[논문리뷰] Agent Skills Should Go Beyond Text: The Case for Visual Skills
링크: 논문 PDF로 바로 열기
메타데이터
저자: Binxiao Xu, Ruichuan An, Bocheng Zou, Hang Hua, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Visual Skill: 텍스트 중심의 기존 스킬 정의를 넘어, Declarative Textual Logic, Visual Priors, 그리고 Multimodal Binding Protocol을 결합한 재사용 가능한 다중 모달 스킬 프레임워크입니다.
- Textual Degradation: 고차원적인 시각적 정보나 공간적 구조를 텍스트로만 압축/변환하여 표현할 때 발생하는 정보 손실 및 성능 저하 현상을 지칭합니다.
- Static Prior: GUI 요소의 위치, 인터페이스 레이아웃, 경계 조건 등 변하지 않는 공간적 규칙을 사전에 정의하여 제공하는 시각적 참조 데이터입니다.
- Dynamic Prior: 고정된 이미지가 아닌, 추론 과정에서 생성되는 궤적, 앵커, 탐색 경로 등 중간 상태를 시각적 트레이스로 유지하여 복잡한 시각적 과업을 수행하게 돕는 인-시투(In-situ) 시각적 기법입니다.
- AutoVisualSkill: 에이전트의 경험을 분석하여 텍스트 기반의 지식과 시각적 우선순위(Visual Priors)를 자동으로 변환하고 패키징하는 저작 파이프라인입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현재 에이전트 스킬 학습 패러다임이 텍스트 중심적(text-only)으로 구성되어 있어 시각적 과업 수행 시 발생하는 '텍스트 병목 현상(Textual Bottleneck)'을 해결하고자 합니다 [Figure 1]. 기존 연구들은 에이전트의 경험을 텍스트 기반의 절차적 지식으로 압축하여 저장하지만, 이는 GUI 조작이나 정밀한 카운팅과 같이 공간적 구조, 시각적 접지(Visual Grounding), 세밀한 인터페이스 상태 변화가 중요한 과업에서 심각한 정보 손실을 초래합니다. 단순히 텍스트 설명만으로는 '어디를 봐야 하는지', '어떻게 시각적 상태를 확인할 것인지'에 대한 정보를 명확히 전달하기 어렵기 때문입니다. 결과적으로 현재의 에이전트들은 매번 시각적 맥락을 재발견해야 하거나, 텍스트 기술의 모호성으로 인해 성능 최적화에 한계를 보이고 있습니다.
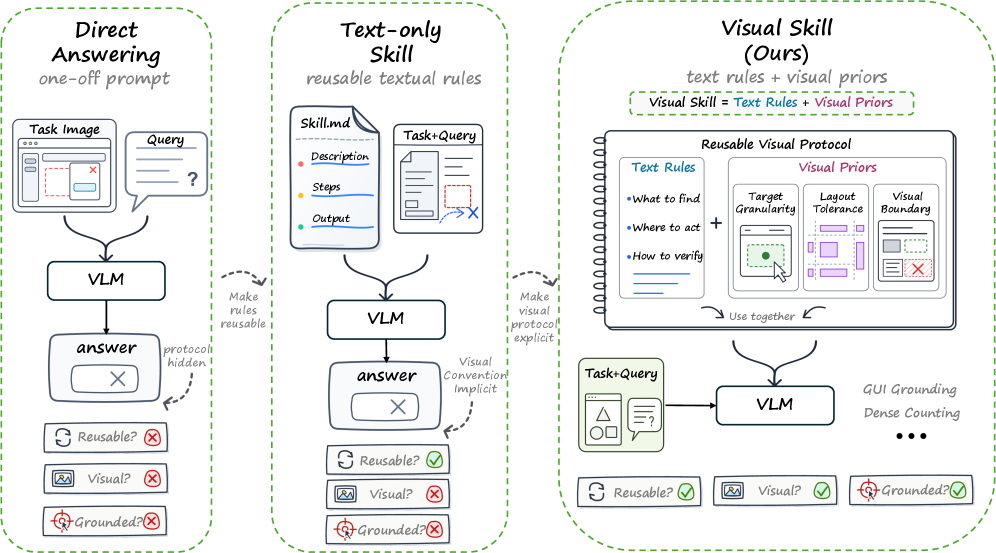
Figure 1 — 텍스트 기반에서 시각적 스킬로의 전환
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 시각적 구조를 일류 스킬 자산(First-class skill asset)으로 취급하는 Visual Skill 프레임워크를 제안합니다. 이 프레임워크는 텍스트 논리(Declarative textual logic)와 시각적 참조(Visual priors), 그리고 이들을 연결하는 바인딩 프로토콜로 구성되며, 정적인 공간 규칙을 위한 Static Prior와 동적 추론 상태를 기록하는 Dynamic Prior, 그리고 시각적 증거와 텍스트 단계를 결합하는 Interleaved visual skill을 활용합니다 [Figure 2]. AutoVisualSkill 파이프라인은 이러한 스킬들을 자동으로 생성하여 다양한 환경 간의 이식성을 제공합니다 [Figure 3].
Figure 2 — Visual Skill의 다양한 능력
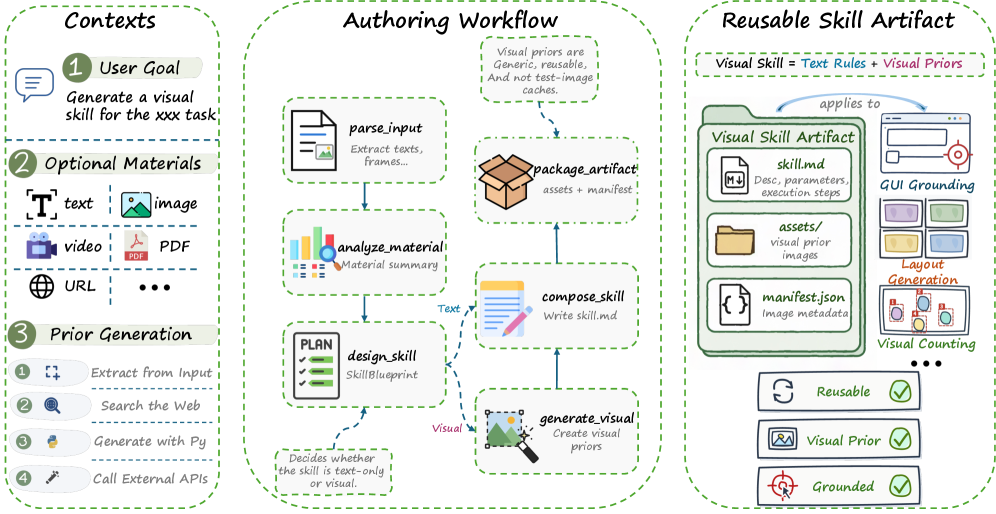
Figure 3 — AutoVisualSkill 저작 파이프라인
실험 결과, GUI Grounding 과업에서 Static Prior를 적용했을 때 Point-in-Box Accuracy가 기존 텍스트 기반 방법 대비 향상되었으며, 특히 경계 검출 능력을 나타내는 Mean IoU 지표에서 유의미한 성능 개선을 보였습니다 [Table 1]. 또한, Dense Object Counting 과업에서는 Dynamic Prior를 통해 시각적 앵커(Anchors)를 생성함으로써, 텍스트 기반 스킬만 사용했을 때보다 MAE(Mean Absolute Error)를 약 60% 감소시키는 등 극적인 정밀도 향상을 달성했습니다 [Table 2]. 이는 제안 모델이 시각적 공간 정보를 효과적으로 활용하여 명확한 추론과 상태 유지가 가능함을 정량적으로 입증합니다 [Figure 4].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 재사용 가능한 에이전트 스킬이 텍스트의 영역을 넘어 다중 모달 자산으로 진화해야 함을 강력히 시사합니다. 실험을 통해 확인된 높은 수준의 텍스트 저하(Textual Degradation)는 기존 텍스트 기반 방식의 명확한 한계를 보여주며, 시각적 우선순위가 에이전트의 추론 정확도와 효율성에 필수적임을 증명했습니다. 본 연구에서 제안된 Visual Skill 패러다임은 향후 더 복잡하고 긴 호흡의(Long-horizon) 다중 모달 과업을 수행하는 자율 에이전트 설계에 있어 중요한 기초 아키텍처로 활용될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] KnowAct-GUIClaw: Know Deeply, Act Perfectly, Personal GUI Assistant with Self-Evolving Memory and Skill
- [논문리뷰] VaseMuseum: Digital Intelligent Museum for Ancient Greek Pottery
- [논문리뷰] One Forward Beats Two: InnerZoom for Accurate and Efficient GUI Grounding
- [논문리뷰] Trust the Right Teacher: Quality-Aware Self-Distillation for GUI Grounding
- [논문리뷰] VisualClaw: A Real-Time, Personalized Agent for the Physical World
Review 의 다른글
- 이전글 [논문리뷰] Adapting Multilingual Embedding Models to Turkish via Cross-Lingual Tokenizer Surgery and Offline Distillation
- 현재글 : [논문리뷰] Agent Skills Should Go Beyond Text: The Case for Visual Skills
- 다음글 [논문리뷰] Brain-IT-VQA: From Brain Signals to Answers
댓글