[논문리뷰] OmniCap-IF: Benchmarking and Improving Instruction Following Abilities for Omni-Video Captioning
링크: 논문 PDF로 바로 열기
저자: Jiahao Wang, An Ping, Yanghai Wang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Omni-modal Large Language Models (OLLMs): Text, Audio, Visual 스트림을 동시에 처리하고 추론할 수 있는 능력을 갖춘 최신 멀티모달 모델을 의미합니다.
- Instruction Following (IF): 모델이 사용자의 복잡하고 다면적인 제약 조건(Constraints)을 정확하게 파악하고 출력물에 엄격하게 반영하는 능력을 지칭합니다.
- Constraint Framework: 사용자가 부여한 제약 조건을 50개의 유형으로 체계화하여, Format과 Content 차원에서 모델의 수행 능력을 평가하는 체계입니다.
- Temporal Grounding: 영상 내 특정 이벤트나 행동이 발생하는 정확한 시간 구간(timestamp)을 모델이 식별하고 응답에 포함하도록 요구하는 제약 기술입니다.
- Format-Content Tradeoff: 구조적(Format) 제약 조건의 복잡도가 증가함에 따라, 모델의 근본적인 오디오-비주얼 내용 추론(Content) 능력이 저하되는 현상을 의미합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Omni-modal 모델들이 복잡한 사용자 지시 사항을 준수하는 능력인 Instruction Following에 대한 체계적인 평가 도구가 부족하다는 점을 해결하고자 합니다. 기존 벤치마크들은 주로 전체적인 비디오 이해나 단일 모달리티에 집중되어 있어, 오디오와 비디오를 아우르는 정교한 제약 조건을 다루지 못한다는 한계가 있습니다 [Figure 1]. 또한, 엄격한 출력 형식 준수를 요구할 때 모델의 멀티모달 추론 성능이 어떻게 변화하는지에 대한 연구가 미진하여, 이를 규명하고 개선하는 것이 시급합니다.

Figure 1 — 평가 프레임워크 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 50개의 제약 조건 유형을 포함하는 OmniCap-IF 벤치마크를 구축하고, 구조적 준수 여부와 내용적 정확성을 분리하여 평가하는 프로토콜을 제안합니다 [Figure 1]. 1,920개의 고품질 샘플을 사용하여 14개의 주요 모델을 평가한 결과, 모델의 크기가 커질수록 성능이 향상되는 경향을 보였으나, Audio-Visual 동시 추론에서 성능 저하가 뚜렷함을 확인하였습니다 [Table 2]. 특히, 연구진은 'Format-Content Tradeoff'를 실증적으로 입증하였으며, 이를 극복하기 위해 제안한 54K 규모의 OmniCap-IF-54K 데이터셋을 통한 fine-tuning이 효과적임을 증명했습니다 [Figure 3]. 결과적으로, 학습된 모델인 OmniCaptioner-IF-7B는 Gemini-3.1-Pro와 대등한 수준의 구조적 제어 성능을 달성하며 기존 모델 대비 전반적인 omni-modal 이해 능력을 크게 향상시켰습니다 [Table 2].
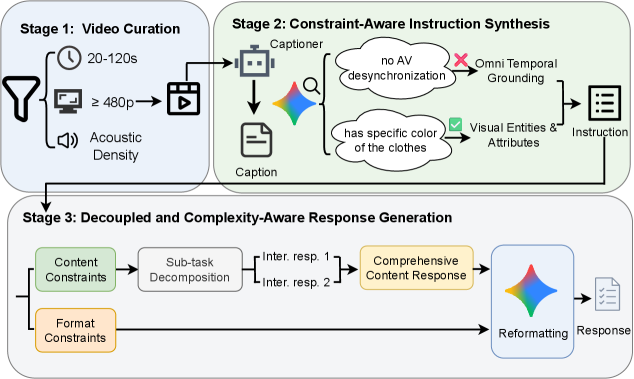
Figure 3 — 학습 데이터 생성 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 논문은 최초의 Omni-modal Instruction Following 벤치마크인 OmniCap-IF를 도입하여, 해당 분야의 평가 표준을 한 단계 격상시켰습니다. 본 연구에서 밝혀낸 'Format-Content Tradeoff'는 향후 controllable generation 모델 개발 시 구조적 제약과 내용적 품질 사이의 균형을 맞추는 중요한 이정표가 될 것입니다. 제안된 OmniCaptioner-IF는 실제 복잡한 멀티모달 보조 도구(Assistant) 개발에 필요한 실무적 지침과 방법론을 제공하며, 학계 및 산업계의 제어 가능한 멀티모달 모델 연구를 가속화할 것으로 기대됩니다.
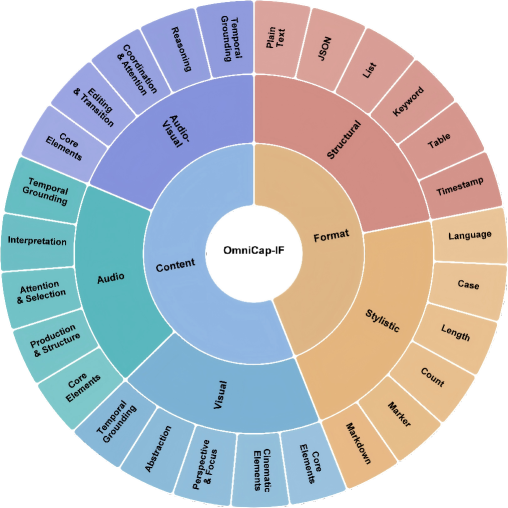
Figure 2 — 데이터셋 통계 및 제약 카테고리
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Towards Universal Video MLLMs with Attribute-Structured and Quality-Verified Instructions
- [논문리뷰] Video-Thinker: Sparking 'Thinking with Videos' via Reinforcement Learning
- [논문리뷰] IF-VidCap: Can Video Caption Models Follow Instructions?
- [논문리뷰] Skill-RM: Unifying Heterogeneous Evaluation Criteria via Agent Skill
- [논문리뷰] Watch, Remember, Reason: Human-View Video Understanding with MLLMs
Review 의 다른글
- 이전글 [논문리뷰] OASIS: From Simulation Data Collection to Real-World Humanoid Loco-Manipulation
- 현재글 : [논문리뷰] OmniCap-IF: Benchmarking and Improving Instruction Following Abilities for Omni-Video Captioning
- 다음글 [논문리뷰] OmniGameArena: A Unified UE5 Benchmark for VLM Game Agents with Improvement Dynamics
댓글