[논문리뷰] AgentDoG 1.5: A Lightweight and Scalable Alignment Framework for AI Agent Safety and Security
링크: 논문 PDF로 바로 열기
메타데이터
저자: Dongrui Liu, Yu Li, Zhonghao Yang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- AgentDoG 1.5: 오픈월드 에이전트의 안전성을 보장하기 위해 제안된 경량화 및 확장 가능한 Alignment Framework입니다.
- ATBench Family: 에이전트의 실행 궤적(Trajectory) 내에서 안전성을 진단하기 위해 고안된 벤치마크 군으로, Risk Source, Failure Mode, Real-world Harm의 3단계 분류법을 따릅니다.
- Influence-function Purification: 학습 데이터셋의 품질을 높이기 위해, Guardrail 성능 향상에 기여도가 높은 샘플을 선별하고 비효율적인 데이터를 제거하는 데이터 정제 기법입니다.
- Pre-Reply Guardrail: 에이전트가 최종 응답을 사용자에게 전달하기 직전 단계에서 궤적 전체를 검사하여 잠재적 위험을 차단하는 실시간 온라인 모니터링 시스템입니다.
- GDPO (Group Reward-Decoupled Normalization Policy Optimization): 다차원적인 보상 신호를 효과적으로 처리하여 에이전트의 안전성을 개선하는 RL 최적화 알고리즘입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대 에이전트 시스템(예: OpenClaw)의 강력한 실행 능력으로 인해 기존 안전성 프레임워크가 대응하기 어려운 광범위한 위험 요소가 발생하고 있다는 문제의식에서 출발한다. 기존 연구들은 주로 단일 시점의 입력이나 출력만을 평가하여 궤적 전체에 누적되는 복합적인 위험 패턴을 탐지하는 데 한계가 있었다 [Figure 1]. 또한, frontier AI 모델의 발전은 역설적으로 공격 수법을 고도화하여 기존의 경직된 안전성 가드레일을 무력화하고 있다. 이에 따라 저자들은 에이전트의 전체 실행 궤적을 심층 분석하고, 다양한 환경에 대응할 수 있는 확장 가능한 안전성 정렬 프레임워크가 필요함을 강조한다.
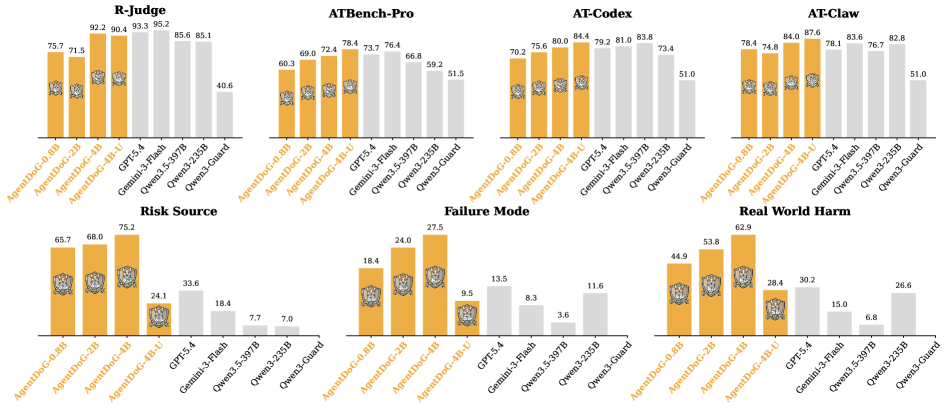
Figure 1 — 모델 안전성 비교 결과
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Taxonomy-guided Data Engine을 통해 1,000여 개의 고품질 학습 데이터를 구축하고, 이를 활용해 0.8B에서 8B 파라미터 규모의 AgentDoG 1.5 모델들을 학습시켰다 [Figure 6]. 제안 방법론은 에이전트의 SFT(Supervised Fine-Tuning) 단계에서 데이터 필터링을 수행하고, RL(Reinforcement Learning) 단계에서는 GDPO 알고리즘을 적용하여 안전성과 유틸리티 간의 균형을 최적화한다. 주요 실험 결과, AgentDoG 1.5-4B 모델은 R-Judge에서 92.2%의 Accuracy를 기록하였으며, ATBench에서도 기존 GPT-5.4 등 frontier 모델에 근접하거나 능가하는 성능을 보였다 [Table 2]. 특히, AgentDoG 1.5를 온라인 Pre-Reply 단계에 가드레일로 배치할 경우, ClawSafety 및 CIK-Bench와 같은 벤치마크에서 잔류 위험을 유의미하게 낮추는 동시에 실시간성(sub-second TTFT)을 확보하였다 [Table 6]. 이는 제안된 프레임워크가 경량화된 구조임에도 불구하고 복잡한 에이전트 실행 환경에서 강력한 안전성 감독 기능을 제공함을 입증한다.
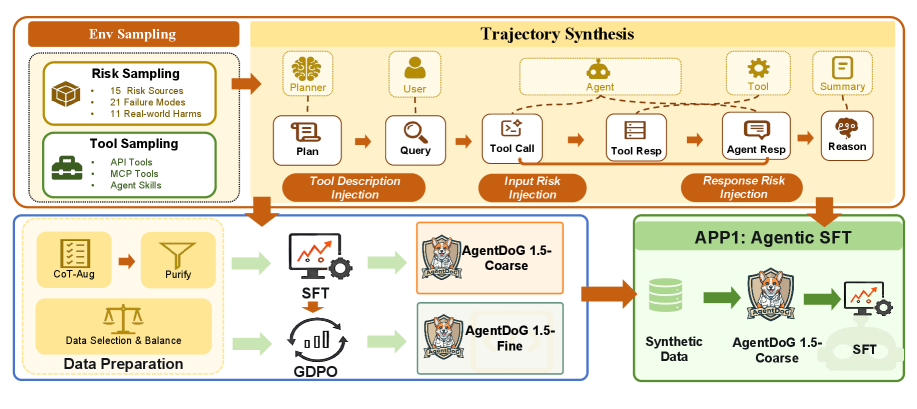
Figure 6 — 모델 구축 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 논문은 에이전트 안전성 정렬을 위한 경량화된 혁신 프레임워크로서 AgentDoG 1.5를 제안하며, 확장 가능한 안전성 분류법과 효율적인 학습 파이프라인을 확립하였다. 이 연구는 대규모 연산 자원이 부족한 환경에서도 실시간 에이전트 모니터링을 가능하게 함으로써 학계와 산업계의 에이전트 배포 안전성을 크게 강화할 것으로 기대된다. 또한, 정렬된 안전성 데이터셋과 모델을 오픈소스로 공개하여 후속 연구의 기반을 제공했다는 점에서 높은 가치를 지닌다. 향후에는 텍스트 기반 궤적을 넘어 멀티모달 환경으로의 확장 및 더 정교한 안전성 아키텍처 구축이 필요할 것이다.
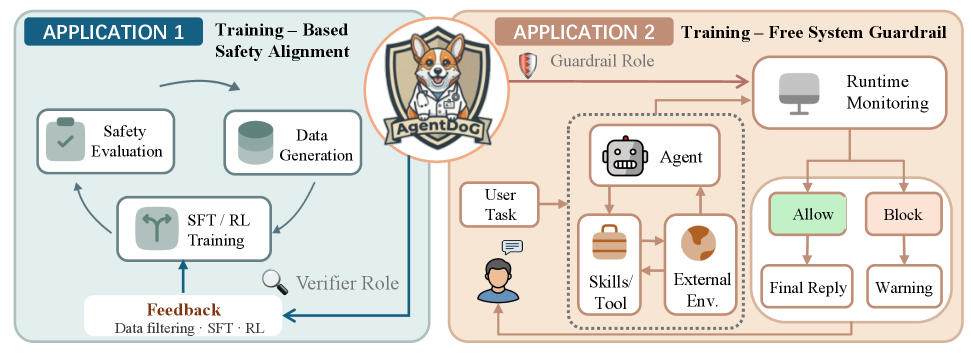
Figure 2 — 전체 안전성 프레임워크
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Understanding Reasoning from Pretraining to Post-Training
- [논문리뷰] On-Policy Delta Distillation
- [논문리뷰] Beyond Entropy: Correctness-Aware Advantage Shaping via Contrastive Policy Optimization
- [논문리뷰] Agon: Competitive Cross-Model RL with Implicit Rival Grading of Reasoning
- [논문리뷰] WanSong v1.0 Technical Report
Review 의 다른글
- 이전글 [논문리뷰] AdaState: Self-Evolving Anchors for Streaming Video Generation
- 현재글 : [논문리뷰] AgentDoG 1.5: A Lightweight and Scalable Alignment Framework for AI Agent Safety and Security
- 다음글 [논문리뷰] Alignment Tampering: How Reinforcement Learning from Human Feedback Is Exploited to Optimize Misaligned Biases
댓글