[논문리뷰] BadWorld: Adversarial Attacks on World Models
링크: 논문 PDF로 바로 열기
메타데이터
저자: Linghui Shen, Mingyue Cui, Xingyi Yang
1. Key Terms & Definitions (핵심 용어 및 정의)
- VWMs (Visual World Models): 단일 컨텍스트 이미지와 사용자 제어 신호(Action/Camera trajectory)를 입력받아 상호작용 가능한 미래 영상을 생성하는 모델입니다.
- Autoregressive (AR) Generation: 비디오 시퀀스를 다수의 청크로 분해하고, 이전 단계의 생성물과 제어 신호를 조건으로 삼아 순차적으로 영상을 생성하는 방식입니다.
- Velocity Attack: Flow-matching 모델의 핵심인 속도(Velocity) 예측 값을 조작하여, denoising 과정에서 구조적 붕괴나 시각적 왜곡을 유발하는 공격 기법입니다.
- Trajectory-Adaptive Bi-Level Optimization: 제어 신호의 다양성을 고려하여, 다양한 제어 경로에서도 일관되게 성능을 저하시킬 수 있는 'Hard trajectory'를 탐색하고 공격을 최적화하는 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 VWMs의 잠재적 취약성을 평가하기 위한 최초의 적대적 공격 프레임워크인 BadWorld를 제안합니다. 기존 생성 모델 공격과 달리, VWMs는 미래의 영상 데이터가 존재하지 않고(C1: Missing future supervision), 사용자의 향후 제어 경로가 불확실하다는(C2: Unknown future controls) 고유한 제약 조건을 갖습니다. 이러한 환경에서 일반적인 적대적 공격은 적용이 불가능하며, 정교한 조작이 어려워 물리적 일관성과 제어 가능성을 위협하는 취약점을 적절히 진단하지 못합니다. [Figure 1]
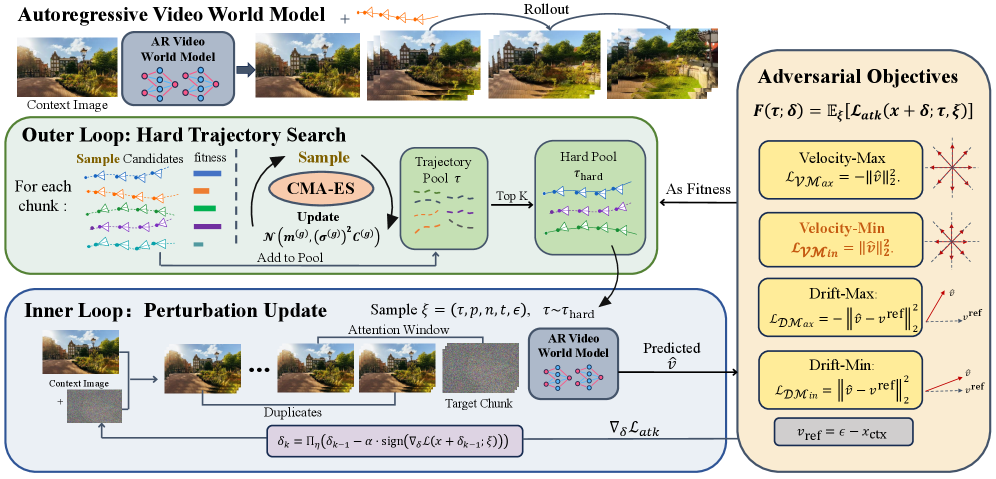
Figure 1 — BadWorld 프레임워크 파이프라인
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 VWMs의 denoising dynamics를 직접 조작하는 Self-supervised velocity attack을 핵심 방법론으로 도입합니다. 저자들은 Early-denoising approximation을 통해 실제 미래 프레임 없이도 공격이 가능하게 설계하였으며, Trajectory-Adaptive Bi-Level Optimization을 통해 다양한 사용자 제어 시나리오에 강건한 Adversarial image를 생성합니다 [Figure 1]. 실험 결과, Velocity-Min 공격은 대표적인 VWMs 모델인 Astra 및 Matrix-Game 2.0에서 가장 높은 공격 성능을 기록했습니다. Astra 모델 대상 실험에서 Velocity-Min은 Aesthetic Quality를 0.501에서 0.405로, Imaging Quality를 0.690에서 0.513으로 유의미하게 저하시켰으며, MEt3R 점수는 0.264로 상승하여 기하학적 붕괴가 심화됨을 입증했습니다 [Table 1]. 또한, Matrix-Game 2.0에서도 유사하게 Background Consistency를 0.973에서 0.845로 크게 낮추며 강한 취약성을 드러냈습니다 [Table 2]. [Figure 2], [Figure 3]

Figure 2 — Astra 모델 대상 정성적 비교

Figure 3 — Matrix-Game-2.0 정성적 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 BadWorld를 통해 VWMs가 예기치 못한 작은 입력 섭동(Perturbation)에도 심각한 구조적 붕괴와 제어 불능 상태에 빠질 수 있음을 밝혀냈습니다. 이 연구는 안전성이 중요한 Autonomous driving이나 Robotics 분야에서 VWMs 배치 시 발생할 수 있는 보안 위험을 경고합니다. 동시에, 이러한 적대적 공격 기법은 민감한 영상 데이터를 무단으로 학습하거나 상호작용형 시뮬레이션에 활용되는 것을 방지하는 실질적인 프라이버시 보호 도구로도 활용될 수 있음을 시사합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] ImageWAM: Do World Action Models Really Need Video Generation, or Just Image Editing?
- [논문리뷰] FlowBender: Feedback-Aware Training for Self-Correcting Conditional Flows
- [논문리뷰] Adaptive Volumetric Mechanical Property Fields Invariant to Resolution
- [논문리뷰] PAIWorld: A 3D-Consistent World Foundation Model for Robotic Manipulation
- [논문리뷰] MotionVLA: Vision-Language-Action Model for Humanoid Motion
Review 의 다른글
- 이전글 [논문리뷰] BRDFusion: Physics Meets Generation for Urban Scene Inverse Rendering
- 현재글 : [논문리뷰] BadWorld: Adversarial Attacks on World Models
- 다음글 [논문리뷰] CODA-BENCH: Can Code Agents Handle Data-Intensive Tasks?
댓글