[논문리뷰] Trust Region On-Policy Distillation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Xingrun Xing, Haoqing Wang, Boyan Gao, Ziheng Li, Yehui Tang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- OPD (On-Policy Distillation): 학생 모델이 스스로 생성한 궤적(student-generated trajectories)을 바탕으로 학습하여, 교사 모델과 학생 모델 간의 분포 차이(distribution mismatch)로 인한 노출 편향(exposure bias) 문제를 완화하는 기법입니다.
- Trust Region: 교사 모델이 학생 모델의 생성물에 대해 신뢰할 수 있는 감독(supervision)을 제공할 수 있는 영역을 의미하며, 이를 기반으로 학생 모델이 학습해야 할 범위를 제한합니다.
- Outlier Estimation: 교사-학생 분포 불일치가 큰 영역에서 발생하는 잘못된 정책 경사(unreliable policy gradients)를 탐지하고, 이로 인한 악영향을 줄이기 위해 사용하는 전략(masking, clipping, FKL estimation 등)입니다.
- K1 Estimator: 제한된 메모리 환경에서 Reverse KL Divergence를 효율적으로 계산하기 위해 사용하는 근사치로, 긴 추론 궤적에 대한 OPD를 가능하게 합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Small Reasoning Models (SRM)을 위한 On-Policy Distillation (OPD)의 학습 불안정성과 비효율성 문제를 해결하고자 합니다. 기존 연구들은 교사-학생 분포의 큰 차이로 인해 발생하는 잘못된 정책 경사가 학습 붕괴(optimization failure)를 초래한다는 문제점이 있습니다. 또한, 기존의 REOPOLD와 같은 보상 클리핑(reward clipping) 방식은 유용한 정보까지 손실시킬 위험이 있어 성능 개선에 한계가 있습니다. 이를 해결하기 위해 저자들은 감독 신뢰도를 기준으로 영역을 분할하는 새로운 프레임워크가 필요함을 강조합니다 [Figure 1].
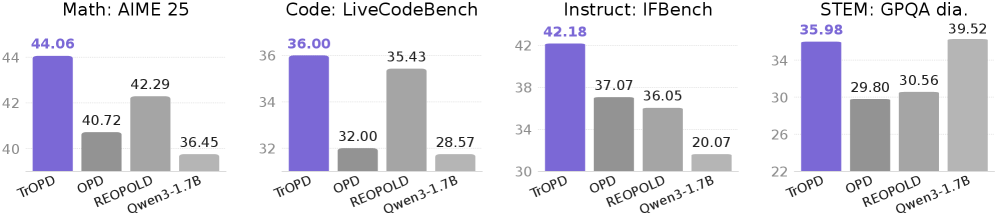
Figure 1 — TrOPD와 기존 모델 성능 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 신뢰할 수 있는 영역에서만 학습을 수행하고, 이상치 영역은 보조적인 방법으로 처리하는 TrOPD (Trust Region On-Policy Distillation)를 제안합니다 [Figure 2]. 핵심 방법론은 크게 세 가지로 구성됩니다: (1) Trust-Region On-Policy Learning을 통해 신뢰 구간 내에서만 K1 Estimator 기반의 RKL을 최적화하고, (2) Outlier Estimation을 통해 이상치 영역에서는 Forward KL (FKL)을 활용하여 유용한 정보를 보존하며, (3) Off-Policy Guidance를 도입하여 학생 모델이 교사의 궤적을 모방하도록 유도합니다. 실험 결과, TrOPD는 수학적 추론, 코드 생성, STEM 등 다양한 벤치마크에서 기존 OPD, EOPD, REOPOLD 대비 우수한 성능을 입증하였습니다. 구체적으로 DeepSeek-Qwen2.5-1.5B를 학생 모델로 사용했을 때, 수학적 추론 과제에서 평균 성능이 +3.06점 개선되었으며, 멀티 도메인 실험에서는 +4.62점의 향상을 보였습니다 [Table 3, Table 4].
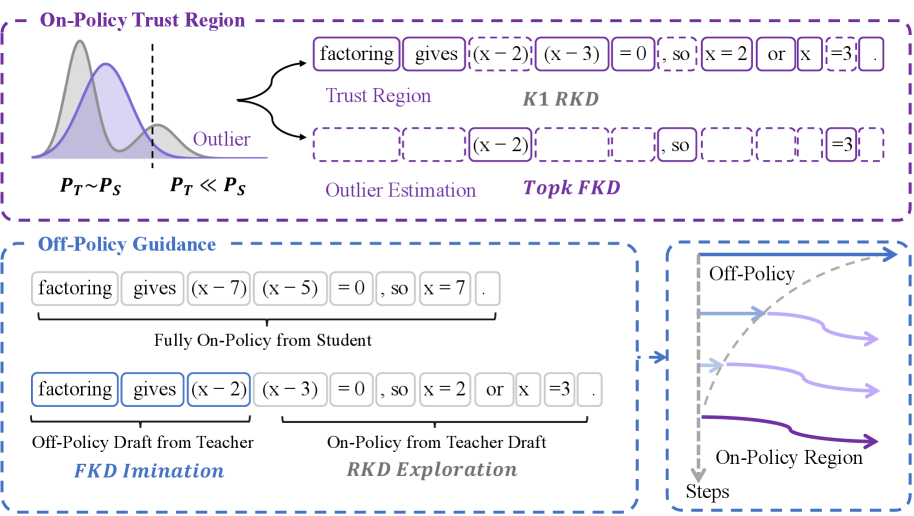
Figure 2 — TrOPD의 전체 아키텍처
4. Conclusion & Impact (결론 및 시사점)
본 논문은 TrOPD 프레임워크를 통해 추론 지향 모델의 OPD에서 감독 신뢰도의 중요성을 성공적으로 증명하였습니다. 제안된 Trust Region 및 Outlier Estimation 기법은 불안정한 정책 경사를 효과적으로 억제하면서도 정보 밀도는 높게 유지하는 최적의 균형을 제공합니다. 이 연구는 리소스 제약이 있는 환경에서 고성능 SRM을 구축하려는 학계 및 산업계에 중요한 기술적 가이드라인을 제시하며, 향후 LLM 경량화 및 추론 최적화 분야의 핵심적인 방법론으로 자리 잡을 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] OPRD: On-Policy Representation Distillation
- [논문리뷰] Filter, Then Reweight: Rethinking Optimization Granularity in On-Policy Distillation
- [논문리뷰] Trust-Region Behavior Blending for On-Policy Distillation
- [논문리뷰] Less is More: Early Stopping Rollout for On-Policy Distillation
- [논문리뷰] The Many Faces of On-Policy Distillation: Pitfalls, Mechanisms, and Fixes
Review 의 다른글
- 이전글 [논문리뷰] TRON: Targeted Rule-Verifiable Online Environments for Visual Reasoning RL
- 현재글 : [논문리뷰] Trust Region On-Policy Distillation
- 다음글 [논문리뷰] Ultralytics YOLO26: Unified Real-Time End-to-End Vision Models
댓글