[논문리뷰] SpatialAct: Probing Spatial Reasoning-to-Action Capabilities of VLM Agents in 3D Scenes
링크: 논문 PDF로 바로 열기
메타데이터
저자: Tianhui Liu, Jie Feng, Zhiheng Zheng, Shengyuan Wang, Yiming Guo, Yanxin Xi, Hangyu Fan, Yong Li, Pan Hui
1. Key Terms & Definitions (핵심 용어 및 정의)
- Action-Conditioned Spatial Reasoning: 모델이 현재의 공간 상태를 파악하는 것을 넘어, 자신의 행동이 환경을 어떻게 변화시키는지 추론하고, 그에 따라 향후 결정을 업데이트하는 능력을 의미합니다.
- Multi-turn Interactive Refinement: 3D 환경 내 비정상적인 레이아웃을 발견하고, 반복적인 행동(Action)을 통해 이를 점진적으로 수정해 나가는 폐루프(Closed-loop) 환경 기반의 작업입니다.
- Reasoning-to-Action Gap: VLM이 정적인 공간 추론 작업에서는 높은 성능을 보이지만, 실제 환경 변화를 수반하는 다단계 행동 수행 시에는 성능이 급격히 저하되는 불일치 현상을 지칭합니다.
- Simulator-Grounded Benchmark: 고정된 데이터셋이 아니라, 3D 시뮬레이터와 연동되어 모델의 행동 결과에 따른 환경 피드백을 실시간으로 반영하여 평가하는 벤치마크 프레임워크입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 VLM이 단순한 공간 관찰을 넘어 실제 3D 환경에서 행동하고 그 결과를 관리할 수 있는지 평가하기 위해 SpatialAct를 제안한다. 기존의 공간 추론 벤치마크들은 대부분 정적인 이미지나 비디오를 대상으로 모델의 이해도만을 측정하며, 모델의 출력이 환경을 변화시키는 상호작용은 고려하지 않았다 [Table 1]. 반면, Embodied AI 분야는 실제 로봇 제어와 같은 저수준 제어와 고수준 추론이 혼재되어 있어 순수한 공간 추론 능력을 분리해 평가하기 어렵다. 이에 따라 저자들은 고수준의 의미론적 행동(move, rotate, scale 등)을 통해 공간 상태를 수정하고, 이를 시뮬레이터가 검증하는 단계적이고 체계적인 평가 환경의 필요성을 강조한다 [Figure 1].
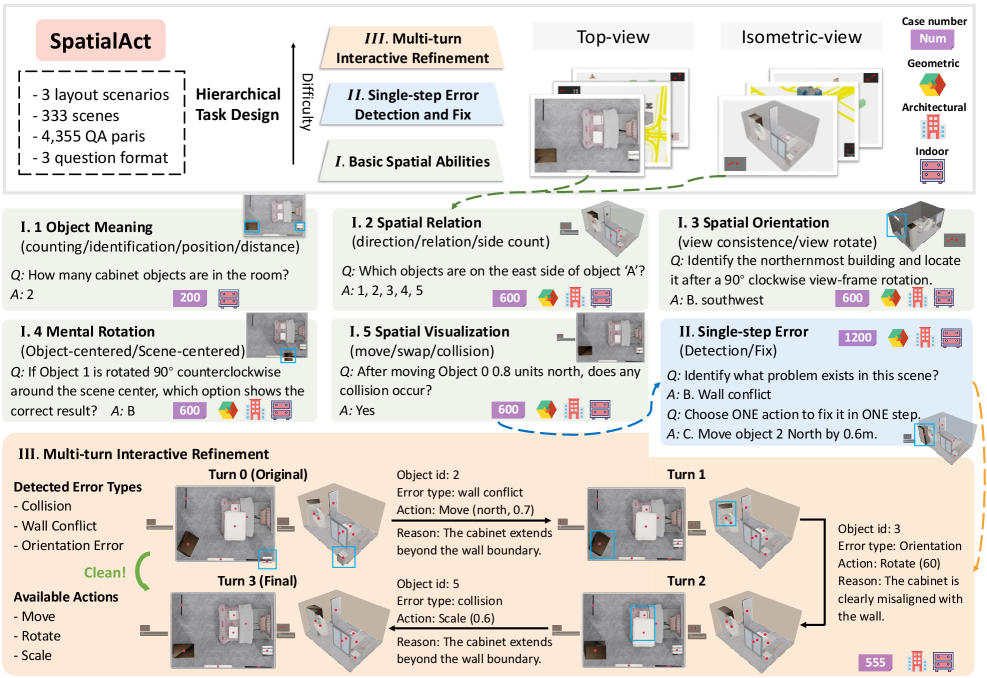
Figure 1 — SpatialAct의 3계층 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 SpatialAct를 통해 세 가지 계층(Basic Spatial Abilities, Single-step Error Detection and Fix, Multi-turn Interactive Refinement)으로 구성된 진단형 벤치마크를 제안한다. 연구진은 333개의 장면과 4,355개의 QA 쌍을 구축하였으며, 모델이 시뮬레이터와 상호작용하며 레이아웃을 수정하도록 설계하였다 [Figure 2]. 주요 정량적 결과로, Gemini-3.1 Pro는 Multi-turn Interactive Refinement에서 Repair Rate 0.411, Scene Success Rate 0.206을 기록하며 최상위 성능을 보였으나, 인간 참여자의 기록(Repair Rate 0.911, Scene Success Rate 0.763)과 비교할 때 현격한 차이가 존재함을 확인하였다 [Table 2]. 실험 결과, 모델들은 단일 단계 추론(Basic Abilities)에서는 강점을 보이나, 다단계 상호작용 시에는 일관된 공간 상태 유지에 실패하며, 특히 회전(Orientation) 오류 대비 충돌(Conflict) 오류 수정에서 취약한 모습을 보였다 [Figure 5]. 추가적인 분석을 통해 문맥(Context Window)의 확대가 단순히 추론의 분량만 늘릴 뿐, 실질적인 수정 품질(Repair Quality) 향상으로 이어지지는 않는다는 점을 밝혀냈다 [Figure 6].
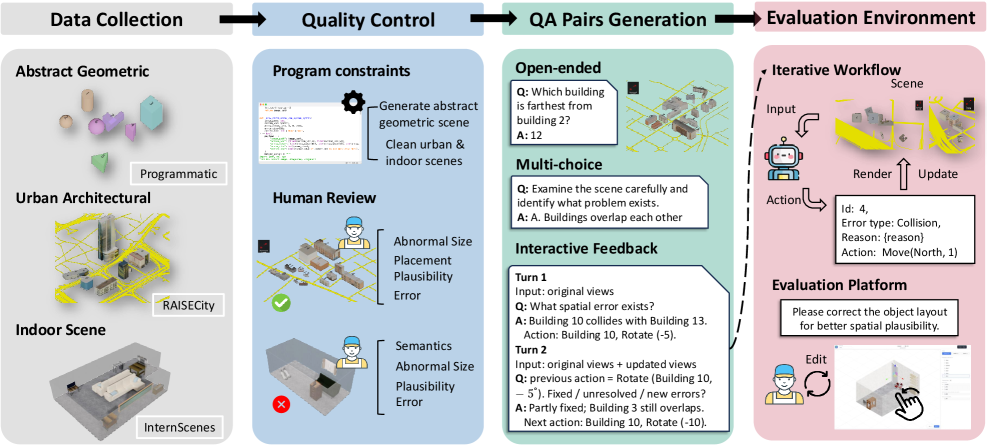
Figure 2 — 벤치마크 구축 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 논문은 현재의 VLM 에이전트들이 공간 추론과 행동 간의 강력한 결합을 구현하는 데 있어 여전히 한계가 있음을 입증하였다. 연구 결과는 단순한 인식 능력을 넘어, 복잡한 3D 환경 내에서 다단계 상태 변화를 추적하고 수정할 수 있는 에이전트 중심의 모델링이 필요함을 시사한다. 이 벤치마크는 향후 Embodied AI 에이전트의 공간 지능을 체계적으로 개선하고 평가하기 위한 중요한 도구로 활용될 것으로 기대된다. 또한, 저자들은 해당 데이터셋과 시뮬레이터 워크플로우를 오픈소스로 공개하여 학계의 후속 연구를 지원할 예정이다.
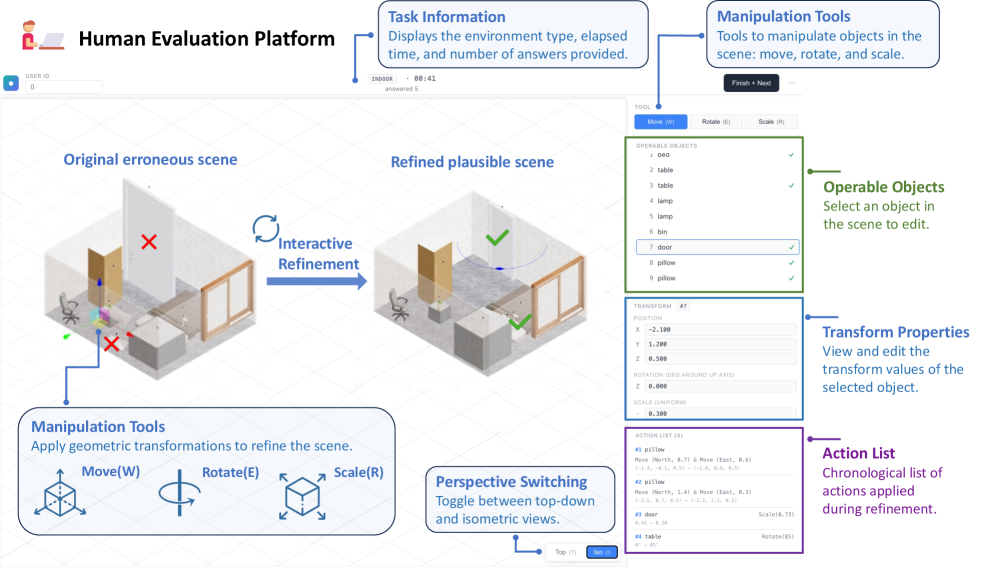
Figure 3 — 인터랙티브 평가 인터페이스
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] OmniGameArena: A Unified UE5 Benchmark for VLM Game Agents with Improvement Dynamics
- [논문리뷰] Skill-3D: Evolving Scene-Aware Skills for Agentic 3D Spatial Reasoning
- [논문리뷰] CoVEBench: Can Video Editing Models Handle Complex Instructions?
- [논문리뷰] WorldBench: A Challenging and Visually Diverse Multimodal Reasoning Benchmark
- [논문리뷰] When Tools Fail: Benchmarking Dynamic Replanning and Anomaly Recovery in LLM Agents
Review 의 다른글
- 이전글 [논문리뷰] Semi-Supervised Noise Adaptation: Transferring Knowledge from Noise Domain
- 현재글 : [논문리뷰] SpatialAct: Probing Spatial Reasoning-to-Action Capabilities of VLM Agents in 3D Scenes
- 다음글 [논문리뷰] Stable-Layers: Fine-Tuning Image Layer Decomposition Models with VLM-Scored Reinforcement Learning
댓글