[논문리뷰] Ling and Ring 2.6 Technical Report: Efficient and Instant Agentic Intelligence at Trillion-Parameter Scale
링크: 논문 PDF로 바로 열기
저자: Ang Li, Ben Liu, Bin Han, et al.
키워: Agentic Intelligence, Token Efficiency, Long-Context, Hybrid Attention, Multi-Token Prediction, Reinforcement Learning, MoE
1. Key Terms & Definitions (핵심 용어 및 정의)
- Agentic Intelligence: 환경과 상호작용하며 복잡한 목표를 달성하기 위해 계획, 도구 사용, 검색 등 추론 능력을 활용하는 AI 시스템의 지능입니다. 본 논문에서는 특히 instant response와 high token efficiency를 강조합니다.
- Token Efficiency: 특정 성능을 달성하는 데 필요한 출력 토큰의 양을 측정하는 지표입니다. 더 적은 토큰으로 동일하거나 더 나은 결과를 얻는 것이 목표입니다.
- Ling and Ring 2.6: 본 논문에서 소개하는 새로운 대규모 언어 모델(LLM) 제품군으로, Ling-2.6은 instant response와 high token efficiency에, Ring-2.6은 deeper reasoning과 advanced agentic intelligence에 최적화되어 있습니다.
- Hybrid Linear Attention Retrofit (HLAR): Lightning Attention과 Multi-Head Latent Attention (MLA)을 결합하여 long-context 처리를 효율화하는 아키텍처적 접근 방식입니다.
- Multi-Token Prediction (MTP): 모델이 한 번의 추론으로 여러 토큰을 예측하게 하여 inference latency를 줄이고 throughput을 높이는 pre-training 및 fine-tuning 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 trillion-parameter scale에서 instant response와 high token efficiency를 동시에 달성하는 agentic intelligence 모델을 구축하는 데 따르는 핵심적인 문제를 해결하고자 합니다. 기존 large language models (LLMs)은 복잡한 추론, long-context 처리, instruction following 능력을 보여주지만, 이는 종종 높은 computational cost와 긴 latency를 수반하여 real-world agentic workloads에는 비효율적입니다. 특히, low-latency responses와 high-token efficiency 간의 내재된 trade-off는 기존 모델의 주요 한계점으로 작용합니다. 저자들은 이러한 제약 속에서 deep reasoning 및 long-context 성능을 유지하면서도 deployable하고 efficient한 agentic intelligence 시스템을 개발하기 위한 새로운 아키텍처 및 훈련 접근 방식이 필요하다고 주장합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 instant response와 high token efficiency를 목표로 하는 Ling-2.6과 deeper reasoning 및 advanced agentic intelligence를 위한 Ring-2.6 모델 제품군을 제안합니다. 방법론의 핵심은 혁신적인 아키텍처 retrofit, Multi-Token Prediction (MTP)을 포함한 multi-stage pre-training, 그리고 context-parallelism 및 sparse MoE 최적화입니다.
Ling-2.6-1T-base 모델은 Lightning Attention과 MLA를 7:1 비율로 결합한 hybrid attention과 fine-grained MoE 레이어를 통해 long-context 처리를 효율화합니다 [Figure 2]. post-training 단계에서는 Evolutionary Chain of Thought (Evo-CoT), LPO (Linguistic Unit Policy Optimization), 그리고 bidirectional preference alignment를 사용하여 token efficiency와 reasoning 능력을 향상시킵니다 [Figure 5]. 특히 agentic tasks를 위해 Group Sequence Policy Optimization (GSPO)과 Dynamic Pass Rating (DPR)을 적용하여 token-efficient tool use를 극대화했습니다. 또한, inference 단계에서 operator fusion과 FP8 inference를 통해 throughput을 크게 개선했습니다 [Figure 12].
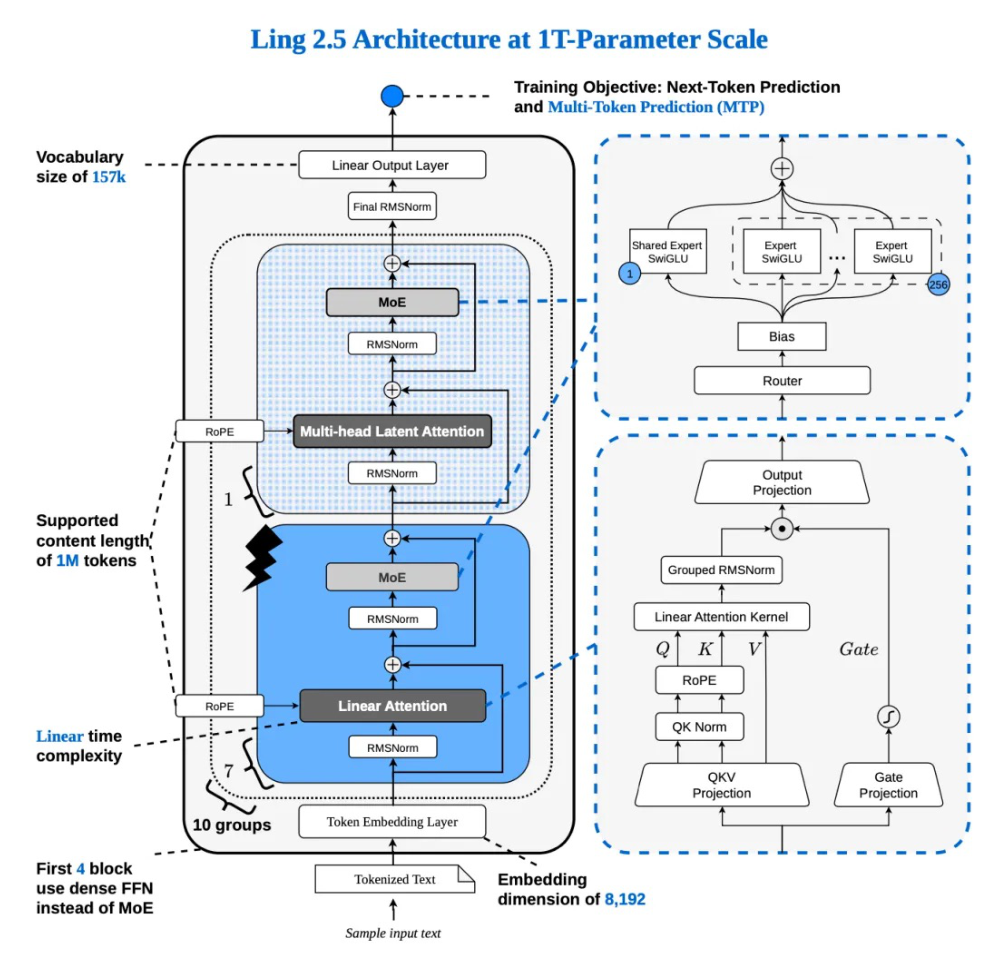
Figure 2 — 제안하는 Ling-2.6-1T-base 모델의 전체 아키텍처를 보여주는 핵심 다이어그램
주요 정량적 결과는 다음과 같습니다:
- Token Efficiency: Ling-2.6-1T는 Artificial Analysis Intelligence Index에서 16M output tokens를 사용하여 34점을 달성했습니다. 이는 Ling-2.0-1T 대비 약 4배 더 높은 token efficiency를 보여주며, GPT-5.4의 non-reasoning 설정과 유사한 수준입니다 [Figure 1].
- Agentic Performance: Ling-2.6-flash는 SWE-bench Verified (61.20), PinchBench (81.30), τ²-bench (76.36)와 같은 복잡한 agentic tasks에서 경쟁 모델 대비 우수한 성능을 보였습니다 [Table 4]. Ring-2.6-1T는 SWE-bench Verified에서 72.20%, PinchBench에서 85.24%, τ²-bench에서 78.36%를 기록했습니다 [Table 5].
- Long-Context & Instruction Following: Ling-2.6-1T는 IFBench에서 57.62점, MRCR (16K-256K)에서 80.37점을 기록하며 뛰어난 long-context retrieval 및 이해 능력을 입증했습니다 [Table 5].
- Function Calling: Ring-2.6-1T (high)는 τ²-bench 스위트에서 84.26%의 τ²-Average를 달성했으며, 특히 τ²-Telecom에서 96.71%를 기록하여 강력한 domain-specific tool use 능력을 보여주었습니다 [Table 6].
- Inference Throughput: Ling-2.6-flash는 BF16 (BS=16)에서 1233 tokens/s, FP8 (BS=16)에서 1664 tokens/s의 decode throughput을 달성했으며, prefill 및 decode에서 최대 4배의 acceleration을 제공합니다 [Table 7].

Figure 1 — Ling-2.6-1T의 핵심적인 token efficiency와 agentic performance를 보여주는 지표
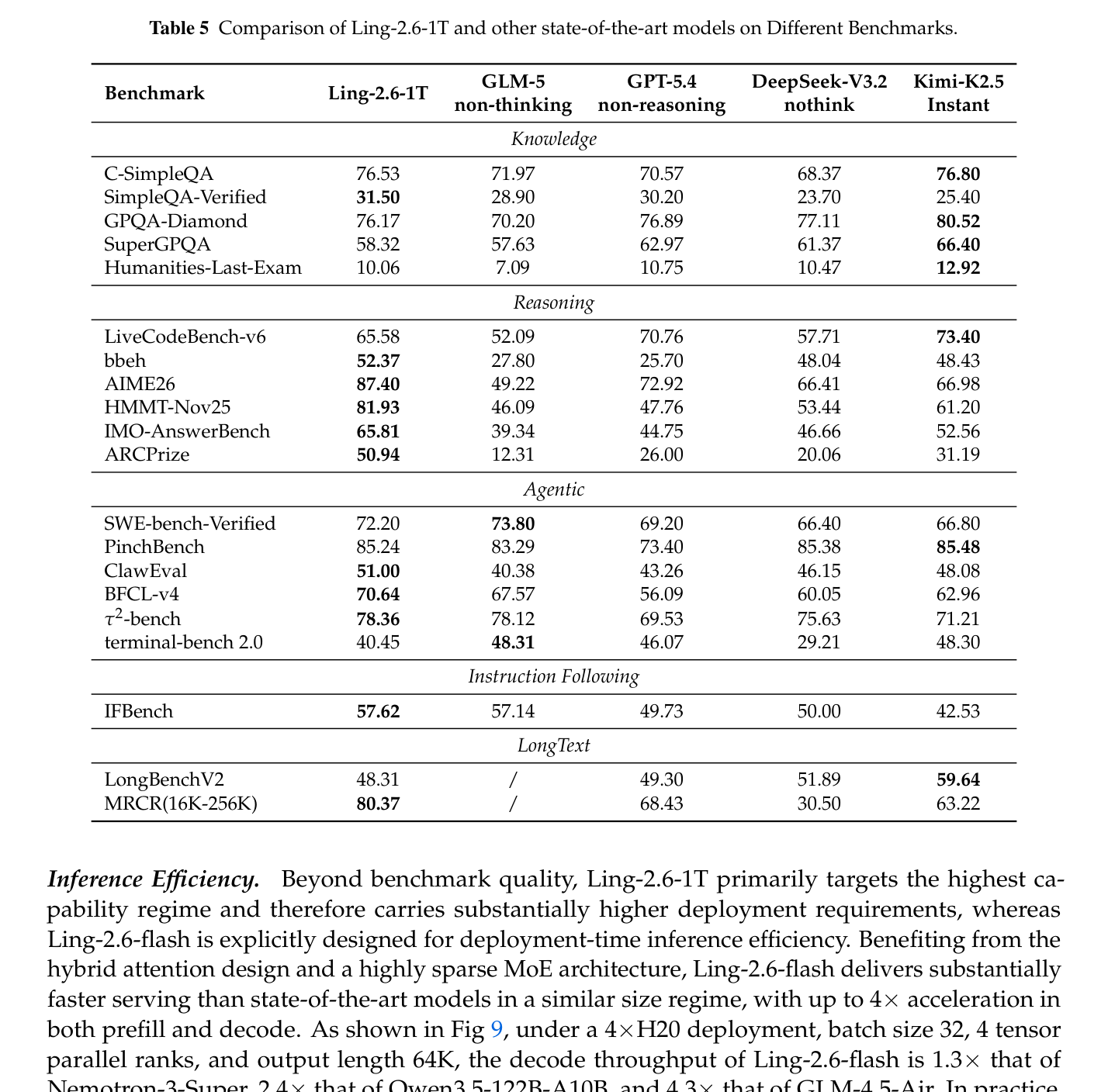
Table 5 — Ling-2.6-1T 모델의 Knowledge, Reasoning, Agentic, Instruction Following, LongText 분야에서의 정량적 성능 비교 테이블
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Ling-2.6 및 Ring-2.6 모델을 통해 trillion-parameter scale에서 instant response와 high token efficiency를 갖춘 agentic intelligence의 새로운 기준을 제시합니다. 이 모델들은 혁신적인 아키텍처 디자인과 다단계 훈련 방식을 통해 deep reasoning, long-context processing, 그리고 instruction following 능력을 효과적으로 유지하면서도, deployment에 필수적인 latency 및 throughput 최적화를 달성했습니다. 특히 Artificial Analysis Intelligence Index에서 높은 token efficiency를 입증하고, 다양한 agentic benchmarks에서 state-of-the-art 성능을 보여주었습니다. 이 연구는 efficient, open, 그리고 practically oriented agentic systems 개발을 위한 새로운 paradigm을 제공하며, 학계와 산업계 모두에 scalable하고 intelligent LLMs의 real-world agentic applications 발전을 위한 강력한 기반을 마련했다는 점에서 중요한 시사점을 가집니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] Understanding the Behaviors of Environment-aware Information Retrieval
- [논문리뷰] Thinking with Visual Grounding
- [논문리뷰] Taylor-Calibrate: Principled Initialization for Hybrid Linear Attention Distillation
- [논문리뷰] Selective Synergistic Learning for Video Object-Centric Learning
Review 의 다른글
- 이전글 [논문리뷰] LaWAM: Latent World Action Models for Efficient Dynamics-Aware Robot Policies
- 현재글 : [논문리뷰] Ling and Ring 2.6 Technical Report: Efficient and Instant Agentic Intelligence at Trillion-Parameter Scale
- 다음글 [논문리뷰] MMDiff: Extending Diffusion Transformers for Multi-Modal Generation
댓글