[논문리뷰] LoomVideo: Unifying Multimodal Inputs into Video Generation and Editing
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jianzong Wu, Hao Lian, Jiongfan Yang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Deepstack: MLLM의 모든 레이어에서 hidden states를 추출하여 DiT의 대응되는 레이어에 cross-attention 방식으로 주입하는 다중 레이어 feature 정렬 메커니즘입니다.
- Scale-and-Add: 소스 비디오 latent를 timestep에 따라 스케일링하여 타겟 노이즈 latent에 직접 더함으로써, 토큰 연결(concatenation) 없이 효율적으로 비디오 편집을 수행하는 conditioning 방식입니다.
- Negative Temporal RoPE: 다중 reference 이미지를 식별하기 위해 일반 프레임과 구별되는 음수 인덱스를 부여하는 위치 인코딩 전략입니다.
- DiT (Diffusion Transformer): 비디오 생성 및 편집을 위한 기반 아키텍처로, 본 연구에서는 5B 파라미터 규모의 모델이 사용되었습니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 기존 Unified Video Generation 모델들이 대규모 파라미터(13B 이상)에 의존하고, 비디오 편집 시 소스 토큰 연결로 인해 연산 비용이 기하급수적으로 증가하는 문제를 해결하고자 합니다. 기존 방식은 시퀀스 길이를 2배로 늘려 self-attention의 연산 복잡도를 4배로 증가시켜, 추론 속도와 리소스 효율성 측면에서 심각한 병목 현상을 초래합니다. 이러한 한계를 극복하기 위해 본 연구는 보다 가볍고 효율적인 통합 아키텍처를 구축하는 것을 목표로 합니다. [Figure 2]는 이러한 효율적인 아키텍처 설계를 시각적으로 보여줍니다.
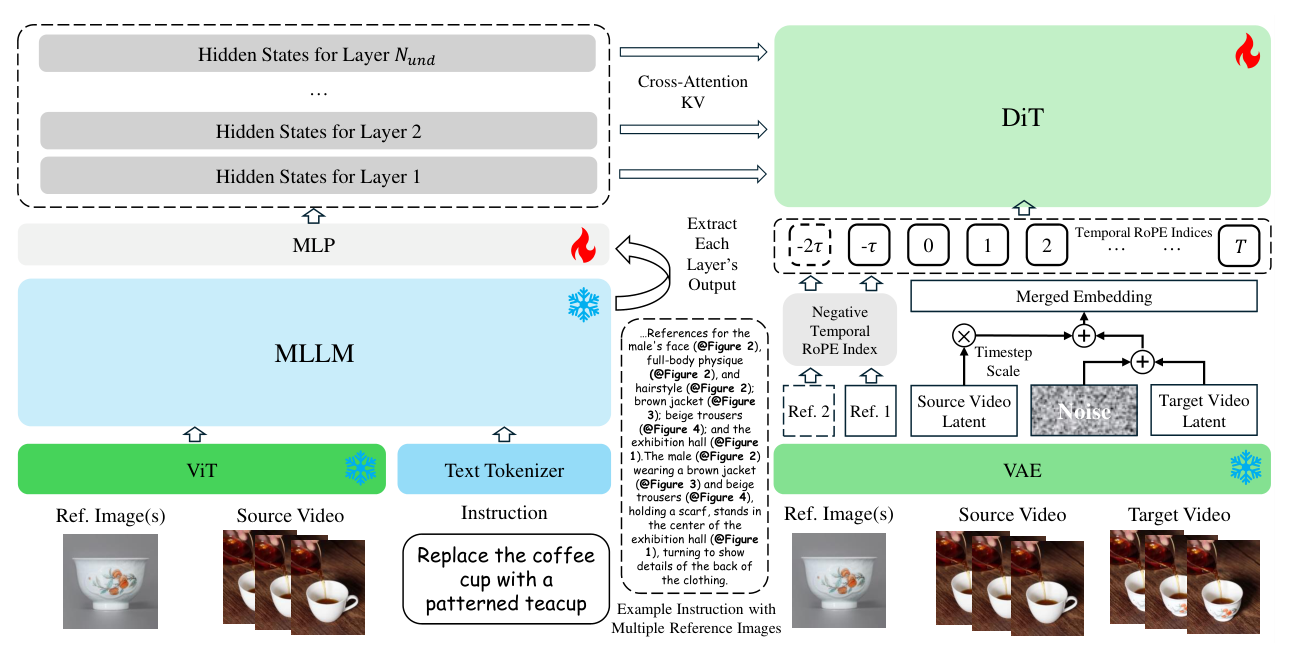
Figure 2 — 제안된 Deepstack injection, Scale-and-Add, Negative Temporal RoPE 등 핵심 기술이 적용된 전체 아키텍처 다이어그램
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 5B 파라미터의 Wan 2.2 TI2V를 기반으로, Qwen3-VL을 결합하여 효율적인 다중 모달 통합 프레임워크인 LoomVideo를 제안합니다. 제안된 Deepstack injection은 Hierarchical semantic 정보를 효과적으로 활용하며, Scale-and-Add conditioning은 추가 토큰 없이 latent 레벨에서 직접 조작을 수행하여 연산 효율을 극대화합니다. 또한, 학습 단계는 MLLM 정렬, 해상도 확대 및 재구성, 다중 작업 미세 조정의 3단계로 구성되며 Reinforcement Learning (RL)을 통해 품질을 향상합니다. 정량적 실험 결과, LoomVideo는 기존의 토큰 연결 기반 모델 대비 최소 **5.41×**의 추론 속도 가속을 달성하였습니다. [Table 2]에서 볼 수 있듯이, LoomVideo (RL) 모델은 VBench 벤치마크에서 63.15의 평균 점수를 기록하며 우수한 성능을 입증했습니다. 특히, [Table 8]의 추론 시간 비교 데이터는 제안 모델이 기존 SOTA 모델 대비 비디오 편집(TV2V) 작업에서 월등한 효율성을 가짐을 보여줍니다.
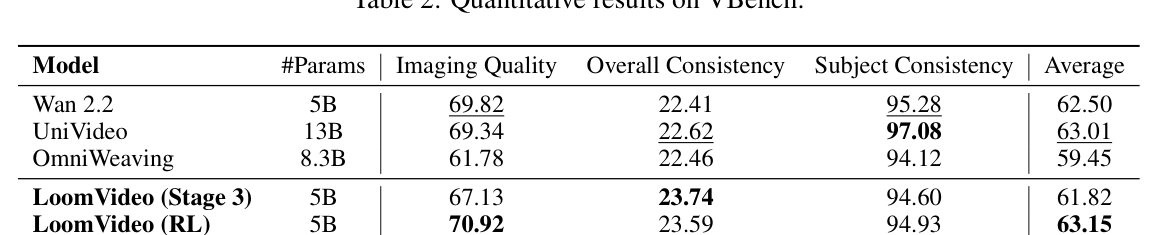
Table 2 — 기존 SOTA 모델들과 제안 모델의 벤치마크 성능 비교

Table 8 — 추론 속도(T2V 및 TV2V)의 비교를 통해 제안 방법론의 효율성을 극적으로 보여주는 핵심 데이터
4. Conclusion & Impact (결론 및 시사점)
본 연구는 LoomVideo를 통해 고효율 5B-parameter 통합 아키텍처가 복잡한 비디오 생성 및 편집 작업을 효과적으로 수행할 수 있음을 입증하였습니다. 특히, 제안된 경량 conditioning 메커니즘은 상용 서비스의 실질적인 비용 절감과 성능 최적화에 기여할 것으로 기대됩니다. 이번 연구는 향후 더 높은 해상도와 긴 지속 시간의 비디오 생성으로 확장 가능한 Foundation Model로서의 가능성을 제시하며, 학계와 산업계 모두에 실용적인 가이드라인을 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] UniVBench: Towards Unified Evaluation for Video Foundation Models
- [논문리뷰] DreaMontage: Arbitrary Frame-Guided One-Shot Video Generation
- [논문리뷰] Kling-Omni Technical Report
- [논문리뷰] V-RGBX: Video Editing with Accurate Controls over Intrinsic Properties
- [논문리뷰] Exploring MLLM-Diffusion Information Transfer with MetaCanvas
Review 의 다른글
- 이전글 [논문리뷰] Latent Reasoning with Normalizing Flows
- 현재글 : [논문리뷰] LoomVideo: Unifying Multimodal Inputs into Video Generation and Editing
- 다음글 [논문리뷰] MLEvolve: A Self-Evolving Framework for Automated Machine Learning Algorithm Discovery
댓글