[논문리뷰] OmniPro: A Comprehensive Benchmark for Omni-Proactive Streaming Video Understanding
링크: 논문 PDF로 바로 열기
메타데이터
저자: Ruixiang Zhao, Jie Yang, Zijie Xin, Tianyi Wang, Fengyun Rao, Jing LYU, Xirong Li
1. Key Terms & Definitions (핵심 용어 및 정의)
- Omni-proactive streaming video understanding: 지속적인 오디오-비주얼 스트림을 처리하며 모델이 자율적으로 발화 시점과 내용을 결정하는 상호작용 능력을 의미합니다.
- Probe mode: 스트리밍 능력이 없는 VLM도 평가 가능한 방식으로, 각 Ground-truth 시점 전후로 모델을 쿼리하여 콘텐츠 이해도를 측정합니다.
- Online mode: 모델이 비디오 스트림을 실시간으로 입력받아 자율적으로 반응 시점을 결정하는 실제 Proactive 능력을 평가합니다.
- Modality-isolation labels: 데이터의 각 샘플이 시각, 음성, 비언어적 소리 등 어떤 모달리티에 의존하는지 명시한 레이블로, 모달리티별 기여도 분석(ablation)을 가능하게 합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Omni-modal Large Language Models(MLLMs)의 발전에도 불구하고, 실제 환경에서의 Proactive 스트리밍 이해 능력을 정밀하게 평가할 수 있는 표준화된 벤치마크가 부재하다는 문제점을 해결하고자 합니다 [Figure 1]. 기존 벤치마크들은 비디오 신호에 지나치게 의존하거나, 고정된 시간대의 폴링 방식을 사용하여 진정한 의미의 Proactive 반응을 측정하지 못하며, 평가 가능한 태스크 범위가 극히 제한적이라는 한계가 있습니다. 저자들은 이러한 평가 격차를 해소하기 위해 Omni-modal 인지, 자율적인 Proactive 반응, 그리고 9개 하위 태스크를 포함한 종합적인 비디오 이해 능력을 동시에 평가할 수 있는 통합 프레임워크인 OmniPro를 제안합니다.
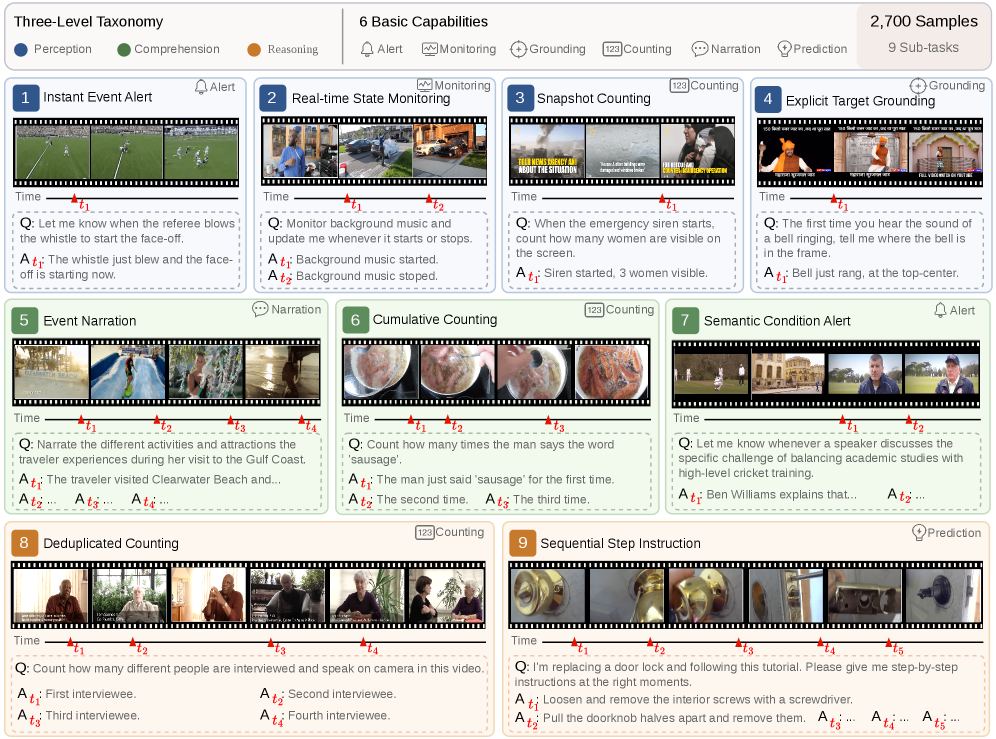
Figure 1 — OmniPro 전체 개요 및 태스크 분류
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 1,262개의 비디오에서 추출된 2,700개의 휴먼 검증 샘플로 구성된 OmniPro 벤치마크를 구축하였습니다 [Figure 1, 2]. 제안된 Probe 및 Online 이중 모드 프로토콜을 통해 11개 대표 모델을 평가한 결과, 다음과 같은 핵심 결과를 도출하였습니다.
- 오디오 정보는 모델 성능에 일관된 이득(+2.4~+11.1)을 제공하며, 특히 Event-Alert와 같은 태스크에서 오디오의 중요성이 극대화됨을 확인하였습니다 [Table 3].
- 모델들은 시간이 지남에 따라 성능이 크게 저하되는 경향을 보였으며, 장기적인 시간 의존성(Long-horizon) 모델링에 한계를 드러냈습니다 [Figure 3].
- 모든 모델이 비언어적 소리(Non-speech audio) 인식에서 가장 낮은 성능을 보였으며, 이는 향후 개선이 필요한 핵심 Bottleneck으로 확인되었습니다 [Figure 4].
- Proprietary 모델(Gemini-3-Flash)과 Open-source 모델 간의 성능 격차는 평균 정확도 기준 약 2배(40.4% vs 22.6%)에 달하며, 특히 복잡한 추론 태스크에서 그 차이가 더욱 두드러졌습니다 [Table 2].
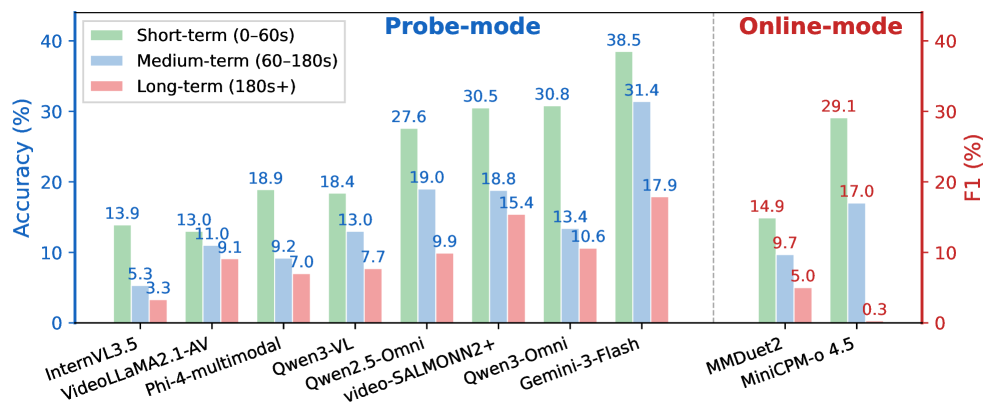
Figure 3 — 시간 경과에 따른 성능 저하(Long-horizon)
4. Conclusion & Impact (결론 및 시사점)
본 논문은 최초의 종합적인 Omni-proactive 스트리밍 비디오 이해 벤치마크인 OmniPro를 통해 해당 분야의 평가 표준을 확립하고, 현재 모델들의 강점과 한계를 객관적으로 식별하였습니다. 이 연구는 단순한 시각 중심의 이해를 넘어, 오디오-비주얼 결합 및 실시간 대응 능력을 갖춘 진정한 차세대 AI 어시스턴트 개발에 중요한 가이드라인을 제공합니다. 향후 본 연구는 모델의 Long-horizon robustness 향상 및 비언어적 청각 인지 능력 강화를 위한 핵심적인 연구 동력이 될 것으로 기대됩니다.
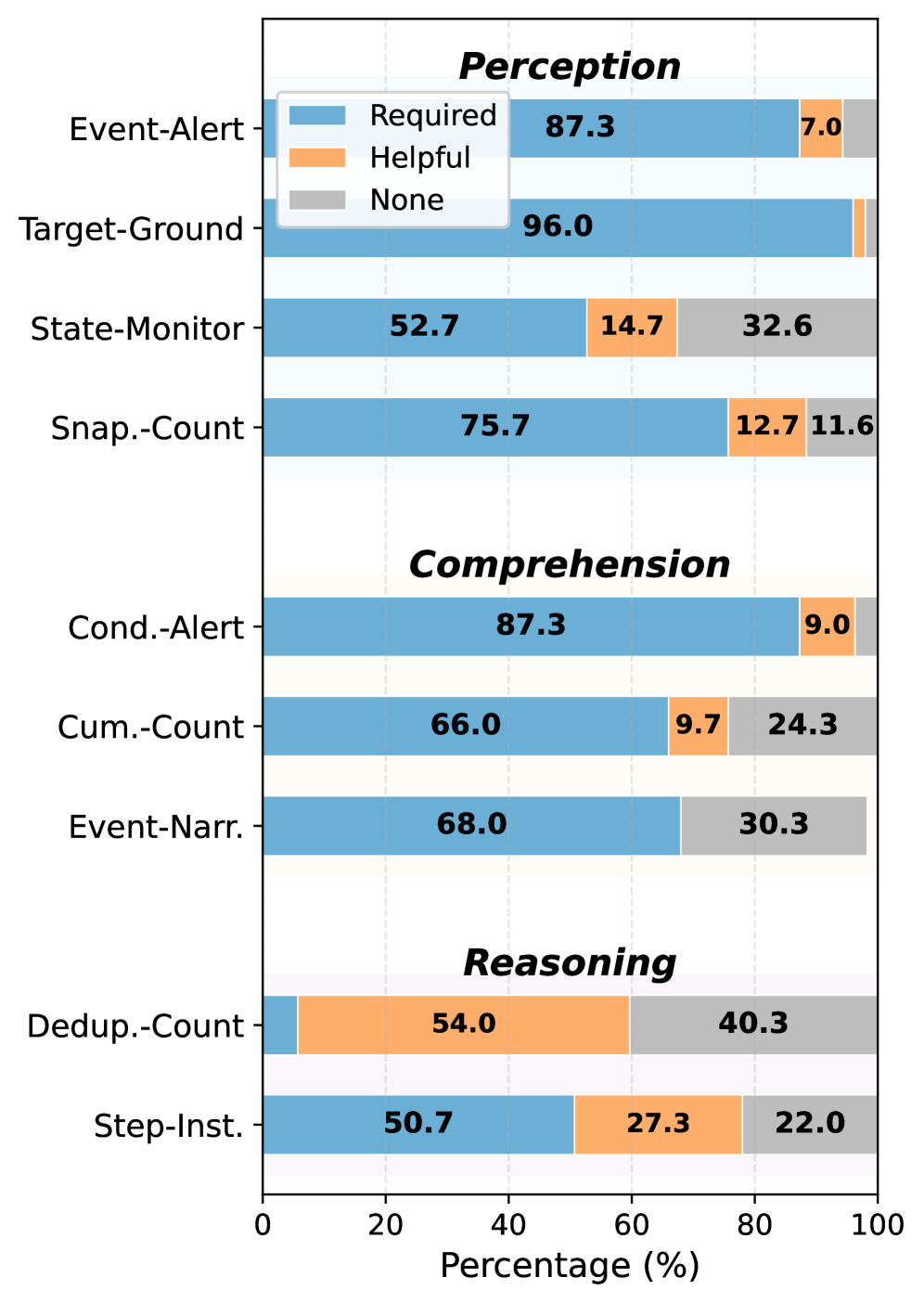
Figure 2 — 데이터셋 통계 속성
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] HakushoBench: A Japanese Chart and Table VQA Benchmark from Governmental White Papers
- [논문리뷰] PIRA-Bench: A Transition from Reactive GUI Agents to GUI-based Proactive Intent Recommendation Agents
- [논문리뷰] RIVER: A Real-Time Interaction Benchmark for Video LLMs
- [논문리뷰] BrowseComp-V^3: A Visual, Vertical, and Verifiable Benchmark for Multimodal Browsing Agents
- [논문리뷰] Demo-ICL: In-Context Learning for Procedural Video Knowledge Acquisition
Review 의 다른글
- 이전글 [논문리뷰] More Context, Larger Models, or Moral Knowledge? A Systematic Study of Schwartz Value Detection in Political Texts
- 현재글 : [논문리뷰] OmniPro: A Comprehensive Benchmark for Omni-Proactive Streaming Video Understanding
- 다음글 [논문리뷰] One Sentence, One Drama: Personalized Short-Form Drama Generation via Multi-Agent Systems
댓글