[논문리뷰] AutoLab: Can Frontier Models Solve Long-Horizon Auto Research and Engineering Tasks?
링크: 논문 PDF로 바로 열기
메타데이터
저자: Zhangchen Xu, Junda Chen, Yue Huang, Dongfu Jiang, Jiefeng Chen, Hang Hua, Zijian Wu, Zheyuan Liu, Zexue He, Lichi Li, Shizhe Diao, Jiaxin Pei, Jinsung Yoon, Hao Zhang, Mengdi Wang, Radha Poovendran, Misha Sra, Alex Pentland, Zichen Chen
1. Key Terms & Definitions (핵심 용어 및 정의)
- AutoLab: 울트라
Long-horizon클로즈드 루프 최적화 성능을 평가하기 위해 설계된 새로운 벤치마크 프레임워크입니다. - Avg@3: 3회의 독립적인
rollout을 통해 얻은 평균 점수로, 모델의 일반적인 성능 수준을 측정합니다. - Dominance: 모든 모델과 과제를 대상으로 한
head-to-head승률을 기반으로 계산되는 지표로, 모델 간 상대적인 우위를 나타냅니다. - Wall-clock budget: 에이전트가 과제 해결을 위해 사용할 수 있는 제한된 총 운영 시간으로,
ultra long-horizon과제의 시간 관리 능력을 테스트합니다. - Reference solution: 각 과제별로 제공되는 전문가 수준의 해답으로, 에이전트의 점수 산정을 위한 상단 기준점(anchor) 역할을 합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 벤치마크가 단기적 또는 단일 단계(single-turn) 성능 평가에 치중되어 있어, 실제 과학 및 공학 분야에서 요구되는 장기적 반복 최적화 프로세스를 평가하지 못하는 한계를 해결하고자 합니다 [Figure 2]. 대부분의 기존 연구는 특정 도메인에 국한되거나 모델과 특정 하네스(harness)가 강력하게 결합되어 있어, 모델 자체의 근본적인 능력을 분리하여 평가하기 어렵습니다. 저자들은 이러한 격차를 극복하기 위해 System optimization, Model development, CUDA kernel optimization 등 4개 영역 36개 과제로 구성된 AutoLab을 제안합니다. 이 벤치마크는 에이전트가 처음에 제공된 suboptimal baseline을 지속적인 empirical feedback을 통해 점진적으로 개선할 수 있는지를 평가합니다 [Figure 1].
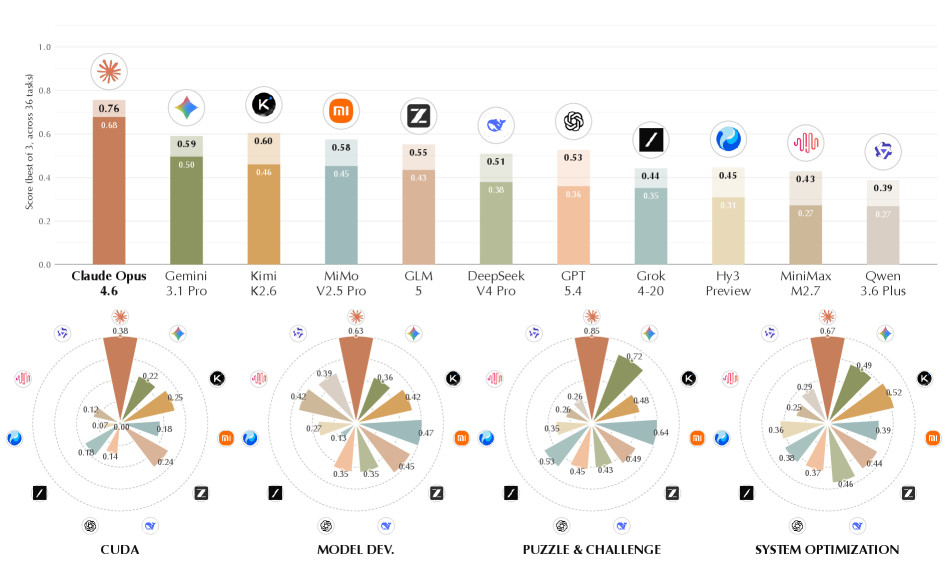
Figure 1 — 모델별 벤치마크 성능 비교

Figure 2 — AutoLab 과제 및 평가 파이프라인
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 17개의 최신 모델을 대상으로 2,544시간의 wall-clock 시간과 8.60B 토큰을 사용하여 체계적인 평가를 수행하였습니다 [Figure 1]. 제안된 AutoLab 평가 하네스는 sealed evaluator를 통해 reward hacking을 방지하며, 각 과제에 대해 베이스라인과 레퍼런스 솔루션을 기준으로 정규화된 연속 점수를 부여합니다 [Table 1]. 실험 결과, claude-opus-4.6이 Avg@3 0.68, Dominance 0.93으로 모든 영역에서 압도적인 성능을 보였습니다 [Table 1]. 반면, gpt-5.4나 grok-4-20과 같은 모델은 높은 성능 잠재력에도 불구하고, time awareness 부족으로 인한 premature termination 현상이 나타나 낮은 종합 순위를 기록했습니다 [Figure 5]. 특히 분석 결과, 최종 성능은 에이전트의 초기 솔루션 품질보다 persistence(반복적인 벤치마킹 및 수정)에 의해 결정되는 경향이 매우 강함이 확인되었습니다 [Figure 4].
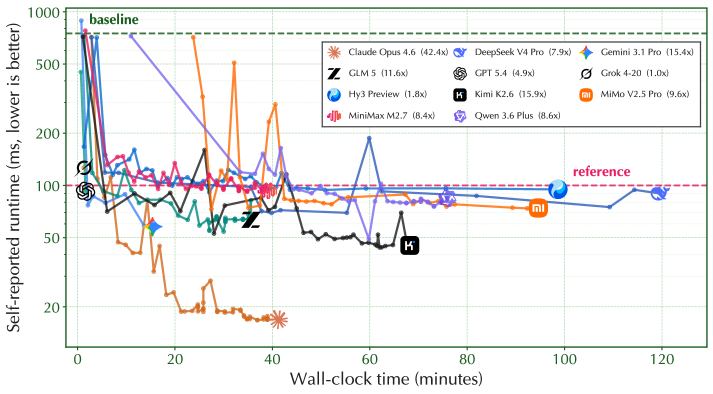
Figure 4 — 플래시 어텐션 최적화 사례 연구
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Long-horizon 에이전트의 핵심 성능이 단순한 코딩 능력이 아닌, 시간 배분과 반복적인 시행착오를 통한 지속적인 개선 역량에 있음을 입증하였습니다. AutoLab은 학계와 산업계가 향후 자율 연구 에이전트의 성능을 보다 정교하고 현실적으로 측정할 수 있는 표준 지표를 제공합니다. 이 연구는 모델의 failure mode를 명확히 분류하여 차세대 모델 및 에이전트 아키텍처 설계 시 time-aware한 루프 제어와 강력한 instruction following의 중요성을 강조합니다. 본 벤치마크와 하네스는 오픈 소스로 제공되어 autonomous research 분야의 발전을 가속화할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] Where, What, Why, and Importance: Structured Defect Grounding for Text-to-Image Feedback
- [논문리뷰] WeaveBench: A Long-Horizon, Real-World Benchmark for Computer-Use Agents with Hybrid Interfaces
- [논문리뷰] WEAVER, Better, Faster, Longer: An Effective World Model for Robotic Manipulation
- [논문리뷰] Visual Para-Thinker++: A Single-Policy Multi-Agent Framework for Visual Reasoning
Review 의 다른글
- 이전글 [논문리뷰] Audio Interaction Model
- 현재글 : [논문리뷰] AutoLab: Can Frontier Models Solve Long-Horizon Auto Research and Engineering Tasks?
- 다음글 [논문리뷰] BenchEvolver: Frontier Task Synthesis via Solution-Centric Evolution
댓글