[논문리뷰] Towards Consistent Video Geometry Estimation
링크: 논문 PDF로 바로 열기
저자: Zhu Yu, Jingnan Gao, Runmin Zhang, Lingteng Qiu, Zhengyi Zhao, Rui Peng, Yichao Yan, Kejie Qiu, Siyu Zhu, Si-Yuan Cao, Hui-Liang Shen
1. Key Terms & Definitions (핵심 용어 및 정의)
- ViGeo: 비디오 시퀀스로부터 공간적으로 밀도 높고 시간적으로 일관된 기하학적 정보(depth, point maps, surface normals)를 복원하는 통합 feed-forward 파운데이션 모델입니다.
- Dynamic Chunking Attention: 입력 비디오 프레임을 시간적 chunk로 분할하여, chunk 내부에서는 bidirectional attention을, chunk 간에는 causal attention을 적용하는 기술입니다. 이를 통해 재학습 없이도 streaming, full-sequence, long-video inference를 전환할 수 있습니다.
- Completion-Based Data Refinement: 실측 데이터(LiDAR, SfM 등)의 노이즈와 결측치를 보완하기 위해, 비디오 depth completion teacher를 활용하여 고품질의 pseudo-labels를 생성하는 데이터 엔진입니다.
- KV Caching: 긴 비디오 시퀀스 처리 시 과거 프레임의 상태 정보를 재사용하여 메모리 증가를 제어하고 연산 효율을 높이는 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 비디오 기하학 추정 모델들이 모델 구조나 학습 프로토콜에 따라 offline(full-sequence) 또는 online(streaming) 환경 중 하나에만 국한되는 문제를 해결합니다. 기존 모델들은 정해진 temporal access pattern에 고착되어 있어, 추론 시점의 비디오 문맥에 맞춰 주의(attention) 패턴을 유연하게 변경할 수 없습니다. 또한, 실제 LiDAR나 SfM 기반 데이터셋의 희소성(sparse) 및 노이즈 문제는 고품질의 3D supervision 확보를 어렵게 만듭니다. 이를 극복하기 위해 본 연구는 모델 구조의 통합과 더불어 데이터 품질을 개선할 수 있는 새로운 접근 방식이 필요함을 강조합니다 [Figure 2].
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 단순한 ViT 백본에 Dynamic Chunking Attention을 결합하여, 하나의 모델이 다양한 추론 모드를 수용할 수 있도록 설계했습니다 [Figure 3]. 이 기법을 통해 Full-sequence, Chunk-based, Streaming 환경을 추론 시점에 chunk 파티션 설정만으로 즉시 전환할 수 있습니다. 또한, Completion-based data refinement 프레임워크를 통해 실측 데이터의 결측치를 정교하게 메우고 시간적 일관성을 확보한 학습 타겟을 구축했습니다 [Figure 4]. 주요 실험 결과, ViGeo는 Sintel, Bonn, KITTI 데이터셋에서 기존 offline 및 online 전용 모델들을 능가하는 SOTA 성능을 달성했습니다 [Table 3]. 특히 장시간 비디오(300~400 프레임) 추론 시, 기존 모델들이 OOM(Out-Of-Memory) 문제를 겪는 것과 달리 ViGeo는 일관된 성능과 안정적인 메모리 사용량을 보였습니다 [Table 4].
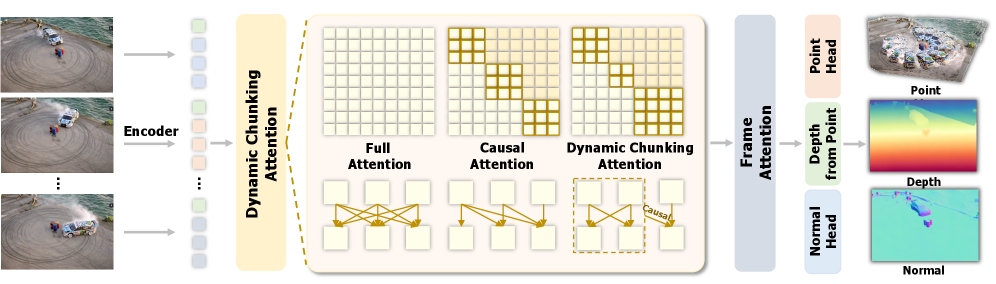
Figure 3 — ViGeo의 전체 구조 및 Attention 설계

Figure 4 — 데이터 정제 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Dynamic Chunking Attention을 통해 streaming과 full-sequence 추론을 하나의 파운데이션 모델로 통합한 ViGeo를 제안합니다. 이 모델은 dense하고 temporally consistent한 depth, point map, surface normal 추정을 실현하며, 데이터 refinement 프레임워크는 향후 대규모 3D 데이터셋 구축을 위한 핵심 데이터 엔진으로 활용될 수 있습니다. 본 연구는 로봇 공학, 자율 주행, AR/VR 등 정밀한 비디오 기반 기하학적 이해가 필요한 산업 및 학계 전반에 중요한 기술적 토대를 제공합니다.

Figure 1 — ViGeo 모델 아키텍처 개요
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] S1-Omni: A Unified Multimodal Reasoning Model for Scientific Understanding, Prediction, and Generation
- [논문리뷰] WanSong v1.0 Technical Report
- [논문리뷰] Self-Improvements in Modern Agentic Systems: A Survey
- [논문리뷰] ABot-N1: Toward a General Visual Language Navigation Foundation Model
- [논문리뷰] A Sovereign, Open-Source Foundation Model for German and English
Review 의 다른글
- 이전글 [논문리뷰] Token-Level Generalization in LoRA Adapter Backdoors: Attack Characterization and Behavioral Detection
- 현재글 : [논문리뷰] Towards Consistent Video Geometry Estimation
- 다음글 [논문리뷰] Towards Verifiable Multimodal Deep Research: A Multi-Agent Harness for Interleaved Report Generation
댓글