[논문리뷰] TokenPilot: Cache-Efficient Context Management for LLM Agents
링크: 논문 PDF로 바로 열기
메타데이터
저자: Buqiang Xu, Zirui Xue, Dianmou Chen, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Ingestion-Aware Compaction: 프롬프트의 초기 Warm-up 단계에서 레이아웃을 표준화하고 불필요한 환경 소음을 제거하여 캐시 효율을 극대화하는 글로벌 최적화 기법입니다.
- Lifecycle-Aware Eviction: 컨텍스트 세그먼트의 잔여 유틸리티(Residual Utility)를 모니터링하여, 태스크 수행에 더 이상 필요하지 않을 때만 메모리에서 제거하는 보수적인 로컬 관리 방식입니다.
- Prefix Stabilization: 런타임 변수(예: 타임스탬프, 경로 등)를 고정된 Placeholder로 대체하여 프롬프트 접두사의 물리적 연속성을 확보, Cache Hit를 유도하는 메커니즘입니다.
- KV Cache: 대규모 언어 모델 추론 시 이전 토큰들의 정보를 저장하여 중복 계산을 방지하는 메모리 영역으로, 본 논문에서는 이의 연속성을 유지하는 것이 비용 절감의 핵심입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM 에이전트의 세션이 길어짐에 따라 발생하는 컨텍스트 누적과 이로 인한 기하급수적인 추론 비용 문제를 해결하고자 합니다. 기존의 텍스트 가지치기(Pruning)나 동적 메모리 제거 기법들은 시퀀스의 레이아웃을 임의로 변경하여 프롬프트 접두사의 연속성을 깨뜨립니다. 이러한 변경은 하드웨어 수준의 KV Cache 미스를 유발하여, 텍스트 절감으로 얻는 이득보다 캐시 미스에 따른 비용 손실이 더 커지는 구조적 한계를 가집니다 [Figure 1]. 따라서 저자들은 텍스트 수준의 Sparsity 확보와 하드웨어 수준의 Cache Alignment를 동시에 달성할 수 있는 새로운 통합 프레임워크를 제안합니다.
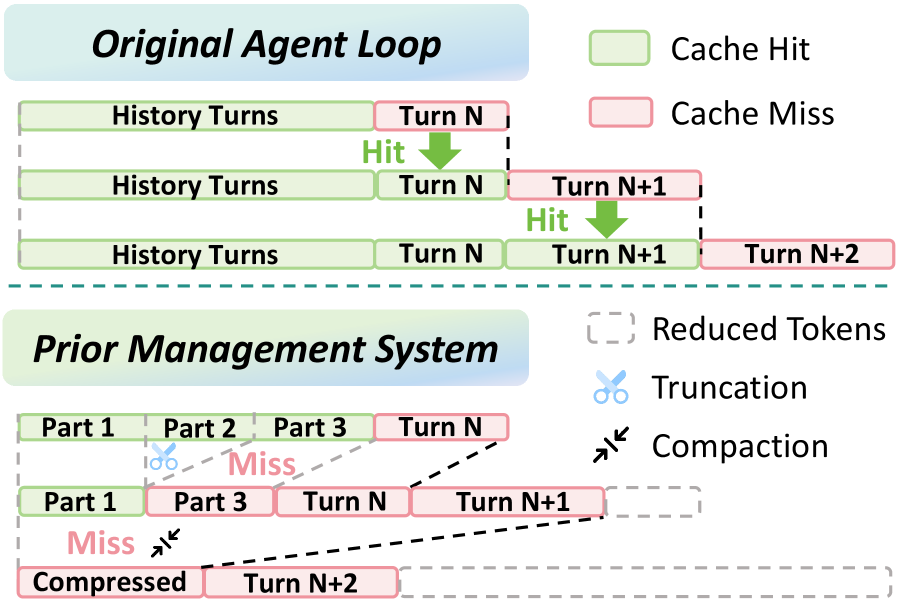
Figure 1 — 캐시 정렬 방식 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 글로벌 레벨의 Ingestion-Aware Compaction과 로컬 레벨의 Lifecycle-Aware Eviction으로 구성된 TokenPilot 프레임워크를 제안합니다 [Figure 2]. Ingestion-Aware Compaction은 에이전트 인터페이스 진입 단계에서 환경 노이즈를 필터링하고 변수들을 정규화하여 Byte-identical한 접두사를 유지합니다. 이어서 Lifecycle-Aware Eviction은 모델 기반의 상태 추정기를 활용하여 각 컨텍스트 세그먼트의 잔여 유틸리티를 평가하고, 꼭 필요한 시점에만 보수적으로 메모리를 해제합니다. 실험 결과, PinchBench 데이터셋 기준 Isolated Mode에서 기존 방식 대비 61%, 56%의 비용 절감 효과를 보였으며, Continuous Mode에서는 최대 87%까지 비용을 감소시키면서도 동일한 성능을 유지하였습니다 [Table 1, Table 2]. 특히, Prefix Stabilization을 통해 Cache Hit Rate를 크게 향상시켰으며, Lifecycle-Aware Eviction의 도입으로 메모리 점유를 최적화하여 65.0%의 Cache Read 토큰 감소를 달성하였습니다 [Table 3].
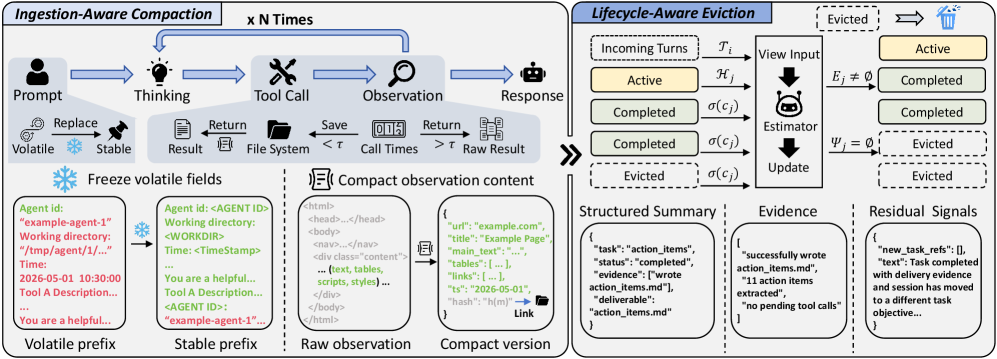
Figure 2 — TokenPilot 시스템 아키텍처
4. Conclusion & Impact (결론 및 시사점)
본 논문은 LLM 에이전트의 장기 세션 관리에 있어 프롬프트 캐시의 물리적 연속성이 추론 경제성에 결정적임을 입증했습니다. TokenPilot은 단순한 텍스트 압축을 넘어, 하드웨어 캐시 구조와 연동된 지능형 컨텍스트 관리 프레임워크를 제시함으로써 실용적인 에이전트 배포의 비용 장벽을 낮췄습니다. 이러한 접근 방식은 향후 긴 호흡의 작업을 수행하는 고성능 에이전트 설계 및 지속 가능한 LLM 서비스 운영에 중요한 학술적·산업적 지침을 제공할 것으로 기대됩니다.
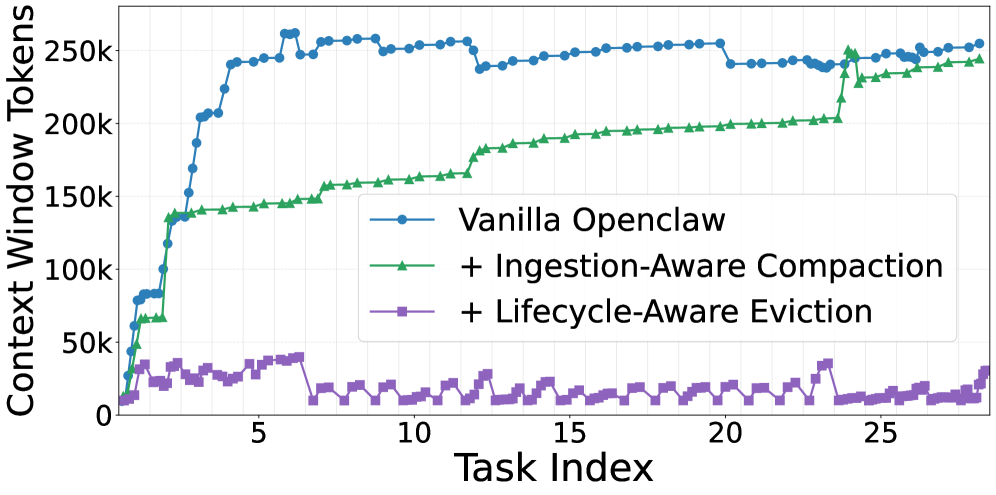
Figure 3 — 연속 세션 컨텍스트 변화량
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Agent-Omit: Training Efficient LLM Agents for Adaptive Thought and Observation Omission via Agentic Reinforcement Learning
- [논문리뷰] Toward Ultra-Long-Horizon Agentic Science: Cognitive Accumulation for Machine Learning Engineering
- [논문리뷰] MemoBrain: Executive Memory as an Agentic Brain for Reasoning
- [논문리뷰] SCOPE: Prompt Evolution for Enhancing Agent Effectiveness
- [논문리뷰] IterResearch: Rethinking Long-Horizon Agents via Markovian State Reconstruction
Review 의 다른글
- 이전글 [논문리뷰] The Ghosts of Polymarket: When Off-Chain Matches Meet On-Chain Reverts
- 현재글 : [논문리뷰] TokenPilot: Cache-Efficient Context Management for LLM Agents
- 다음글 [논문리뷰] TuneJury: An Open Metric for Improving Music Generation Preference Alignment
댓글