[논문리뷰] P3D-Bench: Benchmarking MLLMs for Parametric 3D Generation and Structural Reasoning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yikang Yang, Zhanpeng Hu, Youtian Lin, Mengqi Zhou, Jingxi Xu, Feihu Zhang, Jiaheng Liu, Yao Yao
1. Key Terms & Definitions (핵심 용어 및 정의)
- Parametric 3D Generation: 고정된 3D mesh가 아닌, 치수(Dimension), 구성 연산(Operation), 부품 관계(Part Relation)를 명시한 프로그램을 생성하여 3D 모델을 구축하는 방식입니다.
- P3D-Bench: Text-to-3D, Image-to-3D, Assembly-3D 등 세 가지 작업군을 통해 모델의 프로그래밍 능력과 3D 구조적 추론 역량을 정량적으로 평가하는 벤치마크입니다.
- MLLM Judge: 생성된 3D 프로그램의 결과물을 시각적으로 평가하기 위해 Gemini 3.1 Pro를 활용하여 의미적 일치성(J-Sem), 기하학적 정밀도(J-Geo) 등을 측정하는 프로토콜입니다.
- Assembly-3D: 여러 부품으로 구성된 복합 객체를 생성하고, 부품의 수와 배치 및 구조적 정합성을 평가하는 가장 도전적인 과제입니다.
- Executable Validity (Valid): 생성된 코드가 오류 없이 컴파일 및 렌더링되어 유효한 3D 기하학적 구조를 생성하는지 여부를 나타내는 지표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 3D 생성 벤치마크가 프로그램 기반의 파라메트릭 생성 능력을 종합적으로 평가하지 못한다는 한계를 해결하기 위해 P3D-Bench를 제안합니다 [Figure 2]. 기존 연구들은 주로 정적인 메쉬 생성이나 단순한 시각적 품질 평가에 치중되어 있어, 실제 3D 모델링에 필수적인 기하학적 정밀도나 부품 간의 구조적 관계를 검증하지 못합니다. MLLM은 이제 CAD 코드(예: CadQuery, OpenSCAD)를 작성할 수 있는 수준에 도달했지만, 생성된 프로그램이 설계 의도대로 정확한 치수와 구조를 복원하는지 평가할 표준화된 프로토콜이 부재합니다. 따라서 저자들은 Executable Validity, 기하학적 충실도, 구조적 정합성을 동시에 평가할 수 있는 통합 프레임워크의 필요성을 강조합니다.
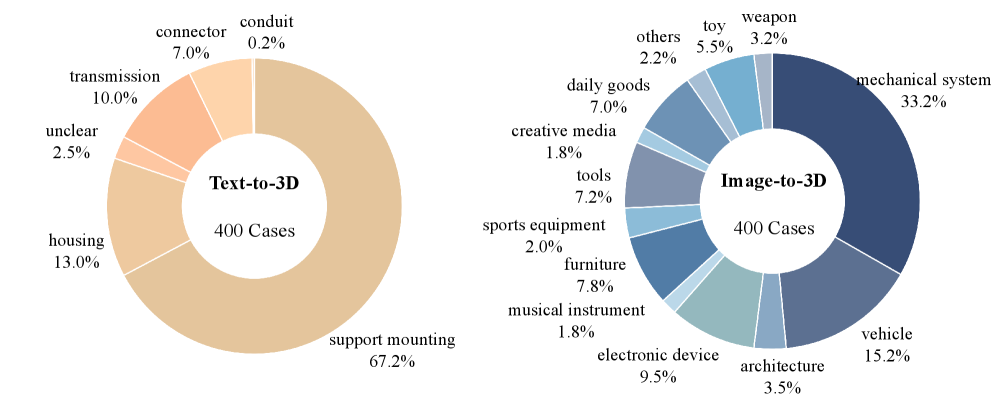
Figure 2 — P3D-Bench 평가 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 다양한 입력 조건(텍스트, 이미지)으로부터 4가지 코드 포맷(JSON, OpenSCAD, CadQuery, Three.js) 중 하나를 선택해 3D 프로그램을 생성하도록 하는 통합 평가 프로토콜을 제안합니다 [Figure 2]. 평가 데이터셋인 P3D-Dataset은 Text2CAD v1.1 및 Fusion 360 Gallery를 정제하고, MLLM 기반의 검증 파이프라인을 통해 400개의 텍스트 사례, 400개의 이미지 사례, 203개의 조립체 사례를 구축했습니다 [Figure 3]. 주요 실험 결과, 최신 MLLM(예: GPT-5.5)은 전반적인 객체의 의미적 정체성(J-Sem ≈ 0.8)은 잘 파악하지만, 세부적인 기하학적 치수 정확도(J-Geo ≈ 0.35)는 매우 낮게 나타났습니다 [Table 3]. 특히 Assembly-3D 작업에서 가장 성능 저하가 뚜렷하며, 가장 우수한 모델조차 부품 수준의 구조를 맞추는 PartMatchF1 지표에서 약 0.5 수준의 성능을 기록하여 부품의 수와 구조를 정확히 복원하는 데 한계를 보였습니다 [Figure 10]. 결과적으로 OpenSCAD가 모든 평가 지표에서 가장 균형 잡힌 성능을 보여주었으며, 모델이 생성한 코드가 실행 가능하더라도 파라메트릭 기하학적 정확도는 여전히 해결해야 할 주요 과제임이 확인되었습니다.
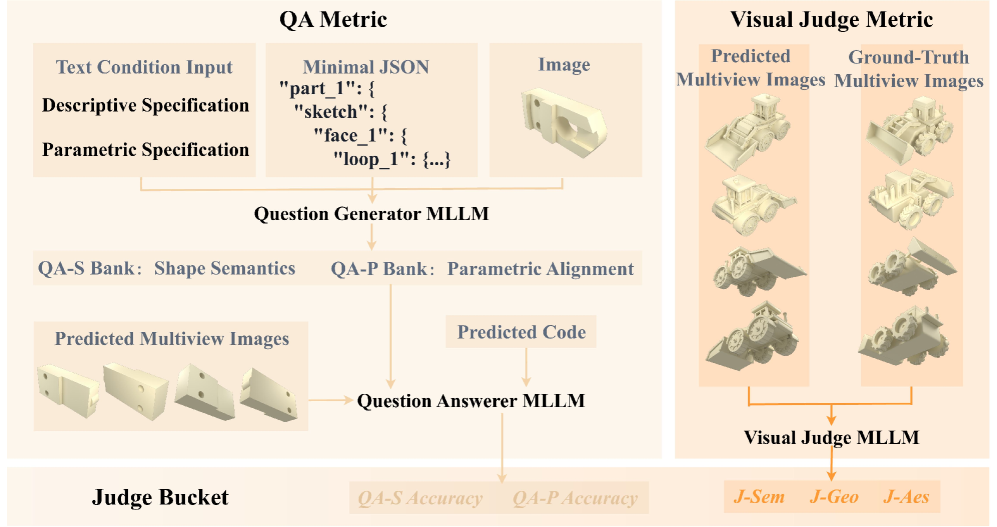
Figure 3 — 데이터셋 구축 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 논문은 파라메트릭 3D 생성 분야를 체계적으로 평가하는 P3D-Bench를 도입하여, MLLM의 구조적 추론 역량에 대한 명확한 한계를 규명했습니다. 연구 결과는 현재 MLLM들이 외형 복원에는 능숙하지만 치수 기반의 정밀한 CAD 설계에는 상당한 개선이 필요함을 시사합니다. 이 벤치마크는 향후 단순 외형 생성을 넘어, 실제 제조 및 엔지니어링에 활용 가능한 프로그램 생성 모델 개발을 촉진하는 핵심 지표로 기여할 것입니다. 저자들은 앞으로 더 다양한 환경(Blender, Unreal Engine 등)과 에이전트 기반의 반복적 코드 수정 워크플로우를 추가하여 평가 범위를 확장할 계획입니다.
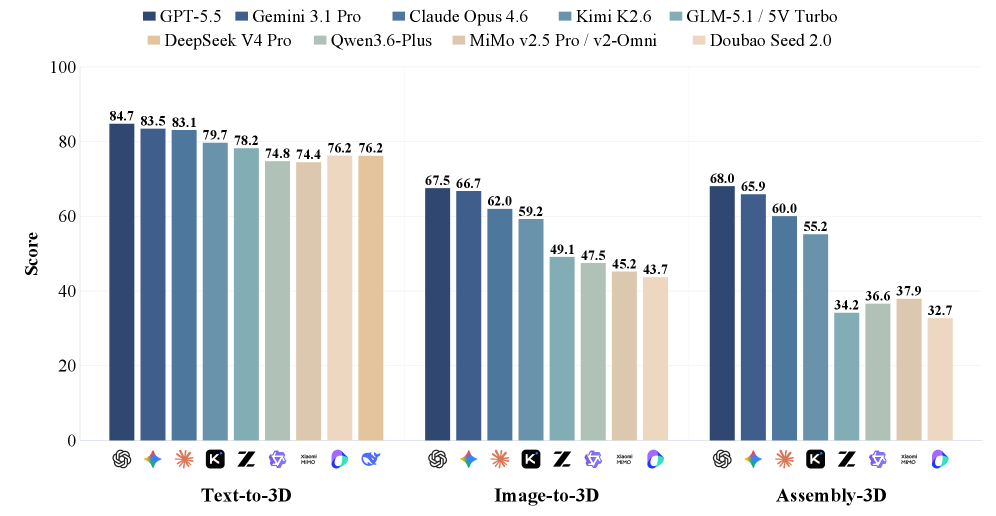
Figure 1 — 모델별 P3D-Bench 성능 점수
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] No Resource, No Benchmarks, No Problem? Evaluating and Improving LLMs for Code Generation in No-Resource Languages
- [논문리뷰] Towards One-to-Many Temporal Grounding
- [논문리뷰] ProactiveBench: Benchmarking Proactiveness in Multimodal Large Language Models
- [논문리뷰] MiniAppBench: Evaluating the Shift from Text to Interactive HTML Responses in LLM-Powered Assistants
- [논문리뷰] SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases via Continuous Integration
Review 의 다른글
- 이전글 [논문리뷰] Orchestra-o1: Omnimodal Agent Orchestration
- 현재글 : [논문리뷰] P3D-Bench: Benchmarking MLLMs for Parametric 3D Generation and Structural Reasoning
- 다음글 [논문리뷰] Quickest Detection of Hallucination Onset: Delay Bounds and Learned CUSUM Statistics
댓글