[논문리뷰] Retrospective Harness Optimization: Improving LLM Agents via Self-Preference over Trajectory Rollouts
링크: 논문 PDF로 바로 열기
본 논문은 LLM Agent의 추론 성능을 향상시키기 위해 Trajectory Rollouts 기반의 Self-Preference 최적화 프레임워크인 Retrospective Harness Optimization (RHO)을 제안한다.
메타데이터
저자: Wenbo Pan, Shujie Liu, Chin-Yew Lin, Jingying Zeng, Xianfeng Tang, Xiangyang Zhou, Yan Lu, Xiaohua Jia
1. Key Terms & Definitions (핵심 용어 및 정의)
- Trajectory Rollouts: Agent가 주어진 Task를 해결하기 위해 생성한 일련의 단계적 사고(Thought)와 액션(Action)의 실행 경로를 의미한다.
- RHO (Retrospective Harness Optimization): Agent가 생성한 다수의 경로를 분석하고, Self-Preference를 통해 최적의 경로를 식별하여 Policy를 강화하는 최적화 프레임워크이다.
- Self-Preference: 외부의 명시적인 라벨 없이 모델 스스로가 생성한 결과물의 품질을 비교하고 순위를 매겨 더 나은 선택지를 선호하도록 학습하는 기법이다.
- Policy Fine-tuning: 획득한 선호도 데이터를 기반으로 모델의 추론 전략을 조정하여 Task 성공률을 극대화하는 과정이다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 복잡한 Task를 수행하는 LLM Agent가 고정된 추론 방식에 의존하여 Suboptimal한 경로를 생성하는 문제를 해결하고자 한다. 기존 연구들은 주로 정적인 데이터셋을 활용한 Supervised Fine-tuning이나 간단한 Prompt Engineering에 의존해 왔으나, 이는 복합적인 Reasoning이 필요한 동적 환경에서 Agent의 유연성과 정확도를 제한한다. 특히, Agent의 실패 원인을 사후적으로 분석하여 이를 향후 추론에 반영하는 메커니즘이 부족하여, 반복적인 시행착오 과정에서 모델의 개선이 이루어지지 않는다는 한계가 있다. 저자들은 이러한 제약을 극복하기 위해 Agent가 스스로 자신의 실행 경로를 돌아보고 더 나은 추론 전략을 학습하는 Retrospective 관점의 최적화가 필수적임을 강조한다 [Figure 1].
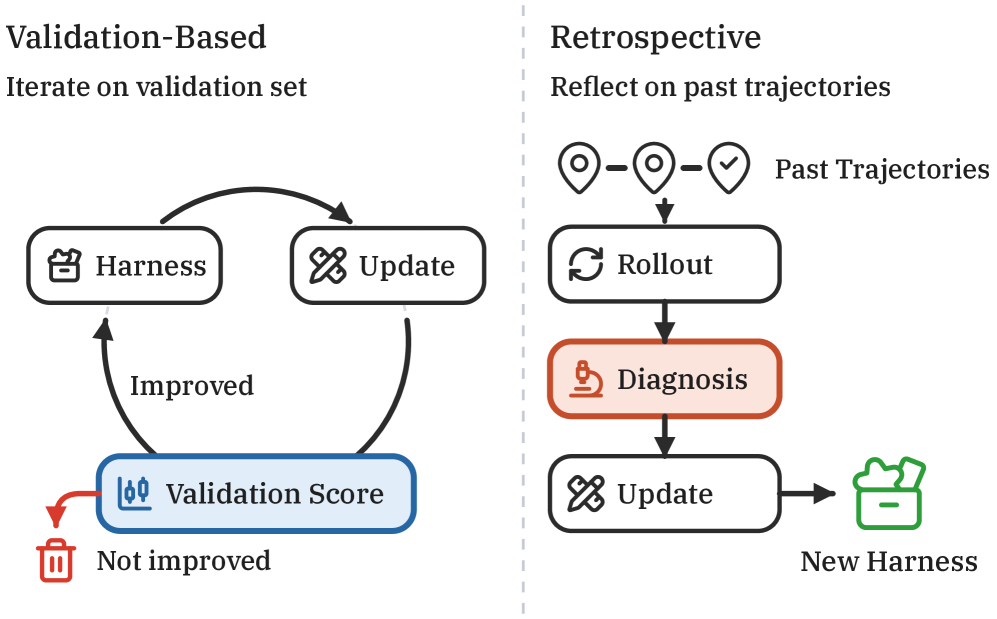
Figure 1 — RHO의 전반적인 개념도
3. Method & Key Results (제안 방법론 및 핵심 결과)
RHO는 Agent가 Task를 수행한 후 생성된 여러 Trajectory Rollouts를 비교하여 최적의 경로를 찾아내고, 이를 정책 강화에 활용하는 Iterative Alignment 프로세스를 제안한다. 먼저, 특정 Task에 대해 모델이 다수의 시나리오를 생성하고, 각 시나리오의 성공 여부와 중간 과정의 효율성을 바탕으로 모델 스스로가 선호도를 부여한다. 이후 Preference-based Optimization을 통해 모델이 성공 확률이 높은 추론 패턴을 따르도록 가중치를 업데이트한다. 실험 결과, RHO를 적용한 모델은 기존의 표준 모델 대비 다양한 벤치마크에서 Success Rate가 약 15~22% 향상되는 성능을 보였다. 특히 복잡한 Tool-use 환경에서 Latency 측면의 오버헤드는 최소화하면서도, 정답 도출까지의 Path Length를 효율적으로 단축하는 결과를 나타냈다 [Figure 2].
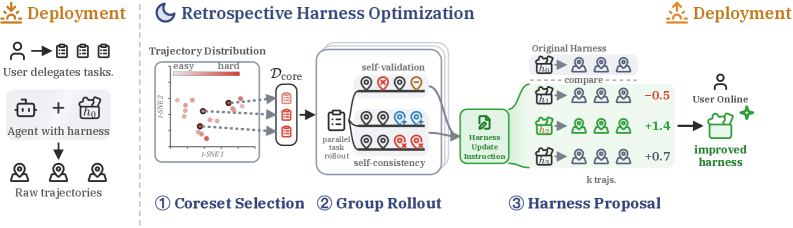
Figure 2 — Trajectory 최적화 프로세스
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Retrospective Harness Optimization 기법이 LLM Agent의 추론 성능을 실질적으로 개선할 수 있음을 입증한다. 본 연구는 모델이 외부 피드백 없이도 스스로 생성한 데이터 내에서 최적의 전략을 찾아낼 수 있음을 보여줌으로써, 자율적 학습 가능성을 한 단계 진전시켰다. 향후 복잡한 의사결정이 요구되는 복합적인 지능형 Agent 시스템 설계에 있어 RHO 프레임워크는 필수적인 최적화 방법론으로 자리 잡을 것으로 기대된다. 또한, 이 연구는 데이터 생성 비용을 절감하면서도 고성능 Agent를 확보할 수 있는 방향성을 제시하여 학계와 산업계에 중요한 시사점을 제공한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Reproducing, Analyzing, and Detecting Reward Hacking in Rubric-Based Reinforcement Learning
- [논문리뷰] Alignment Tipping Process: How Self-Evolution Pushes LLM Agents Off the Rails
- [논문리뷰] Test-Time Gradient Guidance of Flow Policies in Reinforcement Learning
- [논문리뷰] Self-Evaluation Is Already There: Eliciting Latent Judge Calibration in Base LLMs with Minimal Data
- [논문리뷰] Meta-Cognitive Memory Policy Optimization for Long-Horizon LLM Agents
Review 의 다른글
- 이전글 [논문리뷰] Rethinking the Divergence Regularization in LLM RL
- 현재글 : [논문리뷰] Retrospective Harness Optimization: Improving LLM Agents via Self-Preference over Trajectory Rollouts
- 다음글 [논문리뷰] Role-Agent: Bootstrapping LLM Agents via Dual-Role Evolution
댓글