWorld: A Generative Spatial World Model for Consistent Whole-House Panorama Synthesis
댓글