[논문리뷰] STRIDE: Training Data Attribution via Sparse Recovery from Subset Perturbations
링크: 논문 PDF로 바로 열기
메타데이터
저자: Rishit Dagli, Abir Harrasse, Luke Zhang, Florent Draye, Amirali Abdullah, Bernhard Schölkopf, Zhijing Jin, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- TDA (Training Data Attribution): 모델의 특정 예측 결과를 학습 데이터의 개별 사례들에 할당하여, 데이터가 모델의 출력에 미친 인과적 영향력을 정량화하는 기법입니다.
- Steering Operators: frozen 된 base model의 중간 Activations에 적용되는 경량화된 저차원(low-rank) 연산자로, 데이터 서브셋을 학습했을 때 발생하는 모델의 행동 변화를 시뮬레이션합니다.
- Sparse Recovery: 본 논문에서 TDA를 해결하기 위해 사용하는 기법으로, 압축된 서브셋 측정치로부터 데이터의 영향력(Influence) 분포가 Sparse하다는 가정하에 개별 사례의 영향력을 복원하는 알고리즘입니다.
- LDS (Linear Datamodeling Score): 학습 데이터 서브셋에 대한 모델의 응답과 데이터 모델의 예측치 사이의 상관관계를 측정하여 TDA 기법의 정확도를 평가하는 핵심 지표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM의 예측 결과를 학습 데이터로 거슬러 올라가 추적하는 TDA의 계산 효율성과 이론적 한계를 해결하고자 합니다. 기존의 Gradient-based 방식은 수십억 개의 파라미터를 다루기 위해 과도한 메모리와 컴퓨팅 자원을 소모하며, Representation-based 방식은 휴리스틱한 유사도에 의존하여 인과적 근거가 부족하다는 문제점이 있습니다. 특히, 데이터 서브셋에 기반한 반복적인 retraining은 LLM 규모에서 불가능에 가깝습니다. 저자들은 파라미터 변화가 아닌 Activation-space에서의 함수적 변화를 모델링함으로써, Retraining 수준의 인과성을 유지하면서도 압도적인 효율성을 확보하는 새로운 프레임워크를 제안합니다. [Figure 1]

Figure 1 — 모델 예측과 학습 데이터 간의 인과적 추적 예시
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문이 제안하는 STRIDE(Steering-based Training Data Influence Decomposition)는 학습 데이터를 Sparse Recovery 문제로 재정의하여 접근합니다. 첫째, 임의의 데이터 서브셋 학습 효과를 모사하는 저차원 Steering Operators를 학습시키고, 이를 통해 서브셋별 예측 변화를 효율적으로 측정합니다. 둘째, 측정된 결과들로부터 Compressive Sensing 원리를 이용해 개별 데이터 사례의 Influence를 복원합니다. 이 과정에서 Fidelity Loss, Stability Loss, Linearity Loss(LDS)를 결합한 목적 함수를 사용하여 연산자를 최적화합니다. [Figure 2]
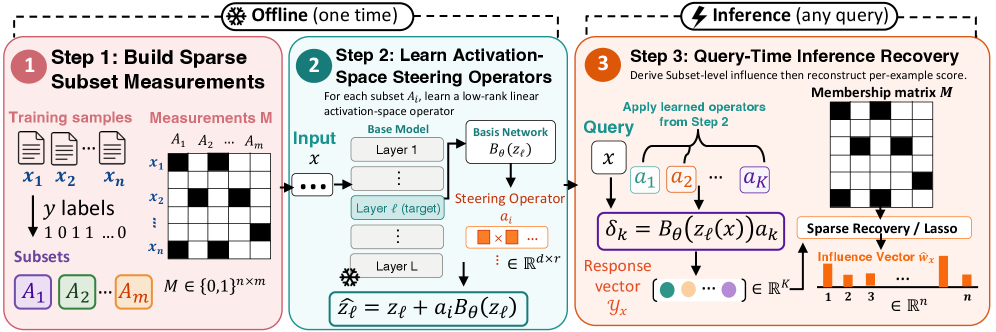
Figure 2 — STRIDE의 학습 및 복원 파이프라인
실험 결과, STRIDE는 LLM pre-training attribution 작업에서 가장 높은 LDS를 기록하며 기존 기법들 대비 성능 우위를 점했습니다. 또한, STRIDE는 최신 베이스라인 모델 대비 12x 이상의 속도 향상을 달성하며 탁월한 계산 효율성을 입증했습니다. 이 기법은 데이터 선택, 오염 탐지 및 정성적 분석 등 실질적인 downstream application에서도 강력한 성능을 보입니다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Activation-space에서 데이터의 인과적 영향력을 모델링하는 STRIDE를 통해 효율적인 TDA의 새로운 패러다임을 제시합니다. 이 연구는 LLM의 내부 동작을 투명하게 규명하고 모델의 신뢰성을 높이는 데 중요한 도구로 활용될 것입니다. 특히, 파라미터 규모에 구애받지 않는 확장성을 확보함으로써 향후 거대 모델의 데이터 감사 및 품질 최적화 연구 분야에 학계와 산업계 모두에 큰 시사점을 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] ToolSense: A Diagnostic Framework for Auditing Parametric Tool Knowledge in LLMs
- [논문리뷰] EvoBrowseComp: Benchmarking Search Agents on Evolving Knowledge
- [논문리뷰] ArogyaSutra: A Multi-Agent Framework for Multimodal Medical Reasoning in Indic Languages
- [논문리뷰] Online Skill Learning for Web Agents via State-Grounded Dynamic Retrieval
- [논문리뷰] Kwai Keye-VL-2.0 Technical Report
Review 의 다른글
- 이전글 [논문리뷰] Reproducing, Analyzing, and Detecting Reward Hacking in Rubric-Based Reinforcement Learning
- 현재글 : [논문리뷰] STRIDE: Training Data Attribution via Sparse Recovery from Subset Perturbations
- 다음글 [논문리뷰] Score-Control for Hallucination Reduction in Diffusion Models
댓글