[논문리뷰] Skill is Not One-Size-Fits-All: Model-Aware Skill Alignment for LLM Agents
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jianxiang Yu, Jiapeng Zhu, Bochen Lin, Qier Cui, Zichen Ding, Xiang Li
1. Key Terms & Definitions (핵심 용어 및 정의)
- MASA (Model-Aware Skill Alignment): 특정 LLM backbone의 성능 특성에 맞춰 skill library를 최적화하는 프레임워크로, agent의 가중치를 수정하지 않고 skill의 표현(granularity 및 framing)만을 조정합니다.
- Hierarchical Skill Evolution: 일반적인 행동 지침(general skills)과 환경별 작업 절차(task-specific skills)를 분리하여, 각각 Hill Climbing과 UCB-driven Tree Search 알고리즘을 통해 점진적으로 최적화하는 기법입니다.
- Model Card (ℳF): target LLM의 architecture, training provenance, capability profile을 포함하는 구조화된 프로필로, skill 재작성 시 핵심적인 컨디셔닝 신호로 사용됩니다.
- Nothing-Happens Rate (NHR): 환경 내에서 유효하지 않은 동작을 반복하여 상태 변화를 일으키지 못하는 비율을 의미하며, skill로 인한 에이전트의 불필요한 stalling을 측정하는 지표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM agent의 성능 향상을 위해 사용되는 기존의 skill library들이 모델의 용량(capacity)이나 행동 특성을 고려하지 않는 'model-agnostic' 방식으로 설계되었다는 한계를 지적합니다. 저자들은 동일한 skill이라도 모델 규모에 따라 성능 향상뿐만 아니라 성능 저하(degradation)를 유발할 수 있음을 실험적으로 입증하였습니다 [Figure 1]. 이러한 'one-size-fits-all' 접근 방식은 다양한 규모의 backbone을 활용해야 하는 실제 배포 환경에서 비효율적이며, 모델 특성에 맞는 최적화된 skill formulation이 필수적입니다 [Figure 1].
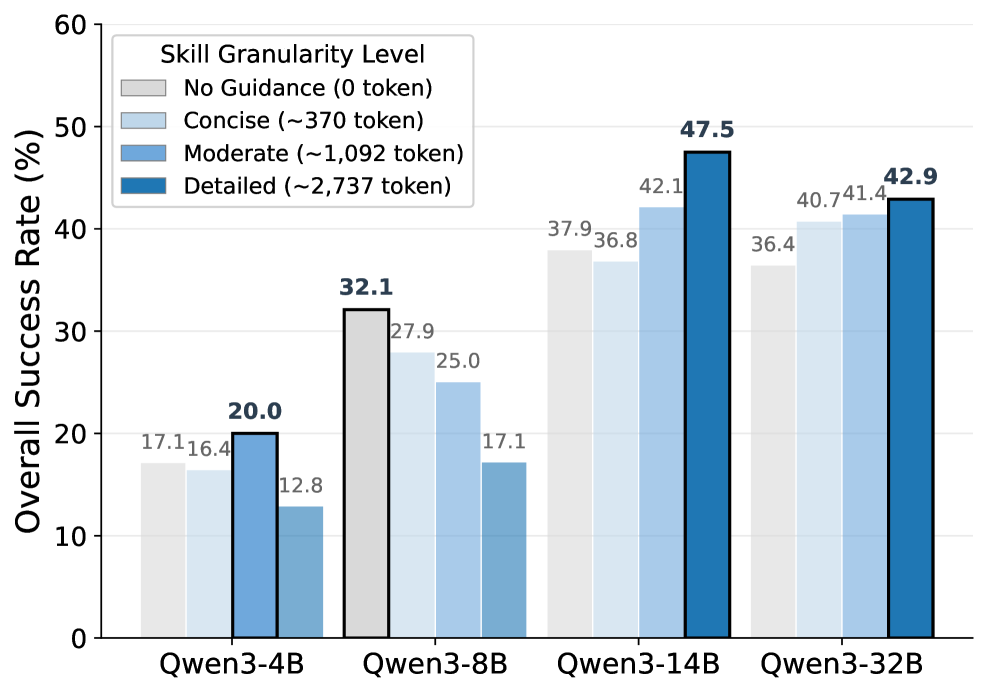
Figure 1 — 모델별 최적 granularity
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 에이전트의 weight를 고정시킨 채, MASA 프레임워크를 통해 skill을 각 모델의 특성에 맞춰 재작성(rewriting)하는 방법을 제안합니다 [Figure 2]. MASA는 먼저 teacher LLM을 사용하여 모델 카드(ℳF)에 기반한 계층적 진화 과정을 거치며 최적의 skill library를 도출하고, 이후 학습된 Model-Conditioned Skill Rewriter가 추론 시 단 한 번의 forward pass만으로 새로운 skill을 모델에 맞게 즉각적으로 변환합니다. ALFWorld 및 WebShop 환경에서 실험한 결과, MASA는 기존 Base Skill baseline 대비 최대 +25.8점의 성공률(SR) 향상을 달성하였습니다 [Table 1]. 특히, MASA는 더 큰 모델(teacher)보다 훨씬 낮은 비용으로 우수한 성능을 보였으며, 평균 상호작용 단계(average interaction steps)를 대폭 감소시켜 에이전트의 효율성을 입증하였습니다 [Table 1].
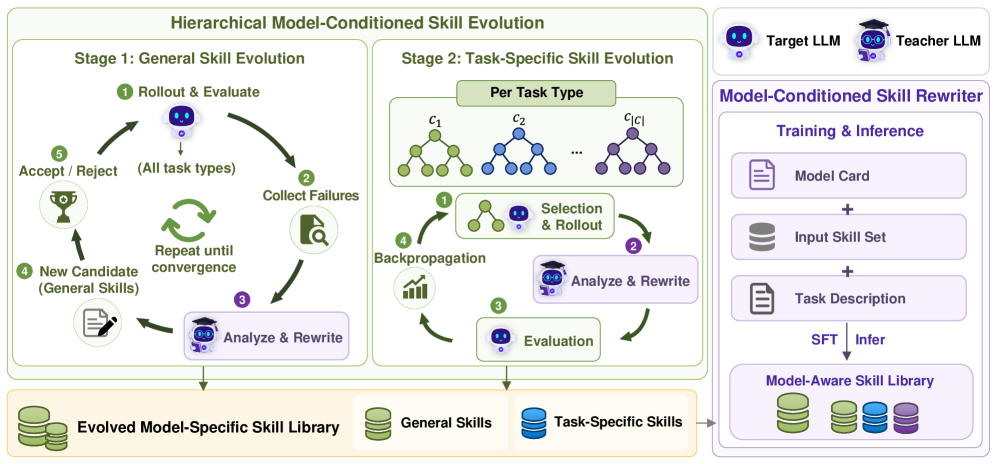
Figure 2 — MASA 프레임워크 전체 구조
4. Conclusion & Impact (결론 및 시사점)
본 연구는 skill 기반 에이전트 시스템에서 모델의 특성을 반영한 Model-Aware 정렬이 성능 최적화의 핵심임을 증명하였습니다. 제안된 MASA는 계층적 탐색과 경량 재작성기를 결합하여, 컴퓨팅 자원이 제한된 환경에서도 각 backbone의 잠재력을 극대화할 수 있는 실용적인 해결책을 제시합니다. 이러한 결과는 향후 대규모 에이전트 배포 시 모델별 맞춤형 지식 주입 및 효율적인 인-컨텍스트 학습 전략 개발에 중요한 학술적 근거를 제공할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Training-Free Group Relative Policy Optimization
- [논문리뷰] Tracing Agentic Failure from the Flow of Success
- [논문리뷰] Automating the Design of Embodied Agent Architectures
- [논문리뷰] When Classic Cache Policies Fail: Learning-Augmented Replacement for Semantic Retrieval Buffers
- [논문리뷰] Safety Testing LLM Agents at Scale: From Risk Discovery to Evidence-Grounded Verification
Review 의 다른글
- 이전글 [논문리뷰] Silent Failures in Physical AI: A Literature Review of Runtime Action Authorization for Autonomous Systems
- 현재글 : [논문리뷰] Skill is Not One-Size-Fits-All: Model-Aware Skill Alignment for LLM Agents
- 다음글 [논문리뷰] SkillAdaptor: Self-Adapting Skills for LLM Agents from Trajectories
댓글