[논문리뷰] VIA-SD: Verification via Intra-Model Routing for Speculative Decoding
링크: 논문 PDF로 바로 열기
저자: Yuchen Xian, Yang He, Yunqiu Xu, Yi Yang, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- VIA-SD: Verification via Intra-Model Routing for Speculative Decoding의 약자로, 다층적 검증(multi-tier verification)을 통해 LLM 추론 효율성을 극대화하는 프레임워크입니다.
- Slim-Verifier: 대형 언어 모델(Verifier)에서
Intra-Model Routing을 통해 추출된 경량 서브모델로, 중간 수준의 확신도를 가진 토큰을 효율적으로 처리합니다. - DIMR (Dynamic Intra-Model Routing): 특정 계층(layer)을 동적으로 선택 및 바이패스하여 최적의 서브모델을 구성하는 최적화 기법입니다.
- KL Divergence: 서로 다른 모델 분포 간의 차이를 측정하여, 다단계 검증 경로가 최적인지를 이론적으로 판단하는 척도로 사용됩니다.
- Draft-Verify Paradigm: 경량 드래프터(Drafter)가 제안한 토큰을 대형 모델(Verifier)이 검증하는 추론 최적화 방식입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 기존의 Speculative Decoding이 가진 이분법적(accept 또는 full recompute) 검증 구조의 한계를 극복하고자 합니다. 기존 방식은 드래프터가 제안한 토큰을 대형 모델이 모두 검증하거나 전체를 다시 계산해야 하므로, 중간 수준의 확신도를 가진 토큰들에 대해 불필요한 연산 비용을 초래합니다. 이는 Total Variation (TV) distance 기반의 고정된 검증 방식이 중간 경로를 수용하지 못하기 때문입니다. [Figure 1]에서 제시된 바와 같이, 기존의 2단계 방식은 대형 모델의 리소스를 과도하게 점유하거나 드래프터의 성능에 지나치게 의존하는 구조적 결함을 보입니다. 따라서 저자들은 중간 단계의 검증을 통해 대형 모델 호출을 줄이는 새로운 다층적 패러다임을 제안합니다.
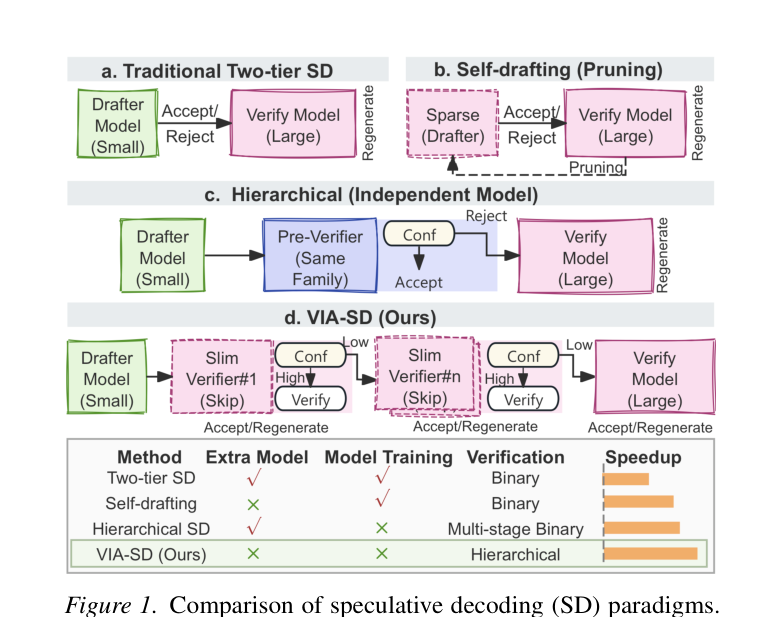
Figure 1 — 기존 SD와 VIA-SD의 검증 아키텍처 차이를 명확히 보여주는 핵심 다이어그램
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 연구는 KL divergence를 기반으로 한 정보 이론적 설계를 통해, 대형 모델 내부에 Slim-Verifier를 라우팅하여 생성하는 다층적 검증 프레임워크 VIA-SD를 제안합니다. DIMR 기술은 베이지안 최적화와 랜덤 서치를 결합하여 최적의 레이어 구성 마스크를 찾아내며, 이를 통해 추가적인 모델 로드 없이 대형 모델의 일부만 활용하는 효율성을 확보합니다. 실험 결과, VIA-SD는 Gemma2-2B→9B/27B, LLaMA2-7B→13B/70B, Qwen-7B 등 다양한 모델 패밀리에서 기존의 Speculative Decoding 및 Cascade SD 베이스라인 대비 rejection rate를 0.10–0.22 수준으로 대폭 낮추었습니다. [Table 1] 및 [Table 2]에 따르면, VIA-SD는 QA 및 추론 태스크에서 일관되게 10–20% 이상의 추가 속도 향상을 달성하며, 기존 대비 2.5–3배의 추론 가속 성능을 증명했습니다.
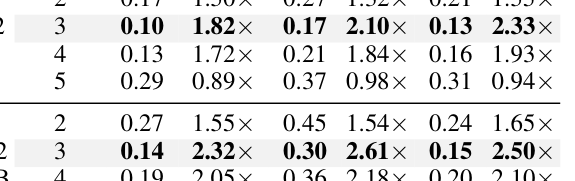
Table 1 — 제안 방법론의 성능 우위를 정량적으로 보여주는 핵심 지표 테이블
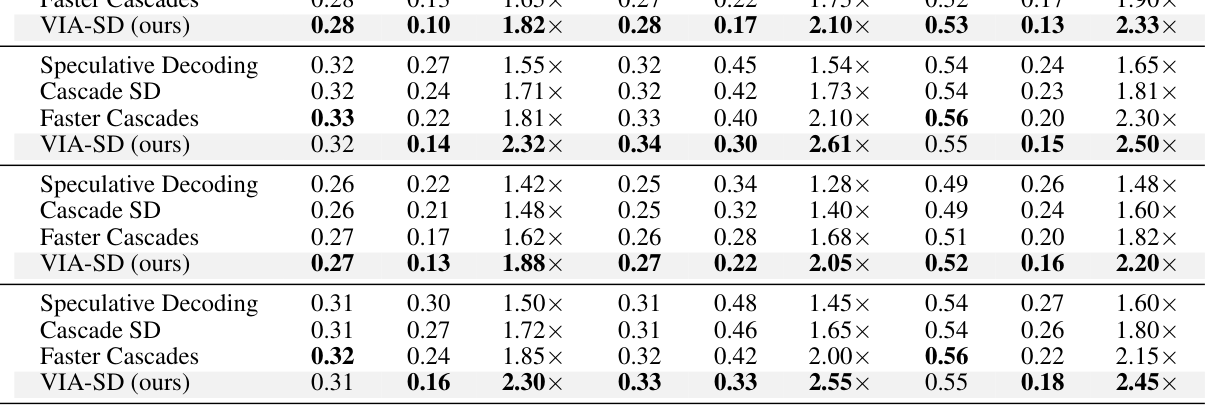
Table 2 — 다양한 모델 스케일에서의 확장성과 성능 향상을 입증하는 결과 테이블
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 speculative decoding을 이분법적 방식에서 다층적 검증 패러다임으로 전환함으로써 효율적인 LLM 추론을 가능하게 합니다. 제안된 Slim-Verifier와 Intra-Model Routing 설계는 모델의 가중치를 추가로 학습할 필요 없이 추론 단계에서 정교한 제어를 가능하게 하여, 대형 모델 배포 시의 연산 비용과 지연 시간을 획기적으로 개선합니다. 이 연구는 학계 및 산업계에서 대규모 언어 모델의 실시간 서비스 구현을 위한 확장 가능하고 지속 가능한 추론 아키텍처의 새로운 설계 방향을 제시합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LK Losses: Direct Acceptance Rate Optimization for Speculative Decoding
- [논문리뷰] Speculative Pipeline Decoding: Higher-Accruacy and Zero-Bubble Speculation via Pipeline Parallelism
- [논문리뷰] Domino: Decoupling Causal Modeling from Autoregressive Drafting in Speculative Decoding
- [논문리뷰] SpecBlock: Block-Iterative Speculative Decoding with Dynamic Tree Drafting
- [논문리뷰] AdaSPEC: Selective Knowledge Distillation for Efficient Speculative Decoders
Review 의 다른글
- 이전글 [논문리뷰] TreeSeeker: Tree-Structured Trial, Error, and Return in Deep Search
- 현재글 : [논문리뷰] VIA-SD: Verification via Intra-Model Routing for Speculative Decoding
- 다음글 [논문리뷰] VideoMDM: Towards 3D Human Motion Generation From 2D Supervision
댓글