[논문리뷰] Benchmarking Visual State Tracking in Multimodal Video Understanding
링크: 논문 PDF로 바로 열기
메타데이터
저자: Sihyun Yu, Nanye Ma, Pinzhi Huang, Hyunseok Lee, Shusheng Yang, June Suk Choi, Ellis Brown, Oscar Michel, Boyang Zheng, Jinwoo Shin, Saining Xie
1. Key Terms & Definitions (핵심 용어 및 정의)
- Visual State Tracking: 비디오 스트림 전반에 걸쳐 객체의 상태, 위치, 혹은 속성 변화를 지속적으로 추적하고 통합하는 능력.
- VSTAT (Visual STAte Tracking benchmark): 기존 비디오 이해 벤치마크의 한계를 극복하기 위해 설계된, 단일 프레임이나 짧은 세그먼트로는 정답을 유추할 수 없는 834개의 비디오 클립 기반 벤치마크.
- State Complexity: 비디오에서 정답을 도출하기 위해 추출해야 하는 정보의 양과 유형(Element Type: Count, Location, Attribute / Structure: Atomic, Sequence, Set, Dict)을 나타내는 지표.
- Perceptual Complexity: Occlusion, 카메라 모션, Homogeneity 등 비디오 스트림에서 시각적 인지를 어렵게 만드는 요인들.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 최신 Multimodal Large Language Models (MLLMs)가 비디오의 지속적인 역동성을 이해하고 상태를 추적하는 능력, 즉 Visual State Tracking 능력이 결여되어 있다는 점을 지적한다 [Figure 1]. 기존 벤치마크들은 특정 키프레임이나 종료 상태만으로도 정답을 유추할 수 있는 경우가 많아 모델의 실질적인 시각적 추적 능력을 측정하는 데 한계가 있다. 저자들은 현재의 MLLMs가 복잡한 절차적 과정이 포함된 실제 환경에서 상태 변화를 제대로 인지하지 못한다는 점을 문제로 제기한다. 이러한 성능 격차가 모델의 추론 능력 부재 때문인지, 아니면 시각적 인지 능력의 한계 때문인지 명확한 분석이 필요하다 [Table 1].
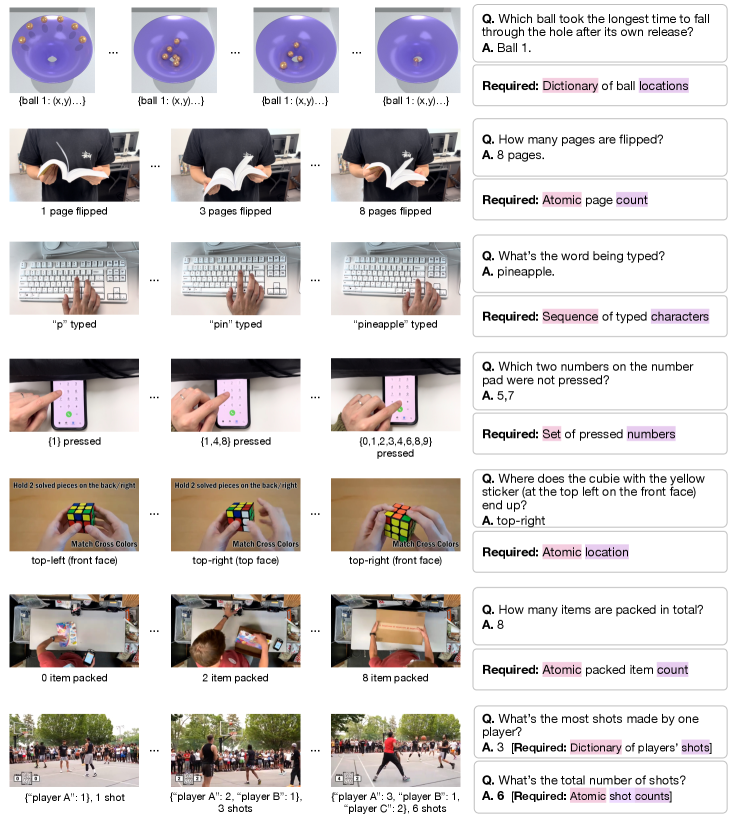
Figure 1 — VSTAT의 작업 예시
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 VSTAT 벤치마크를 구축하여 다양한 MLLMs를 평가하고, 모델의 성능이 인간 수준(90.5%)에 크게 미치지 못함을 확인하였다 [Table 2]. 모델의 실패 원인을 규명하기 위해 비디오를 텍스트로 전환하여 입력하는 실험을 수행한 결과, 모델이 텍스트 정보로는 작업을 완벽히 해결하지만 비디오 입력 시 성능이 급격히 저하됨을 확인하였다 [Figure 2(a), Figure 2(b)]. 이는 Visual State Tracking의 핵심 병목 구간이 시각적 인지(Perception)에 있음을 시사한다. 또한, 더 많은 프레임을 제공하거나 비디오를 시간적으로 확장해도 성능 향상이 미미함을 확인하였다 [Table 4]. 분석 결과, 주요 실패 유형은 이벤트 인식(Event recognition)이 50% 이상을 차지하며, 엔티티 연관(Entity association) 및 상태 업데이트(State update) 오류가 뒤를 잇는다 [Figure 4]. 최신 Agentic Frameworks를 도입하더라도 이러한 시각적 인지 오류는 쉽게 해결되지 않는 것으로 나타났다 [Table 5].
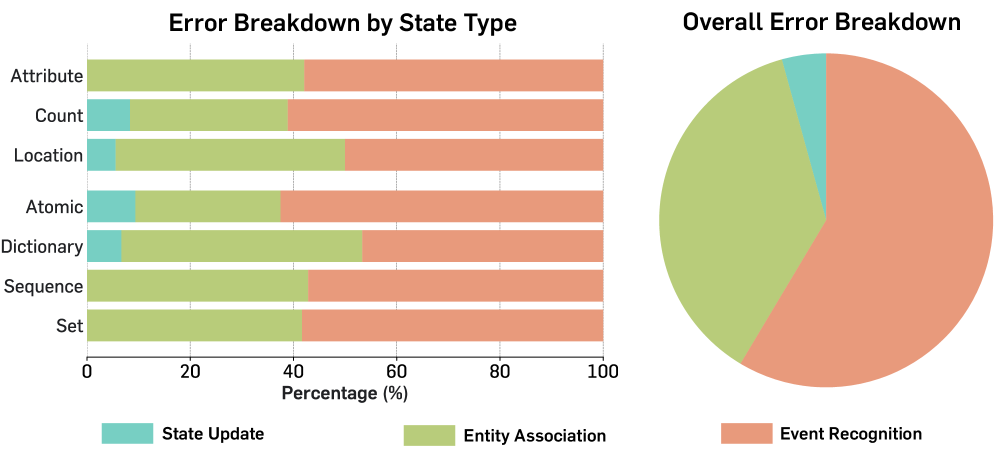
Figure 4 — 실패 유형 분석
4. Conclusion & Impact (결론 및 시사점)
본 연구는 VSTAT 벤치마크를 통해 최신 MLLMs가 비디오 내의 상태를 추적하는 시각적 인지 과정에서 근본적인 한계를 지니고 있음을 입증하였다. 실험 결과, 모델의 추론 능력보다 비디오 스트림 내의 이벤트를 정확히 인식하고 연관 짓는 시각적 인지 능력이 Visual State Tracking의 주된 병목임을 확인하였다. 이는 향후 영상 이해 모델이 단순한 의미론적 인식을 넘어, 복잡한 절차적 과정을 장기적으로 추적할 수 있는 고도화된 시각 인지 프레임워크로 발전해야 함을 시사한다. 본 연구에서 제시한 분석 도구와 벤치마크는 차세대 비디오 기반 MLLMs 개발의 방향성을 설정하는 데 중요한 기초 자료가 될 것이다.
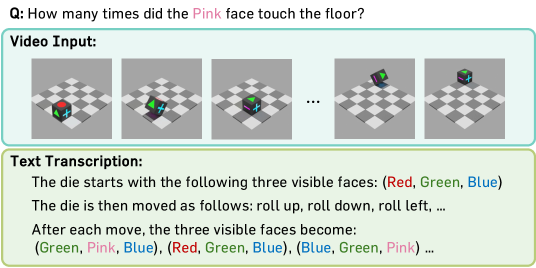
Figure 2 — 모델 성능 병목 분석
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Video-MME-v2: Towards the Next Stage in Benchmarks for Comprehensive Video Understanding
- [논문리뷰] Watch, Remember, Reason: Human-View Video Understanding with MLLMs
- [논문리뷰] VideoKR: Towards Knowledge- and Reasoning-Intensive Video Understanding
- [논문리뷰] M^3Eval: Multi-Modal Memory Evaluation through Cognitively-Grounded Video Tasks
- [논문리뷰] Omni-DuplexEval: Evaluating Real-time Duplex Omni-modal Interaction
Review 의 다른글
- 이전글 [논문리뷰] BA-T: An Iterative Transformer for Two-View Bundle Adjustment
- 현재글 : [논문리뷰] Benchmarking Visual State Tracking in Multimodal Video Understanding
- 다음글 [논문리뷰] Bootstrap Your Generator: Unpaired Visual Editing with Flow Matching
댓글