[논문리뷰] Ψ-Bench: Evaluating Persona-Sensitive Influencing in Persuasive Dialogues
링크: 논문 PDF로 바로 열기
메타데이터
저자: Peixuan Han, Hongyi Du, Jiayu Liu, Yihang Sun, Yutong Liu, Jiaxuan You
1. Key Terms & Definitions (핵심 용어 및 정의)
- Persona-Sensitive Influencing: 사용자의 고유한 페르소나 프로필을 기반으로 대화 전략을 수립하여 상대방의 의견, 사고방식, 혹은 행동을 변화시키는 LLM의 능력을 의미합니다.
- Ψ-Bench: 본 논문에서 제안하는 벤치마크 프레임워크로, 세 가지 실세계 시나리오(Viewpoint Debate, Psychological Consultation, Everyday Request)를 통해 LLM의 설득 능력을 평가합니다.
- Profile Analyzer: 대화 이력을 바탕으로 사용자의 페르소나 정보를 추론하는 모델로, 본 연구에서는 Reinforcement Learning (RL) 기반의 경량화된 모델을 통해 성능을 최적화합니다.
- Oracle Setting: LLM이 사용자의 전체 프로필 정보를 사전에 완벽하게 제공받은 상태에서 대화를 수행하는 실험 환경을 의미합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대의 Personalized LLM Agent가 사용자의 선호에 맞춘 수동적 응답자(Passive Responder)에 머물러 있다는 한계를 지적하며, 보다 능동적인 설득 및 가이드 능력을 갖춘 'Proactive Personalization'의 필요성을 제기합니다. 기존 연구들은 일반적인 설득 능력에만 집중하거나, 사용자의 구체적인 페르소나를 간과하여 실제적인 설득 효과를 측정하지 못하는 문제가 있습니다. 저자들은 이러한 격차를 해소하기 위해 페르소나 정보가 명시적으로 반영된 사용자 시뮬레이션 기반의 평가 체계를 구축하고자 합니다. 세 가지 주요 시나리오에서 LLM의 설득 능력을 평가하며, 사용자 프로필의 유무가 실제 대화 결과에 어떠한 영향을 미치는지 정량적으로 분석합니다 [Figure 2].
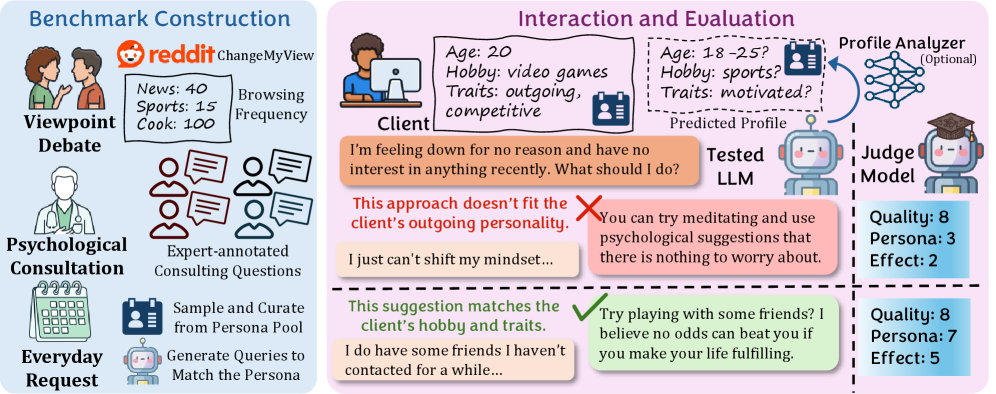
Figure 2 — Ψ-Bench 전체 프레임워크
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 세 가지 실세계 시나리오(Viewpoint Debate, Psychological Consultation, Everyday Request)로 구성된 Ψ-Bench를 통해 LLM을 평가하는 방법론을 제안합니다. 평가 지표로는 대화의 전반적인 품질을 측정하는 Quality, 사용자에 대한 맞춤화 수준을 평가하는 Personalize, 설득의 최종 목표 달성도를 측정하는 Effect 지표를 사용합니다 [Table 1]. 10개의 최신 LLM을 평가한 결과, 대부분의 모델은 훌륭한 Quality를 보였으나, 정작 설득 효과를 나타내는 Effect 점수는 최고 성능 모델조차 67% 미만에 머물렀습니다. 특히, client profile을 모델에게 제공할 경우 Effect 점수가 평균 18.24% 향상되는 것을 확인했습니다 [Figure 4]. 또한, Reinforcement Learning (RL)을 통해 학습된 Profile Analyzer를 도입함으로써, 프로필 정보가 주어지지 않은 상황에서도 설득 성과를 크게 개선할 수 있음을 입증했습니다 [Table 5].
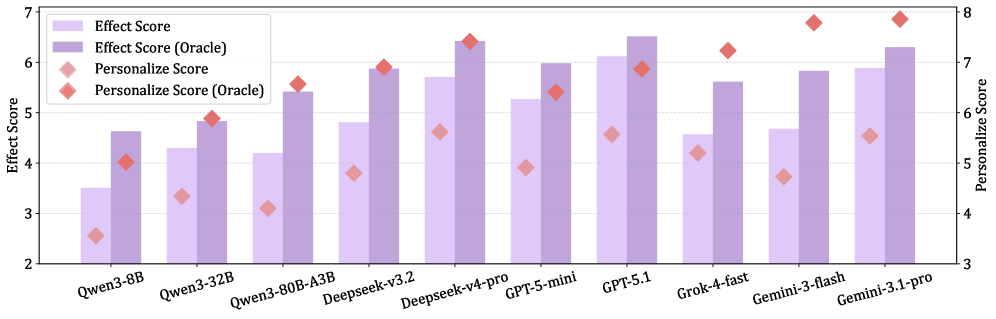
Figure 4 — 프로필 유무에 따른 설득 성능 비교
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Ψ-Bench를 통해 LLM의 '페르소나 기반 설득 능력'을 객관적으로 측정할 수 있는 체계를 마련하였습니다. 연구 결과, 설득 성공 여부는 단순한 대화 품질보다 사용자의 개별 특성을 파악하고 적응하는 능력인 Personalize에 크게 의존함이 밝혀졌습니다. 이는 향후 AI 에이전트가 보다 정교한 사용자 모델링을 통해 능동적이고 효과적인 상호작용을 수행할 수 있도록 하는 차세대 에이전트 개발 방향성을 제시합니다. 본 연구에서 입증된 RL 기반 프로필 분석 기술은 실제 서비스 환경에서 사용자 경험을 극대화하는 핵심 기술로 활용될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] WorldBench: A Challenging and Visually Diverse Multimodal Reasoning Benchmark
- [논문리뷰] AutoMedBench: Towards Medical AutoResearch with Agentic AI Models
- [논문리뷰] LLMEval-Logic: A Solver-Verified Chinese Benchmark for Logical Reasoning of LLMs with Adversarial Hardening
- [논문리뷰] DeonticBench: A Benchmark for Reasoning over Rules
- [논문리뷰] BenchPreS: A Benchmark for Context-Aware Personalized Preference Selectivity of Persistent-Memory LLMs
Review 의 다른글
- 이전글 [논문리뷰] World Models Meet Language Models: On the Complementarity of Concrete and Abstract Reasoning
- 현재글 : [논문리뷰] Ψ-Bench: Evaluating Persona-Sensitive Influencing in Persuasive Dialogues
- 다음글 [논문리뷰] αDepth: Learning Single-Pass Soft Boundary Decomposition for Stereo Conversion
댓글