[논문리뷰] HarnessForge: Joint Harness and Policy Evolution for Adaptive Agent Systems
링크: 논문 PDF로 바로 열기
메타데이터
저자: Mingju Chen, Can Lv, Guibin Zhang, Heng Chang, Shiji Zhou
1. Key Terms & Definitions (핵심 용어 및 정의)
- Harness: LLM agent 시스템의 외부 실행 인터페이스를 의미하며, planning(작업 분해), action(도구 사용 및 역할 정의), memory(상태 및 기록 관리) 컴포넌트로 구성됩니다.
- Policy ($\mathcal{R}_{\delta}$): Harness 내에서 환경과 상호작용하며 추론 및 실행을 수행하는 내부 모델의 reasoning 동작을 정의합니다.
- Co-evolution: 외부 harness의 구조와 내부 reasoning policy를 독립적으로 최적화하는 대신, 상호 호환성을 극대화하기 위해 결합된 harness–policy pair를 동시에 진화시키는 메타 적응 기법입니다.
- Fault-Guided Harness Tailoring: Meta-agent를 활용하여 실행 로그를 분석하고, 실패 지점을 식별하여 harness 컴포넌트를 반복적으로 수정하는 최적화 프로세스입니다.
- Harness-Conditioned Policy Alignment: 특정 harness 환경에 특화된 적응형 adapter(LoRA 등)를 학습시켜, reasoner가 해당 harness의 인터페이스와 제약 조건을 충실히 따르도록 보정하는 단계입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM agent 시스템의 Meta-adaptation을 수행할 때 발생하는 '실행 호환성(Executable Compatibility) 결여' 문제를 해결합니다. 기존 연구들은 외부 harness를 최적화하거나 내부 policy를 훈련하는 방식을 각각 개별적으로 다루어 왔으나, 이로 인해 harness가 노출하는 구조와 모델의 reasoning 능력 사이의 부조화가 발생합니다 [Figure 1]. 저자들은 복잡하고 다양한 작업 환경에서 고성능을 발휘하기 위해서는 harness와 policy가 일체화된 'harness–policy pair'를 adaptation의 기본 단위로 설정해야 한다고 주장합니다. 이러한 시스템 수준의 통합적 접근이 부재할 경우, 강력한 harness를 갖추더라도 모델이 이를 제대로 활용하지 못하거나, 반대로 고성능 모델이 부적절한 harness에 의해 제약받는 한계가 존재합니다.
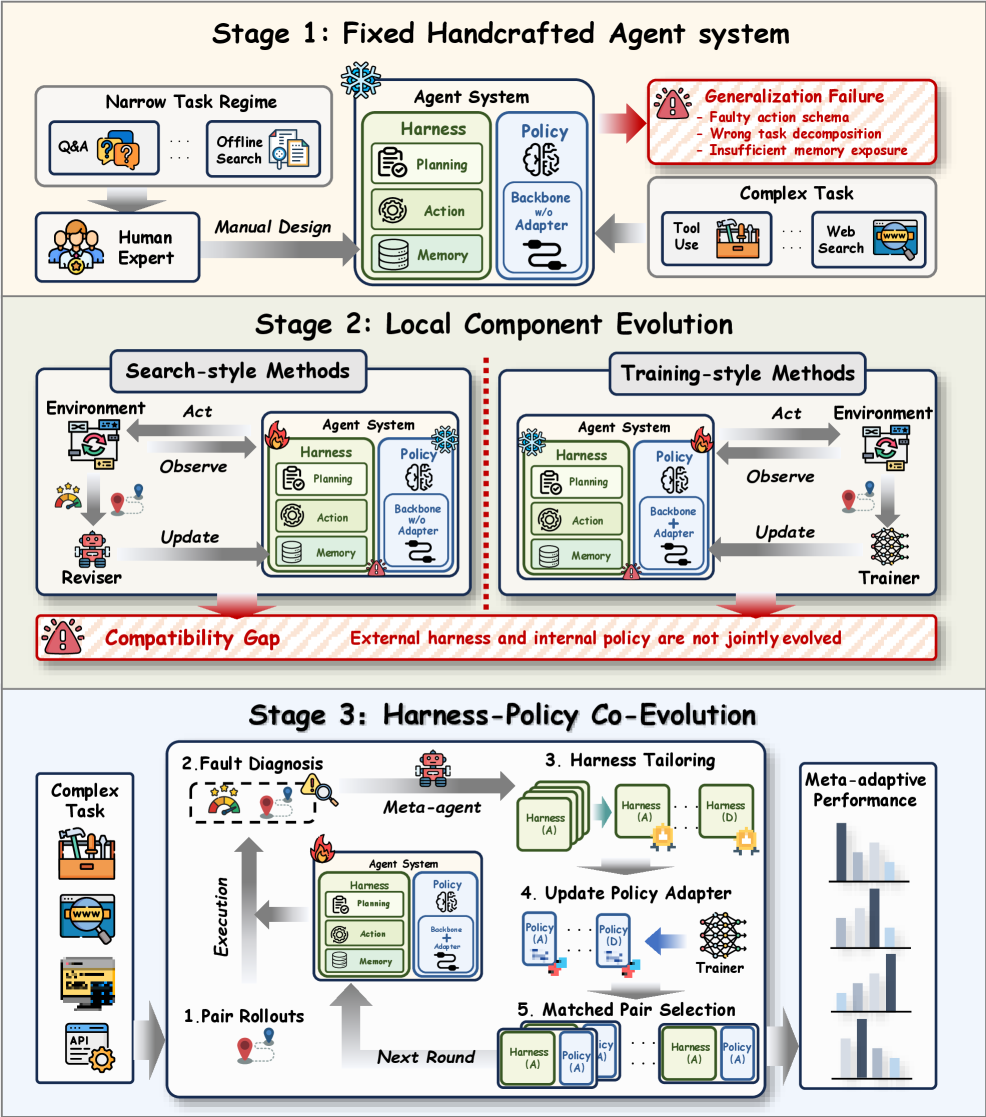
Figure 1 — LLM 에이전트 적응의 3단계 변화
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 HarnessForge라는 메타 적응형 co-evolution 프레임워크를 제안하여, harness-policy pair를 반복적으로 개선합니다 [Figure 2]. 이 방법론은 크게 세 단계로 진행됩니다: 첫째, 실행 중 발생한 오류를 기반으로 harness의 planning, action, memory 모듈을 수정하는 Fault-Guided Harness Tailoring을 수행합니다. 둘째, 수정된 harness 환경에서 수집된 성공 궤적을 바탕으로 Harness-Conditioned Policy Alignment를 통해 policy를 harness 구조에 맞게 최적화합니다. 셋째, 이 과정을 반복하며 가장 적합한 harness-policy 쌍을 선택 및 진화시킵니다 [Figure 2]. 실험 결과, HarnessForge는 Qwen3-4B 및 Qwen3-8B backbone을 활용한 5개 벤치마크 테스트에서 기존의 harness-only 또는 policy-only 베이스라인 대비 평균 3.56% 향상된 성능을 기록했으며, 최대 12.0%의 성능 개선을 달성했습니다 [Table 1]. 특히, 적절한 rollout 효율성을 유지하면서도 harness와 reasoning policy 간의 실행 호환성을 극대화하여 실제 작업 성공률(Success Rate)에서 독보적인 우위를 보였습니다.
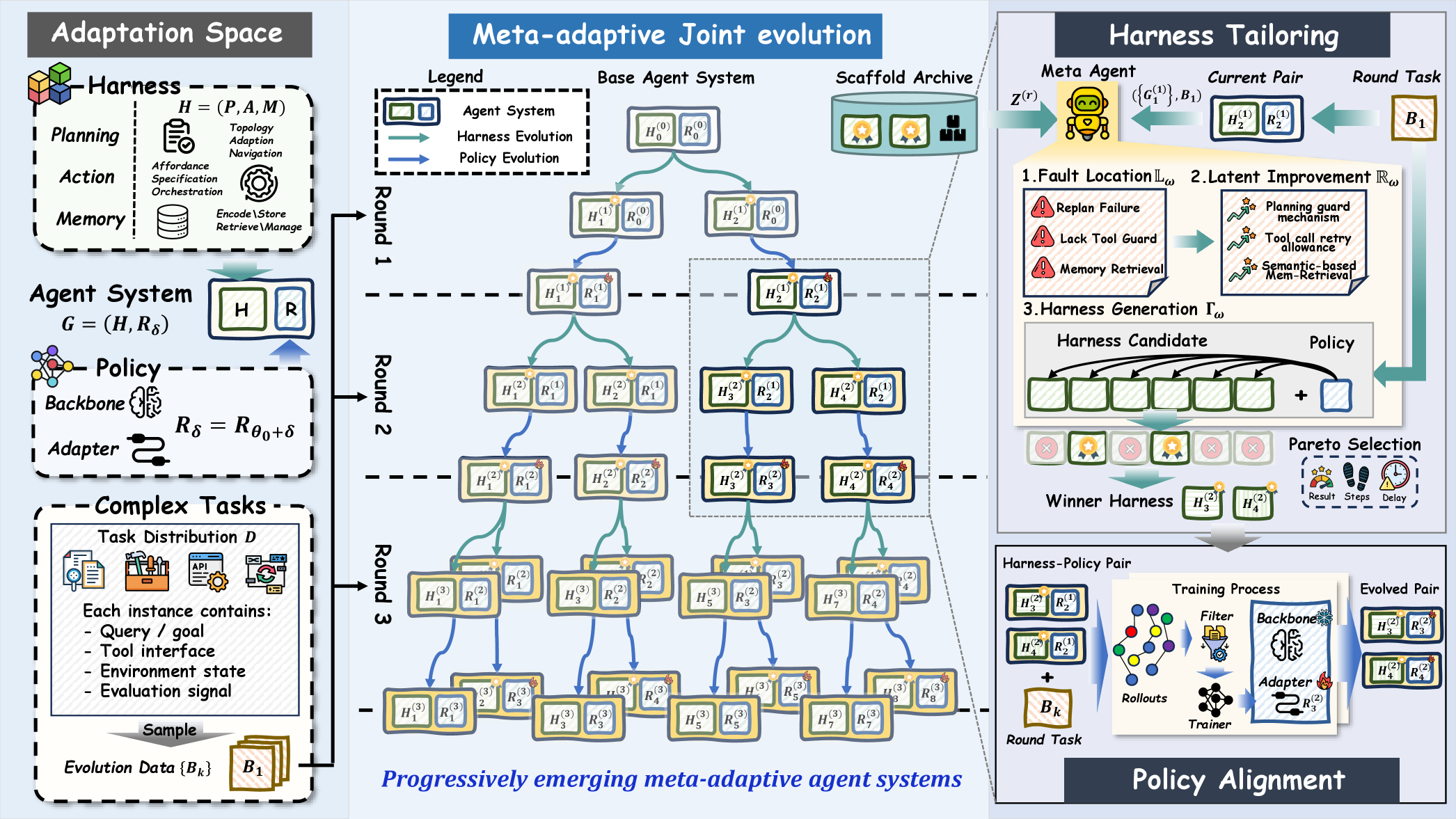
Figure 2 — HarnessForge의 co-evolution 워크플로우
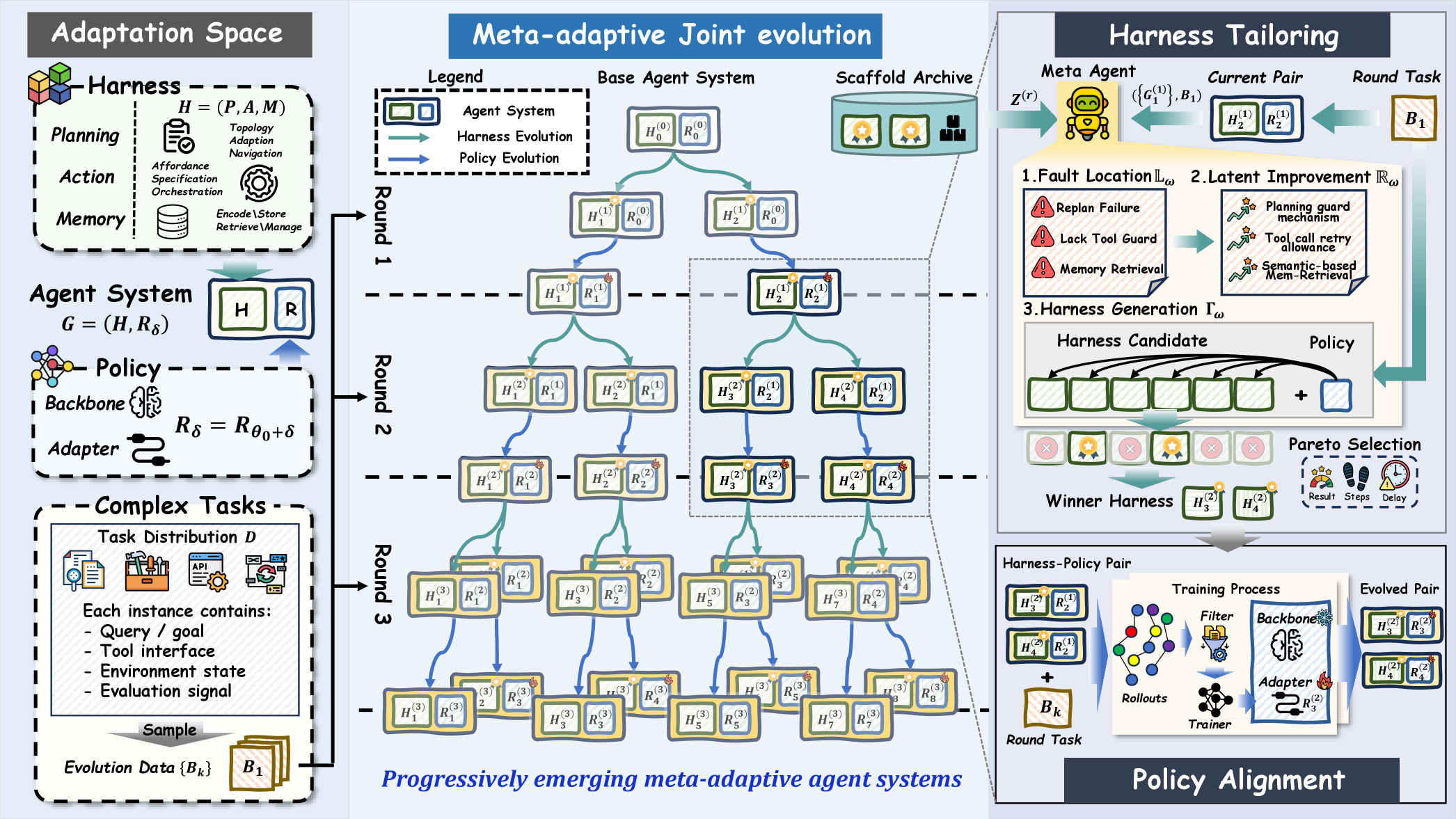
Table 1 — 다양한 벤치마크에서의 주요 성능 결과
4. Conclusion & Impact (결론 및 시사점)
본 논문은 LLM agent adaptation의 핵심이 개별 컴포넌트의 개선이 아닌, harness와 policy의 조화로운 동반 진화에 있음을 입증합니다. HarnessForge 프레임워크는 harness를 단순히 고정된 도구로 보는 관점에서 벗어나, 학습 가능한 시스템의 필수 요소로 격상시켰다는 점에서 의미가 큽니다. 이 연구는 산업계 및 학계에서 LLM agent를 다양한 도메인에 신속하고 효과적으로 적응시켜야 하는 상황에서 중요한 기술적 로드맵을 제공합니다. 향후 연구는 더욱 복잡한 다중 에이전트(Multi-agent) 시스템이나 더 긴 호라이즌을 가진 작업에서 이 co-evolution 방식이 어떻게 확장될 수 있는지에 집중할 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Evoflux: Inference-Time Evolution of Executable Tool Workflows for Compact Agents
- [논문리뷰] EvoArena: Tracking Memory Evolution for Robust LLM Agents in Dynamic Environments
- [논문리뷰] Role-Agent: Bootstrapping LLM Agents via Dual-Role Evolution
- [논문리뷰] Retrospective Harness Optimization: Improving LLM Agents via Self-Preference over Trajectory Rollouts
- [논문리뷰] LatentSkill: From In-Context Textual Skills to In-Weight Latent Skills for LLM Agents
Review 의 다른글
- 이전글 [논문리뷰] GENEB: Why Genomic Models Are Hard to Compare
- 현재글 : [논문리뷰] HarnessForge: Joint Harness and Policy Evolution for Adaptive Agent Systems
- 다음글 [논문리뷰] How Far Can Chord-Symbol Time-Series Adaptation Carry Genre Identity? Capabilities and Boundaries in Multi-Genre Chord-Symbol Modeling
댓글