[논문리뷰] Small RL Controller, Large Language Model: RL-Guided Adaptive Sampling for Test-Time Scaling
링크: 논문 PDF로 바로 열기
메타데이터
저자: Runpeng Dai, Tong Zheng, Rui Liu, Chengsong Huang, Hongtu Zhu
1. Key Terms & Definitions (핵심 용어 및 정의)
- Test-Time Scaling: 모델 파라미터를 추가로 훈련하지 않고, 추론 시점의 연산 자원(예: 샘플링 횟수)을 조절하여 LLM의 추론 성능을 향상시키는 기법입니다.
- Adaptive Sampling: 고정된 샘플링 횟수를 사용하는 대신, 추론 과정에서 모델의 응답 통계를 바탕으로 추가 샘플링 여부나 중단 시점을 동적으로 결정하는 전략입니다.
- MDP (Markov Decision Process): 본 논문에서 Adaptive Sampling을 최적화하기 위해 도입한 수학적 프레임워크로, 상태(State), 행동(Action), 보상(Reward) 체계를 통해 정책(Policy)을 학습합니다.
- Lagrangian Relaxation: 제한된 연산 자원(Latency, Computation Cost) 내에서 추론 정확도를 최대화하기 위한 제약 최적화 문제의 해법으로, 본 연구의 RL 보상 함수 설계의 이론적 근거가 됩니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM의 추론 성능을 높이기 위한 Test-Time Scaling이 과도한 연산 비용과 지연 시간(Latency)을 초래한다는 문제를 해결하고자 합니다. 기존의 ASC나 ESC와 같은 적응형 샘플링 방법들은 주로 휴리스틱 규칙이나 특정 분포 가정에 의존하고 있어, 성능과 비용 간의 최적 균형을 달성하는 데 한계가 있습니다. 또한, 많은 기존 방법들이 모델의 내부 신호나 추가적인 훈련을 요구하여 실제 배포 시 운영 오버헤드를 발생시킵니다. 저자들은 이러한 한계를 극복하기 위해, 휴리스틱 기반의 규칙을 탈피하고 데이터 기반의 최적화된 정책을 학습할 수 있는 범용적인 프레임워크가 필요하다고 주장합니다 [Figure 1].
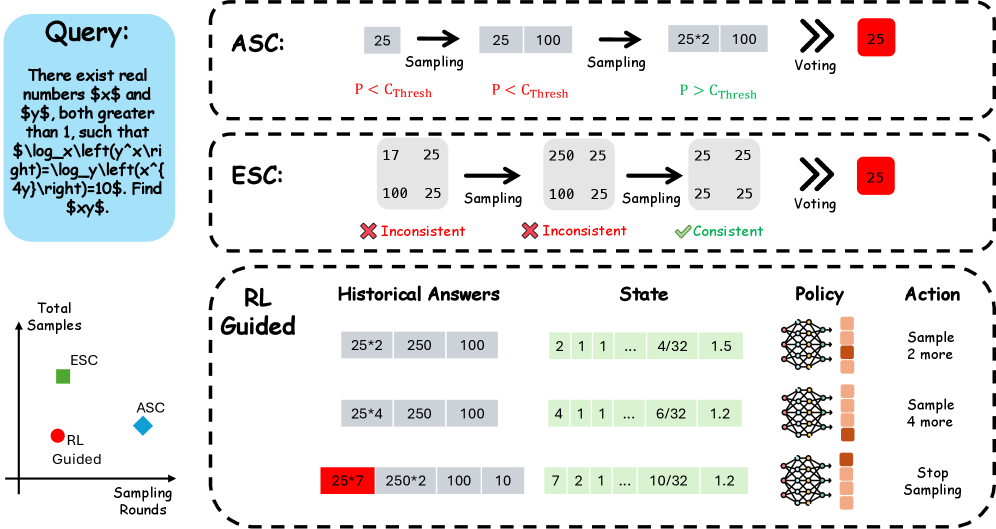
Figure 1 — RL-Guided Sampling 프레임워크 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Adaptive Sampling을 MDP로 공식화하고, 4층 MLP 기반의 경량 RL Controller를 학습하여 성능과 비용의 trade-off를 최적화하는 기법을 제안합니다. 제안 모델은 최종 출력값의 통계 정보만을 사용하여 의사결정을 내리므로, 복잡한 내부 신호 없이도 동작하며 CPU 환경에서도 효율적인 배포가 가능합니다. 제안된 정책은 PPO(Proximal Policy Optimization)를 통해 학습되며, 정확도(Accuracy)를 높이고 샘플링 라운드 및 토큰 비용을 최소화하도록 설계되었습니다. 실험 결과, RL-Guided Sampling은 ASC 대비 샘플링 라운드를 최대 4배, 총 샘플 수를 약 30% 감소시켰습니다 [Table 1]. 또한, ESC와 비교했을 때도 동일하거나 더 높은 정확도를 유지하면서도 연산 효율성 측면에서 우수한 성능을 입증했습니다 [Table 1]. 이러한 성능 향상은 다양한 모델과 벤치마크 데이터셋에서 일관되게 관찰되며, 학습된 정책의 범용성 또한 확인되었습니다 [Figure 2].
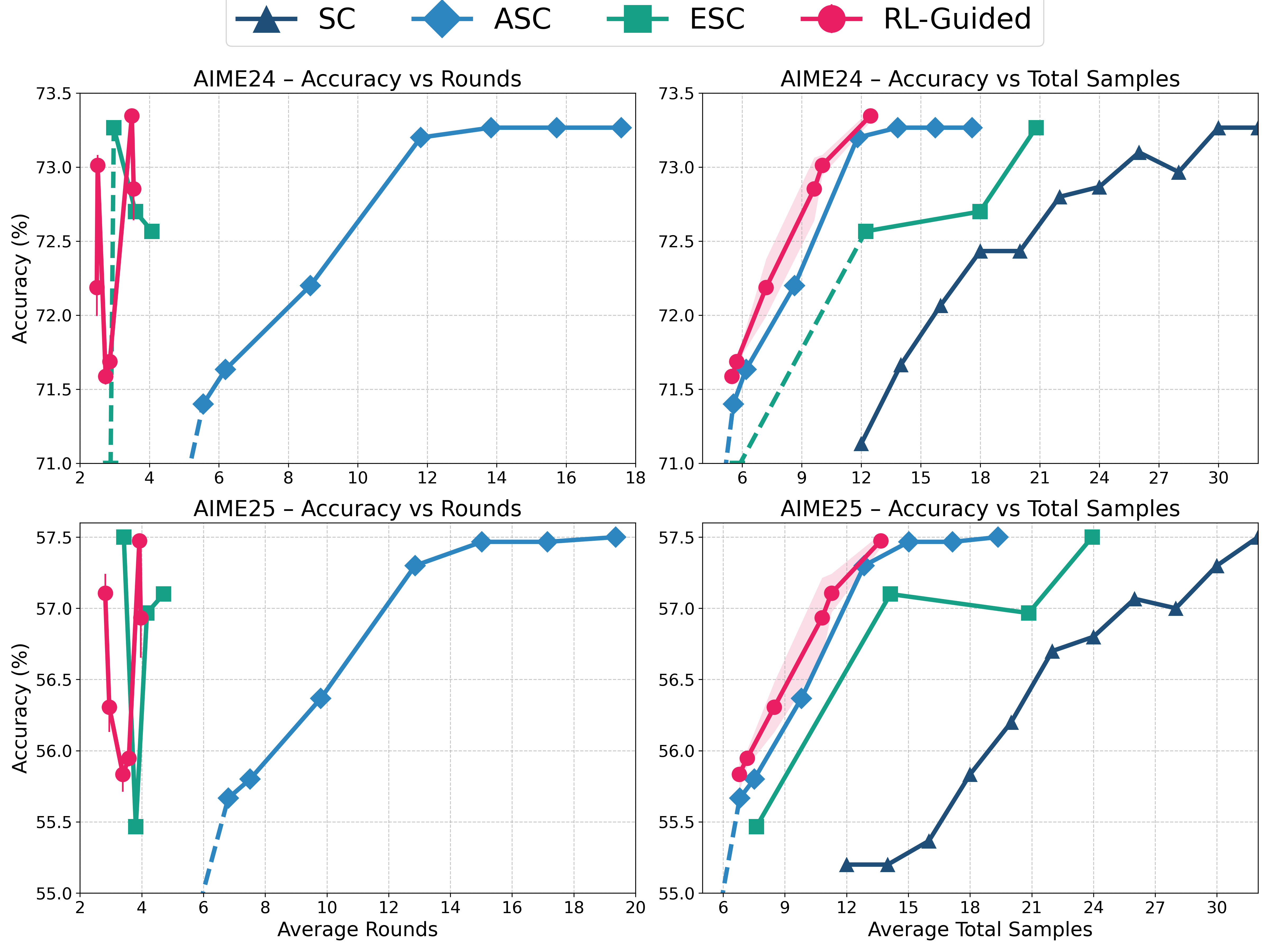
Figure 2 — 정확도 및 효율성 트레이드오프 성능
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Adaptive Sampling 문제를 MDP와 Lagrangian Relaxation 프레임워크를 통해 체계적으로 해결함으로써, LLM 추론 효율성을 극대화하는 혁신적인 방향을 제시합니다. 이 연구는 휴리스틱에 의존하던 기존 기법들을 대체할 수 있는 범용적이고 경량화된 제어 솔루션을 제공하며, 학계와 산업계의 추론 비용 절감에 크게 기여할 것으로 기대됩니다. 특히, 모델의 가시성이나 내부 신호 없이도 강력한 적응형 샘플링 성능을 달성하여, 실무적인 LLM 배포 환경에서 최적의 비용 효율적인 추론 전략으로 활용될 수 있습니다.
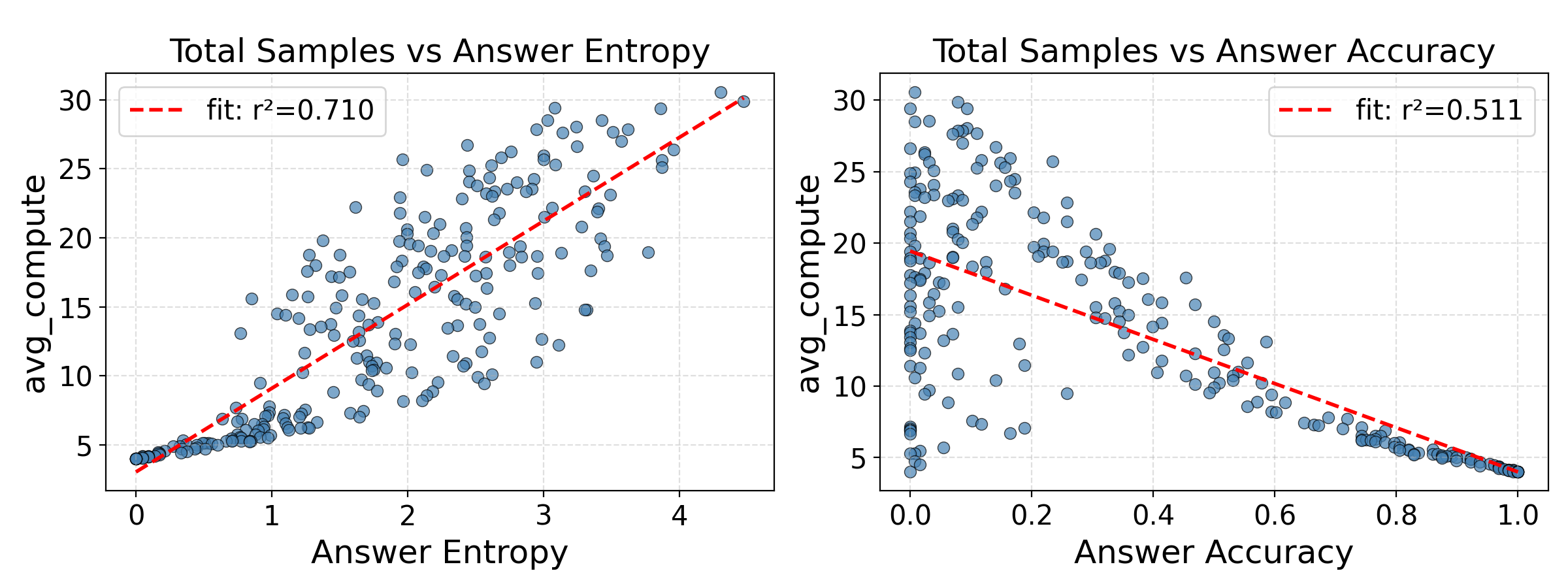
Figure 3 — 응답 엔트로피와 샘플링 할당량 상관관계
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Think Longer to Explore Deeper: Learn to Explore In-Context via Length-Incentivized Reinforcement Learning
- [논문리뷰] Seed-Prover 1.5: Mastering Undergraduate-Level Theorem Proving via Learning from Experience
- [논문리뷰] TaTToo: Tool-Grounded Thinking PRM for Test-Time Scaling in Tabular Reasoning
- [논문리뷰] Attention as a Compass: Efficient Exploration for Process-Supervised RL in Reasoning Models
- [논문리뷰] TreePO: Bridging the Gap of Policy Optimization and Efficacy and Inference Efficiency with Heuristic Tree-based Modeling
Review 의 다른글
- 이전글 [논문리뷰] Prior Availability in Industrial Visual Sim-to-Real: A Review of CAD-Guided and CAD-Unavailable Regimes
- 현재글 : [논문리뷰] Small RL Controller, Large Language Model: RL-Guided Adaptive Sampling for Test-Time Scaling
- 다음글 [논문리뷰] TRON: Targeted Rule-Verifiable Online Environments for Visual Reasoning RL
댓글