[논문리뷰] Dense Supervision, Sparse Updates: On the Sparsity and Geometry of On-Policy Distillation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Guo Yu, Wenlin Liu, Yulan Hu, Hao-Xuan Ma, Jun-Peng Jiang, Han-Jia Ye
1. Key Terms & Definitions (핵심 용어 및 정의)
- OPD (On-policy Distillation): 학생 모델이 생성한 on-policy 궤적(trajectories)에 대해 교사 모델(teacher)로부터 토큰 단위의 밀도 높은(dense) 피드백을 받아 모델을 최적화하는 후학습(post-training) 방식입니다.
- Checkpoint Delta ($\Delta W$): 학습 전후의 모델 파라미터 차이($\Delta W = W_{\text{trained}} - W_{\text{src}}$)를 의미하며, 이를 통해 학습 과정에서 모델의 가중치 공간이 어떻게 변화했는지 분석합니다.
- Coordinate Sparsity: 파라미터 업데이트가 모델의 전체 파라미터 중 소수의 좌표에서만 발생하거나, 특정 임계값($\epsilon$) 미만의 변화를 보이는 좌표가 많은 현상을 의미합니다.
- Principal Subspace Alignment: 모델의 소스 가중치($W_{\text{src}}$)가 가진 주성분(principal singular directions)과 학습으로 인한 파라미터 업데이트 방향 간의 일치도를 측정하는 기하학적 지표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 OPD가 일반적인 Supervised Fine-tuning(SFT)과 달리 어떤 기하학적 특성을 가지며, 왜 RLVR(Reinforcement Learning from Verifier-derived Rewards)과 유사한 sparse한 업데이트 양상을 보이는지 규명합니다. 기존 연구들은 RLVR이 매우 sparse한 업데이트를 수행한다는 점을 밝혔으나, OPD처럼 학습 데이터는 on-policy이면서 학습 신호는 dense한 경우 파라미터 공간에서 어떤 변화가 일어나는지는 불분명했습니다 [Figure 1]. 저자들은 dense한 교사 감독 신호가 OPD를 일반적인 dense 파라미터 재작성 과정으로 전환하는지, 아니면 여전히 sparse하고 off-principal한 특성을 유지하는지 분석하고자 합니다.
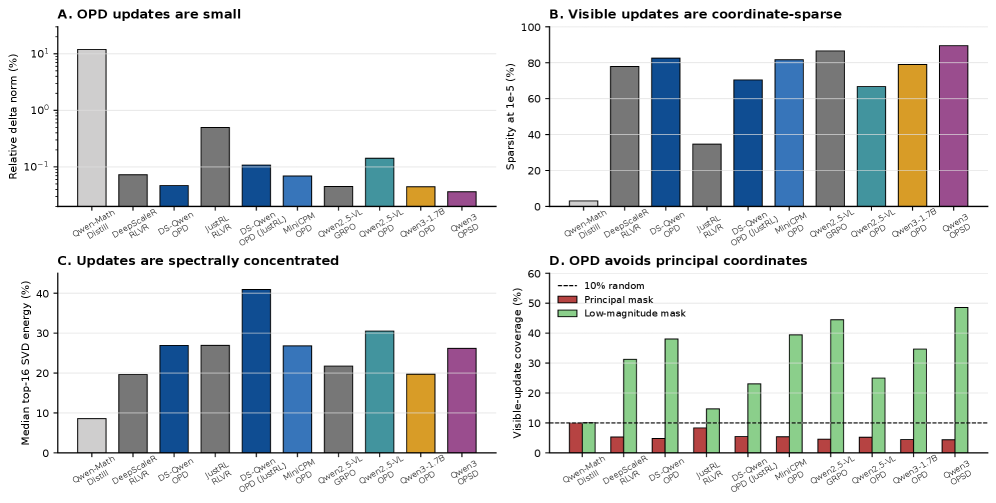
Figure 1 — OPD 업데이트의 특성 분석 결과
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 10개의 모델 쌍에 대해 파라미터 업데이트의 크기, 좌표 sparsity, 모듈별 구조, spectral 특성 및 소스 가중치와의 기하학적 정렬을 분석합니다. 분석 결과, OPD 방식의 업데이트는 상대적으로 작은 norm을 가지며, FFN 모듈에 집중된 높은 coordinate sparsity를 나타냅니다 [Figure 2]. 또한, OPD 업데이트는 수치적으로는 full-rank이지만, singular value spectrum이 특정 방향으로 집중(spectrally concentrated)되어 있으며 소스 가중치의 주요 성분을 피하는 off-principal한 기하학적 특성을 가집니다 [Table 2]. 특히, 학습된 sparse subnetwork 마스크만 사용하여 재학습(masked training)을 진행하더라도 full-training과 거의 동일한 성능을 회복함을 확인하여, 이 sparse 구조가 단순한 현상적 특징을 넘어 실질적인 학습 효율성을 가짐을 입증했습니다 [Figure 3(a)]. 마지막으로 Optimizer 분석 결과, OPD는 sparse한 결과물을 도출함에도 불구하고, SGD보다는 AdamW의 adaptive scaling이 성능 유지에 필수적임을 밝혀냈습니다 [Figure 3(b)].
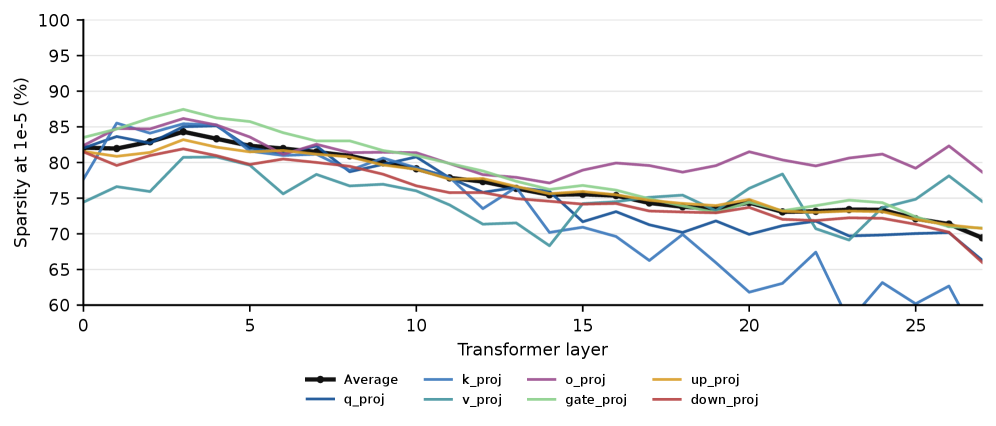
Figure 2 — DS-Qwen OPD의 층별/행렬별 Sparsity
4. Conclusion & Impact (결론 및 시사점)
본 논문은 OPD가 dense한 학습 신호를 활용함에도 불구하고 기하학적으로는 dense한 재작성이 아닌, sparse하고 off-principal한 편집(editing) 과정에 가깝다는 점을 결론 내립니다. 이러한 발견은 on-policy 학습 데이터 분포 자체가 post-training 업데이트의 기하학적 구조를 결정짓는 핵심 요소임을 시사합니다. 본 연구는 향후 OPD를 위한 전용 최적화 기법 및 LoRA와 같은 파라미터 효율적인 적응 방법(PEFT) 설계에 중요한 이론적 토대를 제공합니다.
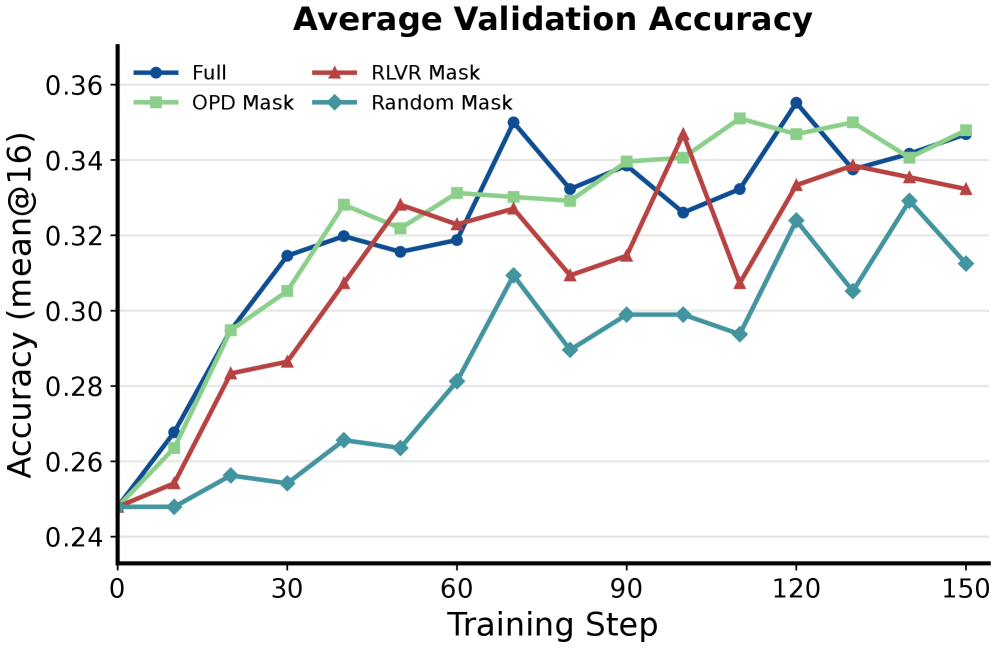
Figure 3 — 서브네트워크 마스크 및 옵티마이저 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes
- [논문리뷰] STARE: Surprisal-Guided Token-Level Advantage Reweighting for Policy Entropy Stability
- [논문리뷰] Trajectory-Refined Distillation
- [논문리뷰] On the Geometry of On-Policy Distillation
- [논문리뷰] Trust-Region Behavior Blending for On-Policy Distillation
Review 의 다른글
- 이전글 [논문리뷰] ClinHallu: A Benchmark for Diagnosing Stage-Wise Hallucinations in Medical MLLM Reasoning
- 현재글 : [논문리뷰] Dense Supervision, Sparse Updates: On the Sparsity and Geometry of On-Policy Distillation
- 다음글 [논문리뷰] FVSpec: Real-World Property-Based Tests as Lean Challenges
댓글