[논문리뷰] Task-Focused Memorization for Multimodal Agents
링크: 논문 PDF로 바로 열기
저자: Tao Zou, Yichen He, Tian Qiu, Yuan Lin, Hang Li
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- TaskMem: 환경 내에서 에이전트가 수행하는 실제 작업(Task)의 요구 사항에 맞춰 메모리 생성 정책을 최적화하는 RL 기반 프레임워크.
- GSPO (Group Sequence Policy Optimization): 시퀀스 레벨의 보상 환경에서 훈련 안정성과 효율성을 높이기 위해 제안된 RL 학습 알고리즘.
- Adapter: 모델의 베이스 가중치를 고정한 채, 특정 레이어에 삽입하여 연산 효율성과 Catastrophic Forgetting 방지를 동시에 달성하는 경량 파라미터 튜닝 기법.
- DPO (Direct Preference Optimization): 명시적인 보상 모델 없이도 선호 데이터(Preference Data)를 통해 정책을 최적화하는 기법으로, TaskMem의 Phase Two에서 task-relevance를 높이는 데 활용됨.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 멀티모달 에이전트가 방대한 스트리밍 데이터 속에서 '무엇을 메모리화할 것인가'를 스스로 판단해야 하는 문제를 해결하고자 한다. 기존 연구들은 휴리스틱한 프롬프트 엔지니어링이나 고정된 템플릿에 의존하여 메모리를 생성하므로, 실제 환경의 작업 요구 사항과 메모리 내용 간의 정렬(Alignment)이 부족하다는 한계가 있다. 저자들은 메모리 생성 과정을 고정된 요약 단계가 아닌 학습 가능한 정책(Learnable Policy)으로 프레임하며, 이를 통해 에이전트가 미래 작업의 유용성을 극대화하는 정보를 선택적으로 유지하도록 설계하였다 [Figure 1].
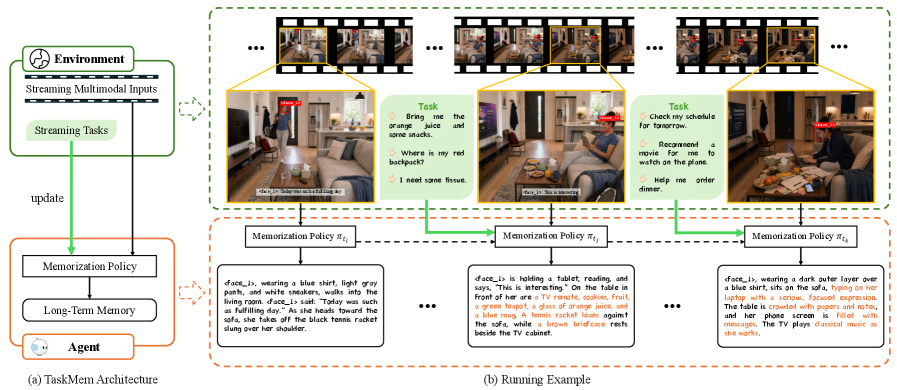
Figure 1 — TaskMem 아키텍처
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 저자들은 TaskMem을 위해 2단계 학습 패러다임을 제안한다. Phase One에서는 GSPO를 활용하여 메모리의 충실도, 무결성, 비중복성을 최적화하고, Phase Two에서는 배포 환경에서 수집된 실제 작업의 피드백을 사용하여 경량 어댑터를 튜닝함으로써 작업 관련성을 높인다 [Figure 2]. 특히 Phase Two에서는 희소한(Sparse) 피드백을 pair-wise 선호 데이터로 증강하여 DPO로 학습한다. 실험 결과, TaskMem은 VideoMME, EgoLife, EgoTempo 벤치마크에서 기존 베이스 모델(Qwen3-VL-30B-A3B) 대비 각각 6.3%, 7.0%, 5.3%의 VQA 정확도 향상을 기록하였다 [Table 1, Table 2]. 또한, 어댑터 삽입 위치에 대한 실험을 통해 shallow/middle 레이어 튜닝이 더 효과적임을 입증하였다 [Figure 5].
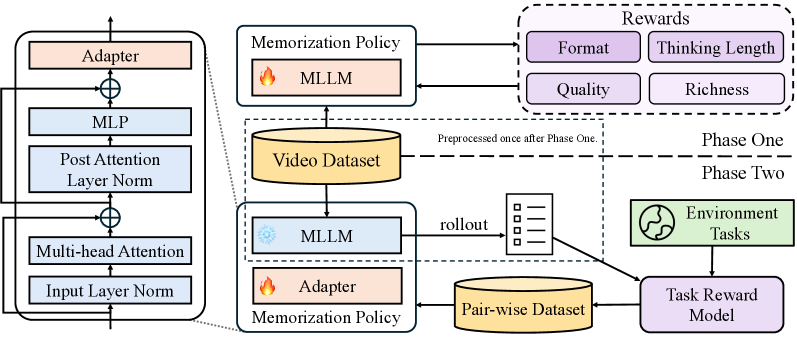
Figure 2 — 2단계 학습 구조
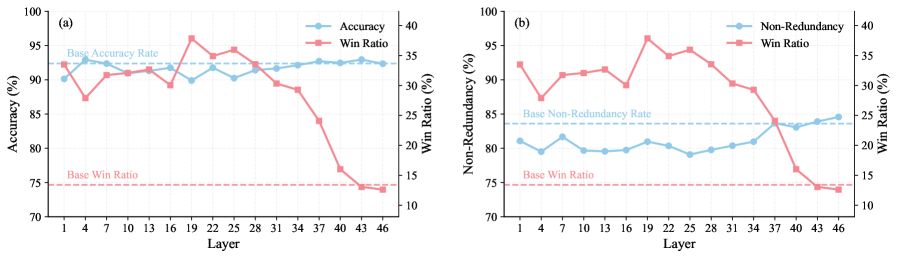
Figure 5 — 레이어별 어댑터 실험
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 메모리 생성을 능동적이고 목표 지향적인 과정으로 전환하여 멀티모달 에이전트의 long-term memory 효율성을 획기적으로 개선하였다. 제안된 2단계 RL 기반 학습 프레임워크는 에이전트가 환경에 배포된 후에도 연산 부담 없이 작업 중심의 메모리 생성이 가능하도록 지원한다. 이는 향후 Embodied AI와 같은 복잡한 실세계 환경에서 에이전트가 고차원적인 인지와 지속적인 학습을 수행하는 데 중요한 기술적 토대가 될 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] CanvasAgent: Enabling Complex Image Creation and Editing via Visual Tool Orchestration
- [논문리뷰] RLAnything: Forge Environment, Policy, and Reward Model in Completely Dynamic RL System
- [논문리뷰] EvoCUA: Evolving Computer Use Agents via Learning from Scalable Synthetic Experience
- [논문리뷰] SenseNova-MARS: Empowering Multimodal Agentic Reasoning and Search via Reinforcement Learning
- [논문리뷰] VisMem: Latent Vision Memory Unlocks Potential of Vision-Language Models
Review 의 다른글
- 이전글 [논문리뷰] SwanVoice: Expressive Long-Form Zero-Shot Speech Synthesis for Both Monologue and Dialogue
- 현재글 : [논문리뷰] Task-Focused Memorization for Multimodal Agents
- 다음글 [논문리뷰] The Flip Side of RLHF: On-Policy Feedback for Reward Model Self-Supervised Improvement
댓글