[논문리뷰] Efficient and Scalable Provenance Tracking for LLM-Generated Code Snippets
링크: 논문 PDF로 바로 열기
저자: Andrea Gurioli, Davide D'Ascenzo, Federico Pennino, Maurizio Gabbrielli, Stefano Zacchiroli
1. Key Terms & Definitions (핵심 용어 및 정의)
- SourceTracker: 코드 조각 검색을 위해 특화된 300M-parameter 규모의 인코더로, CLIP loss를 사용하여 학습된 모델입니다.
- Winnowing: 문서 지문(fingerprint)을 추출하여 문서 간 유사도를 판별하는 고전적인 알고리즘으로, MOSS 시스템의 근간을 이룹니다.
- HybridSourceTracker (HST): Vector Search의 효율성과 Winnowing의 정밀한 재순위화(re-ranking) 기능을 결합한 2단계 검색 프레임워크입니다.
- Code Clones: 코드 복제본을 정의하는 분류 체계로, 본 논문에서는 verbatim 복제(Type 1)와 식별자 이름이 변경된 도메인 적응형 복제(Type 2)를 주로 다룹니다.
- MRR (Mean Reciprocal Rank): 검색 시스템의 성능을 평가하는 지표로, 관련 항목이 검색 결과 리스트에서 나타나는 순위의 역수 평균을 의미합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM이 생성한 코드의 출처를 투명하게 추적하고 저작권 준수를 확인해야 하는 시급한 문제 의식에서 출발합니다. 기존의 Winnowing 기반 플래지어리즘 탐지 도구는 정확도는 높지만, 데이터셋 전체를 스캔해야 하는 선형 시간 복잡도로 인해 최신 LLM이 학습되는 대규모 데이터셋에 적용하기에는 한계가 있습니다. 반면, 기존의 단순 검색 방식은 LLM이 생성한 코드의 변형(Type 2 clone)에 취약하거나 문맥 파악 능력이 부족하여 신뢰성 있는 authorship attribution을 수행하지 못합니다. 따라서 저자들은 대규모 데이터셋에서도 효율적으로 작동하며, 높은 정밀도를 유지하는 새로운 provenance tracking 방법론을 제안합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 대규모 데이터셋에서 효율적인 검색을 위해 Vector Database 기반의 SourceTracker와 정밀 재순위화를 위한 Winnowing을 결합한 HybridSourceTracker (HST)를 제안합니다 [Figure 1]. 이 방법론은 먼저 SourceTracker를 통해 상위 100개의 후보 코드를 검색한 후, 그 후보군에 대해서만 Winnowing을 적용하여 정확도를 높이는 2단계 구조를 갖습니다 [Figure 1]. 실험 결과, 30-token 이상의 윈도우 크기에서 HST는 기존 baseline 대비 뛰어난 성능을 보였으며, 60-token 이상에서는 최대 5.4% 성능 우위를 점했습니다 [Table II]. 특히, Qdrant 엔진을 활용한 벡터 검색의 효율성 덕분에 HST는 데이터셋 규모에 관계없이 로그 시간 복잡도(logarithmic-time query complexity)를 유지하여 실용적인 확장성을 확보했습니다 [Figure 6]. 또한, LLM 기반의 judge를 활용한 정성 평가를 통해, ground truth에 포함되지 않았더라도 의미론적으로 매우 유사한 코드를 검색해냄으로써 사용자의 실질적인 요구를 충족함을 증명했습니다 [Figure 8].
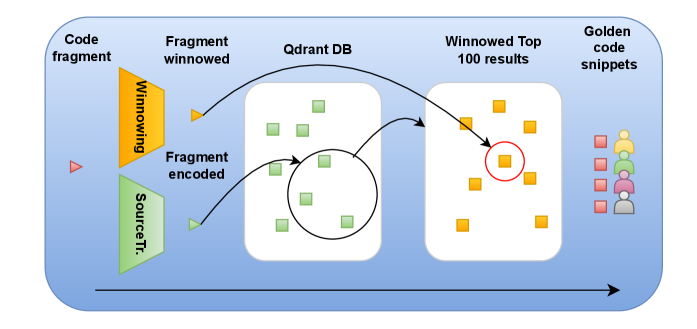
Figure 1 — HST 아키텍처 및 학습 과정
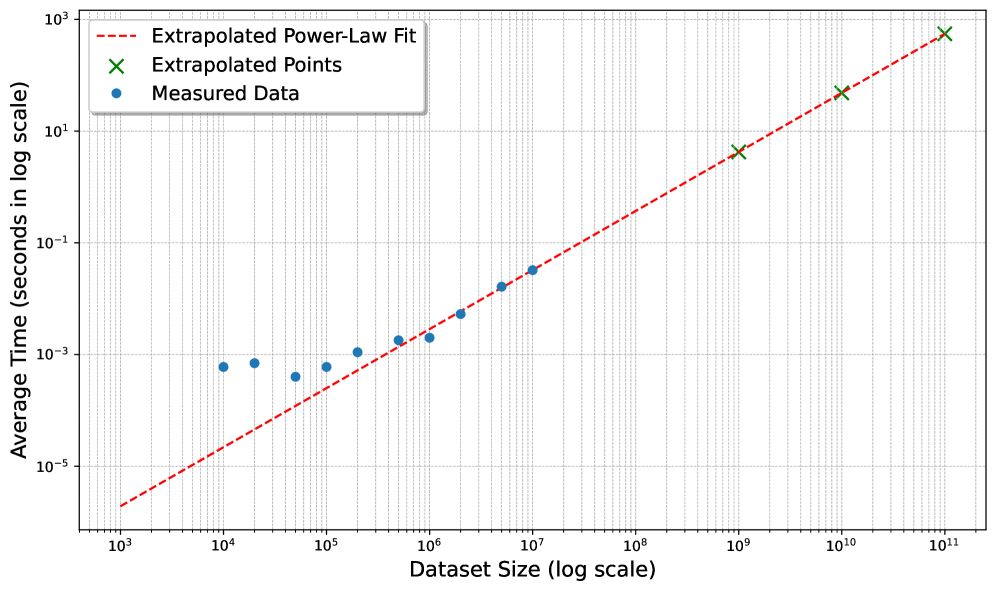
Figure 6 — Qdrant 검색 지연 시간
4. Conclusion & Impact (결론 및 시사점)
본 논문은 LLM 생성 코드의 출처 불투명성 문제를 해결하기 위해 검색 효율성과 정밀도라는 두 마리 토끼를 잡은 HST 프레임워크를 제안하며, provenance tracking 분야의 실무적 표준을 제시합니다. 연구 결과는 학계와 산업계가 LLM을 더욱 윤리적으로 사용하고, 학습 데이터의 출처를 투명하게 추적할 수 있는 기술적 기반을 마련했습니다. 특히, 저자들은 단순히 알고리즘을 제안하는 것에 그치지 않고, 학습 데이터 공개와 같은 투명성 확보가 AI 모델의 저작권 문제 해결에 필수적임을 강조하며 사회적 차원의 논의를 확장했습니다.
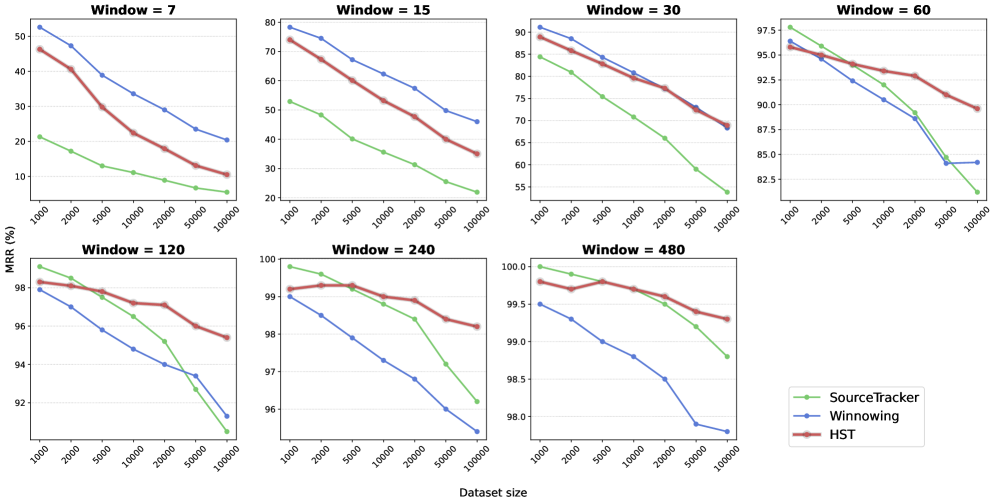
Figure 5 — 모델별 MRR 성능 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] xHC: Expanded Hyper-Connections
- [논문리뷰] Understanding Reasoning from Pretraining to Post-Training
- [논문리뷰] RAGU: A Multi-Step GraphRAG Engine with a Compact Domain-Adapted LLM
- [논문리뷰] From Human-Centric to Agentic Code Review: The Impact of Different Generations of Generative AI Technology on Review Quality
- [논문리뷰] Ring-Zero: Scaling Zero RL to a Trillion Parameters for Emergent Reasoning
Review 의 다른글
- 이전글 [논문리뷰] ESC-Skills: Discovering and Self-Evolving Skills for Emotional Support Conversations
- 현재글 : [논문리뷰] Efficient and Scalable Provenance Tracking for LLM-Generated Code Snippets
- 다음글 [논문리뷰] Everything at Every Scale: Scale-Invariant Diffusion with Continuous Super-Resolution
댓글