[논문리뷰] DenoiseRL: Bootstrapping Reasoning Models to Recover from Noisy Prefixes
링크: 논문 PDF로 바로 열기
메타데이터
저자: Caijun Xu, Changyi Xiao, Zhongyuan Peng, Yixin Cao
1. Key Terms & Definitions (핵심 용어 및 정의)
- DenoiseRL: 약한 모델(Weak Model)이 생성한 오답 경로를 '구조적 노이즈'로 간주하고, 이를 복구하도록 학습시킴으로써 모델의 추론 및 자가 수정(Self-correction) 능력을 향상시키는 강화학습 프레임워크입니다.
- Noisy Prefixes: 모델의 추론 과정 초기 단계에서 weak model이 생성한 잘못된 reasoning trace의 일부를 지칭하며, 이를 통해 정책 모델(Policy Model)이 어려운 중간 상태에서 올바른 해답으로 유도되도록 학습시킵니다.
- Recovery-oriented Optimization: 단순히 정답만을 학습하는 것이 아니라, 오류가 포함된 중간 상태로부터 정답에 도달하도록 복구 과정을 직접 학습 목표로 삼는 최적화 전략입니다.
- Folding (Output Budget): Denoise rollout과 일반 rollout 간의 공정한 비교를 위해, 전체 response 길이를 고정된 버짓(budget) 내에서 prefix와 continuation의 합으로 구성하는 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM의 추론 성능 향상을 위해 외부의 강력한 teacher 모델이나 복잡하게 큐레이션된 학습 데이터에 의존해야 하는 기존 RL 패러다임의 한계를 해결하고자 합니다. 기존 방식들은 학습 데이터의 품질이나 교사의 지식 수준에 따라 성능이 제약되는 structural limitation을 가지고 있습니다. 저자들은 이러한 의존성을 탈피하여 모델 스스로가 실패 사례를 학습의 기회로 전환할 수 있는 확장 가능한(scalable) 새로운 학습 기법이 필요하다고 주장합니다. [Figure 1]
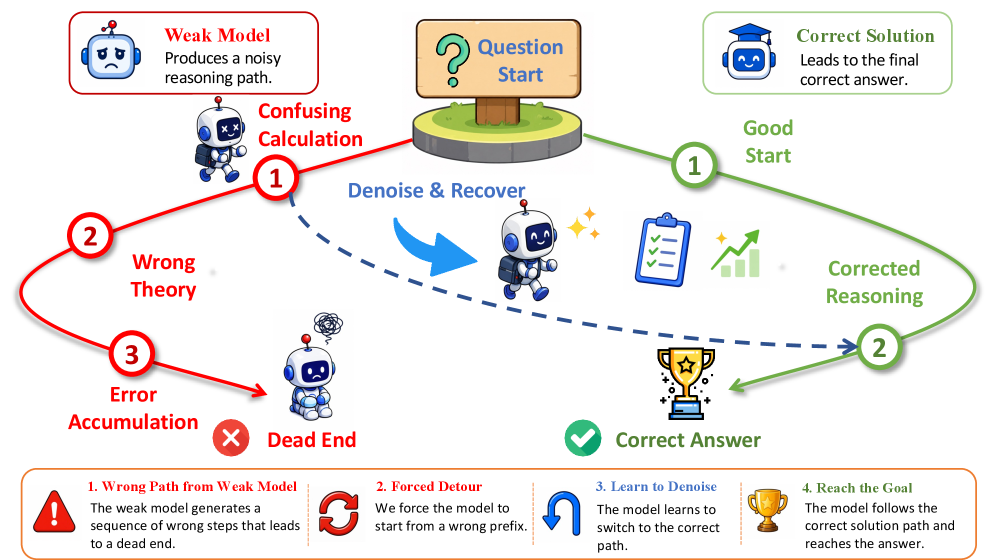
Figure 1 — DenoiseRL의 개념적 구조
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 DenoiseRL을 제안하며, weak model이 생성한 오답 reasoning path를 노이즈가 포함된 prefix로 활용하여 모델이 이를 복구하도록 학습합니다 [Figure 1]. 학습 시 main rollout(표준 on-policy)과 denoise rollout(noisy prefix로 시작)을 결합하여, 두 rollout 분포에 대한 조인트 목적 함수를 최적화합니다. 특히, 공정한 학습을 위해 출력 버짓을 folding하여 관리하며, prefix 자체는 업데이트하지 않고 이후의 continuation 부분에만 gradient를 적용하여 학습 안정성을 확보합니다. 실험 결과, Qwen3-4B-Base 및 Qwen3-8B-Base 모델에서 GRPO 및 DAPO 대비 일관된 성능 향상을 입증하였습니다. Qwen3-4B-Base 기준, DenoiseRL-GRPO는 GRPO baseline 대비 평균 성능을 39.6%에서 42.0%로 향상시켰습니다 [Table 1]. 또한, 적절한 noise intensity(prefix ratio $\rho=0.2$, K=4)가 학습 안정성과 성능 간의 최적의 균형을 제공함을 확인하였습니다 [Figure 4].
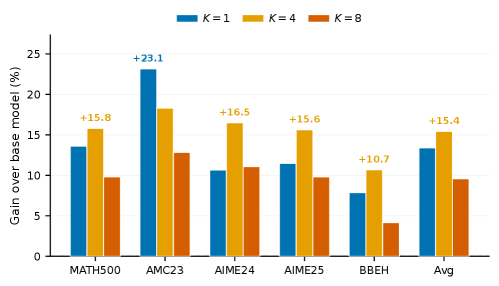
Figure 4 — Denoise rollout 수에 따른 성능 변화
4. Conclusion & Impact (결론 및 시사점)
본 논문은 모델의 실수가 단순히 학습 데이터의 손실이 아니라, 자가 수정 능력을 강화하는 귀중한 학습 신호가 될 수 있음을 입증하였습니다. DenoiseRL은 복잡한 데이터 큐레이션 없이 weak model의 실패를 활용함으로써 추론 모델의 학습 효율과 확장성을 크게 개선했습니다. 이 연구는 모델이 단순히 정답을 추종하는 것을 넘어, 잘못된 추론 상태를 식별하고 복구하는 고도화된 self-correction 메커니즘을 내재화하는 방향을 제시합니다. 이는 향후 LLM의 reasoning capability 강화 연구에 있어 데이터 자율성과 효율성을 중시하는 중요한 방법론적 토대가 될 것입니다.
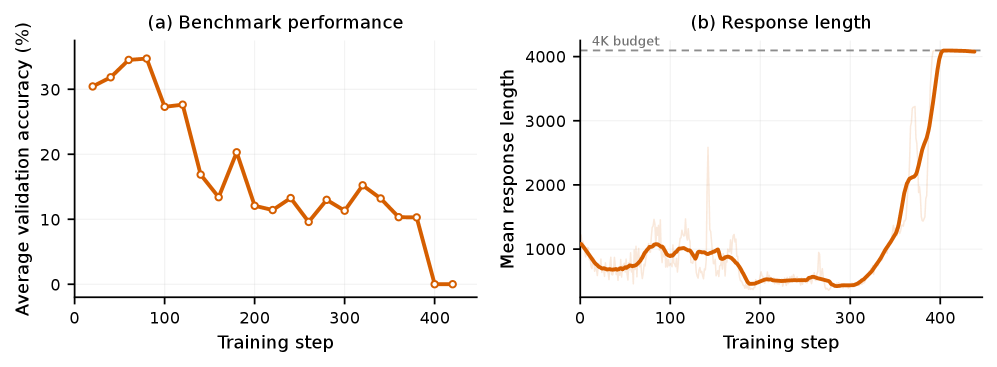
Figure 5 — Prefix 업데이트 시 학습 붕괴 현상
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Weak-to-Strong Generalization via Direct On-Policy Distillation
- [논문리뷰] MTSQL-R1: Towards Long-Horizon Multi-Turn Text-to-SQL via Agentic Training
- [논문리뷰] Attention as a Compass: Efficient Exploration for Process-Supervised RL in Reasoning Models
- [논문리뷰] ReasonRank: Empowering Passage Ranking with Strong Reasoning Ability
- [논문리뷰] Agon: Competitive Cross-Model RL with Implicit Rival Grading of Reasoning
Review 의 다른글
- 이전글 [논문리뷰] CubePart: An Open-Vocabulary Part-Controllable 3D Generator
- 현재글 : [논문리뷰] DenoiseRL: Bootstrapping Reasoning Models to Recover from Noisy Prefixes
- 다음글 [논문리뷰] ESC-Skills: Discovering and Self-Evolving Skills for Emotional Support Conversations
댓글