[논문리뷰] Not only where, But when: Temporal Scheduling for RLVR
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jinghao Zhang, Ruilin Li, Feng Zhao, Jiaqi Wang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- RLVR (Reinforcement Learning with Verifiable Rewards): LLM post-training 과정에서 Verifier가 생성된 응답에 대해 단일 스칼라 보상을 제공하여 정책을 최적화하는 학습 패러다임입니다.
- Credit Allocation: 응답 시퀀스 내의 특정 토큰들이 최종 보상에 기여하는 정도를 식별하고, 해당 토큰들의 경사도(Gradient)를 재조정하여 효율적인 학습을 유도하는 기법입니다.
- TP-Score (Trajectory Percentile Score): 샘플링된 토큰이 전체 생성 시퀀스 내에서 나타날 확률이 가장 높은 상대적 위치를 수치화한 지표입니다.
- Temporal Scheduling: 학습 과정(Training steps) 전반에 걸쳐 Credit Allocation 기준을 고정하지 않고, 시간의 흐름에 따라 변화(Scheduling)시켜 정책의 진화 과정을 유연하게 조정하는 방법론입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 RLVR 방법론에서 사용되는 Stagnant Credit Allocation 기법들이 가지는 최적화의 경직성 문제를 해결하고자 합니다. 대다수의 기존 연구는 특정 토큰을 강조하는 기준을 학습 내내 일관되게 적용하여, 시퀀스 내에 존재하는 이질적인 정책 행동(Reasoning scaffolding vs. Answer convergence)을 통합적으로 최적화하는 데 한계를 보입니다 [Figure 1]. 저자들은 "학습 신호를 어디에 할당할 것인가(Where)"만큼 "학습 신호를 언제 스케줄링할 것인가(When)"가 중요하다는 점에 주목합니다. 기존 방식은 특정 토큰만을 지속적으로 강조함으로써 정책의 Entropy가 빠르게 붕괴되는 문제를 야기하며, 이는 보다 효율적인 정책 진화를 저해하는 요인이 됩니다.
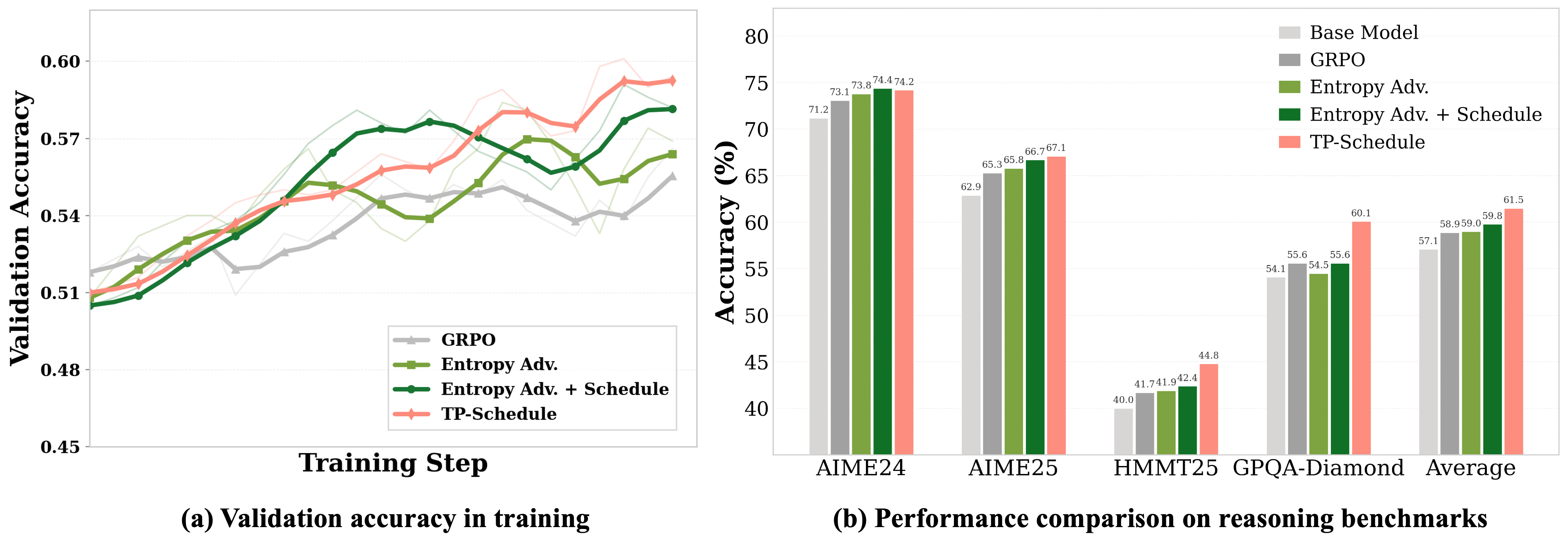
Figure 1 — 모델 성능 및 학습 동역학 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 학습 단계에 따라 할당 기준을 조절하는 Temporal Scheduling 프레임워크를 제안합니다. 구체적으로, 학습 초기에는 특정 타겟 토큰에 최적화를 집중하고, 점차 학습이 진행됨에 따라 범용적인 최적화로 기준을 완화하는 Monotonically Decreasing Schedule Function을 도입합니다 [Algorithm 1]. 특히, TP-Score를 사용하여 시퀀스 내의 토큰 위치에 따른 행동 특성을 파악하고, 이를 기반으로 후반부 토큰(생성 지속성)에서 시작해 전반부 토큰(추론 스캐폴딩)으로 최적화 범위를 확장하는 방식을 채택합니다 [Figure 2]. Qwen3-4B 모델 기준, TP-Schedule 도입 시 GRPO 대비 수학 벤치마크와 일반 추론 벤치마크에서 각각 2.2%, 2.7%의 성능 향상을 기록하였습니다 [Table 1]. 또한, 정량적 분석 결과 본 방법론은 기존 Entropy-based Advantage Reweighting 대비 33.9% 더 높은 Policy Entropy를 유지하며 더욱 건강한 최적화 동역학(Optimization dynamics)을 보여줍니다 [Figure 3].
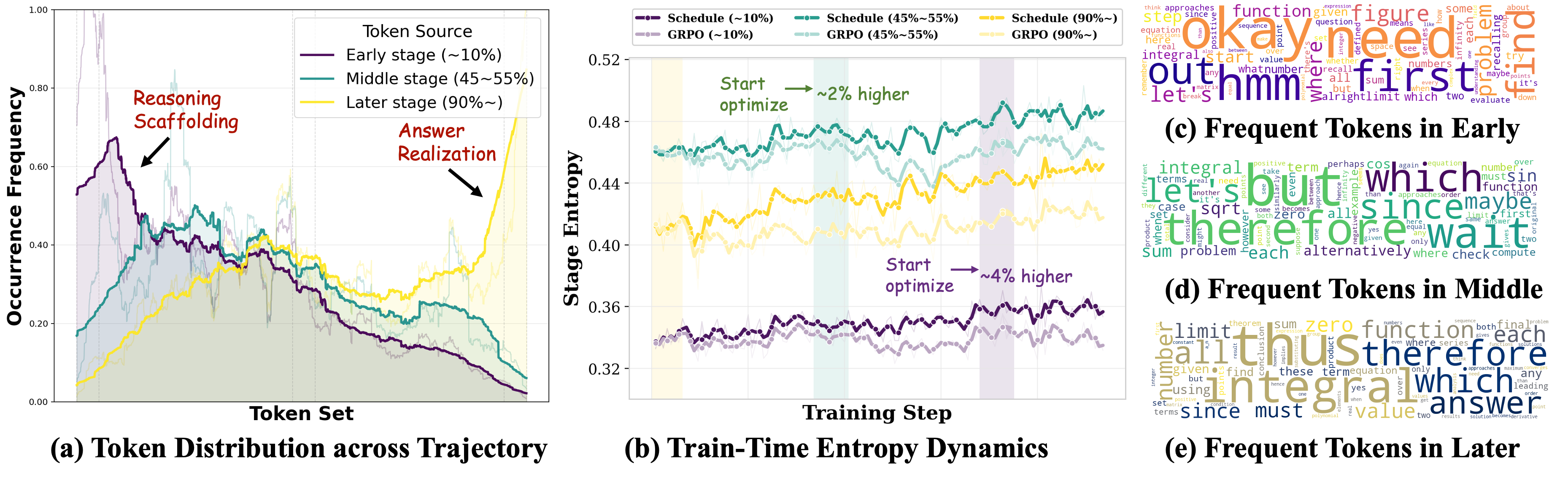
Figure 2 — 정책 행동 분석 및 동역학
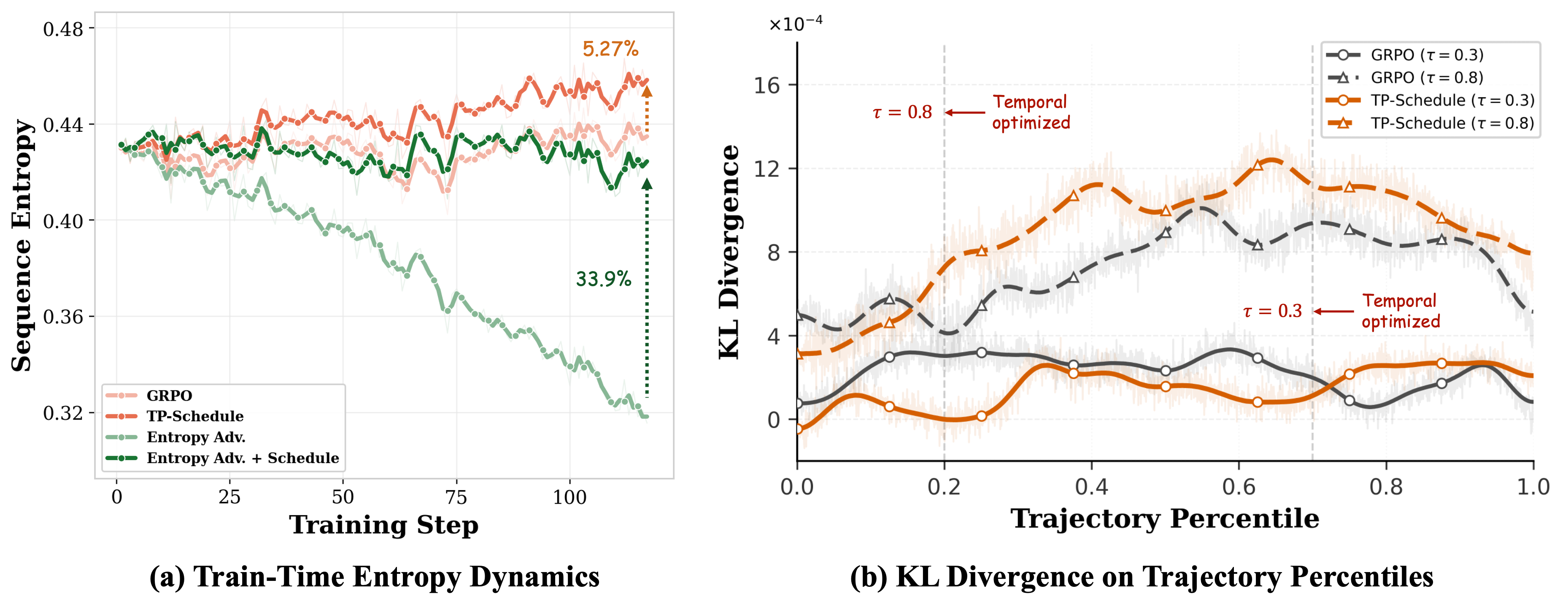
Figure 3 — Temporal Scheduling 하의 최적화 분석
4. Conclusion & Impact (결론 및 시사점)
본 연구는 RLVR 최적화의 새로운 차원인 Temporal Dimension을 성공적으로 입증하였으며, 기존의 정적인 Credit Allocation 패러다임을 혁신적으로 개선하였습니다. 시퀀스 내 토큰의 위치 정보인 Trajectory Percentile을 활용한 스케줄링은 정책의 점진적 정렬(Progressive alignment)을 가능하게 하여 학습 효율성과 최종 모델의 추론 성능을 동시에 확보합니다. 이 연구는 대규모 언어 모델의 추론 능력 향상을 위한 post-training 설계에 있어 시간적 정렬의 중요성을 학계에 제시하며, 향후 더 복잡한 추론 모델 학습을 위한 핵심적인 최적화 전략으로 활용될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] CLIPO: Contrastive Learning in Policy Optimization Generalizes RLVR
- [논문리뷰] Online Causal Kalman Filtering for Stable and Effective Policy Optimization
- [논문리뷰] On the Entropy Dynamics in Reinforcement Fine-Tuning of Large Language Models
- [논문리뷰] Multi-Task GRPO: Reliable LLM Reasoning Across Tasks
- [논문리뷰] Reinforcement Learning via Self-Distillation
Review 의 다른글
- 이전글 [논문리뷰] NITP: Next Implicit Token Prediction for LLM Pre-training
- 현재글 : [논문리뷰] Not only where, But when: Temporal Scheduling for RLVR
- 다음글 [논문리뷰] Off-the-Shelf LLMs as Process Scorers: Training-Free Alternative to PRMs for Mathematical Reasoning
댓글