[논문리뷰] A Benchmark and Framework for Evaluating Next Action Predictions in Spreadsheets
링크: 논문 PDF로 바로 열기
메타데이터
저자: Tejas Agrawal, Vu Le, Sumit Gulwani, Gust Verbruggen
1. Key Terms & Definitions (핵심 용어 및 정의)
- Next Action Prediction: 사용자의 이전 작업 기록을 바탕으로 다음에 수행할 작업을 예측하여 스프레드시트 작업을 자동화하는 기술입니다.
- Online Evaluation: 정적인 데이터셋 평가가 아닌, 모델의 예측이 실제 사용자 작업 환경처럼 다음 상태에 영향을 미치는 루프 환경에서 수행하는 실시간 평가 방식입니다.
- UAS (User Actions Saved): 모델의 예측이 사용자의 노력을 얼마나 절감했는지 측정하는 핵심 성능 지표로, 예측 수용 시 제거된 작업량과 추가된 수정 작업량을 고려합니다.
- Acceptance Heuristics: 모델의 예측을 사용자가 수용할지 혹은 거부할지를 결정하는 규칙으로, 모델의 실질적인 유용성을 제어하는 핵심 요소입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 스프레드시트 환경에서 부족한 자동 완성(auto-completion) 기능을 보완하기 위해 차세대 작업 예측을 위한 벤치마크와 평가 프레임워크를 제안합니다. 기존의 코드 자동 완성 연구와 달리, 스프레드시트는 공개적인 편집 기록(edit history) 데이터가 부족하고 작업 공간이 복잡하다는 한계가 있습니다. 특히, 기존의 teacher-forced 방식의 오프라인 평가는 모델의 예측 오류가 다음 단계에 미치는 누적 효과를 측정하지 못하며, 사용자의 실제 수용 여부를 반영하지 못한다는 결정적인 문제점이 있습니다. 이를 해결하기 위해 저자들은 52개의 정교한 스프레드시트 생성 궤적을 큐레이션하고, 실제 사용자의 수용 행동을 시뮬레이션하는 온라인 평가 루프를 도입합니다 [Figure 4].
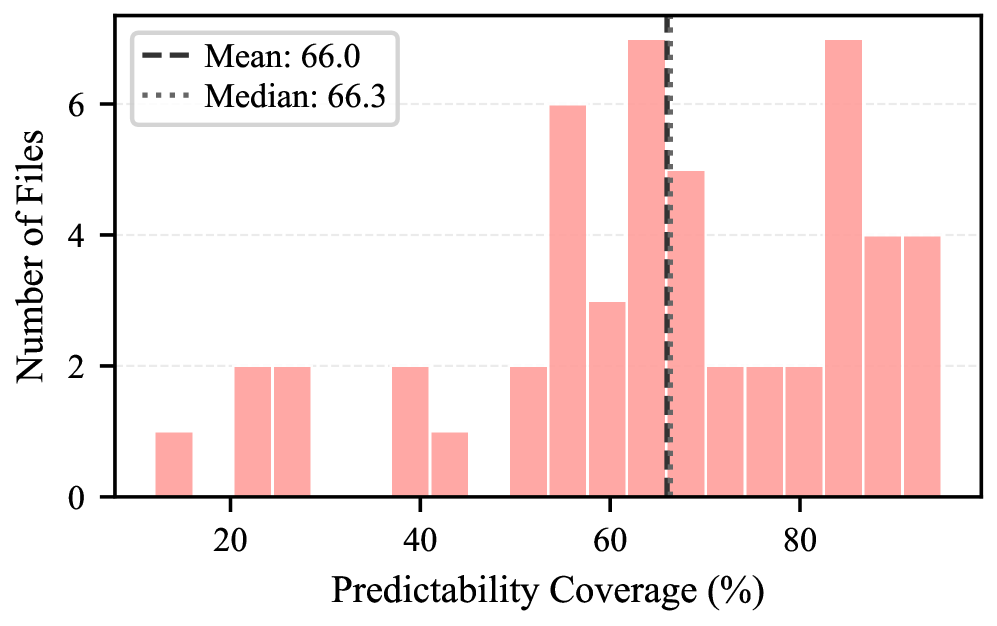
Figure 4 — 온라인 평가 알고리즘
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 symbolic cold-start, LLM refinement, human annotation의 3단계 파이프라인을 통해 총 11,907개의 작업 단계로 구성된 고품질 벤치마크 데이터셋을 구축하였습니다 [Figure 2]. 제안된 온라인 평가 프레임워크는 매 단계마다 모델이 작업을 예측하고, 설정된 heuristic에 따라 이를 수용(accept)하거나 거부(reject)하며, 수용 시 미래 작업 궤적을 동적으로 업데이트합니다 [Figure 4].
주요 실험 결과로서, GPT-5와 같은 대규모 모델이 SmolLM2-360M을 fine-tuning한 모델보다 높은 성능을 보였으나, fine-tuned 모델 또한 충분히 경쟁력 있는 수준(26.8% UAS)에 도달함을 확인하여 해당 작업의 learnability를 입증했습니다 [Table 2]. 특히, 예측을 무조건적으로 수용하는 'always' heuristic은 오히려 사용자에게 부정적인 영향을 주는 것으로 나타나(-19.2% UAS), 모델의 적절한 abstention 전략이 필수적임을 증명했습니다 [Table 5]. 또한, 매 작업마다 모델을 호출하는(s=1) 환경이 더 높은 UAS를 기록하여, 효율적인 트리거 전략의 중요성을 강조했습니다 [Table 3].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 스프레드시트 작업 예측이라는 새로운 도메인에서 벤치마크와 평가 프레임워크를 정립하여 실질적인 자동 완성 시스템 개발의 기반을 마련했습니다. 연구 결과는 단순한 예측 정확도(precision)보다 사용자 경험(UAS)과 수용 heuristic의 중요성을 강조하며, 향후 스프레드시트 생산성 도구의 지능적 설계를 위한 이정표가 될 것입니다. 이 연구는 산업계의 스프레드시트 에이전트 개발과 학계의 human-AI 인터랙션 연구 모두에 의미 있는 기여를 할 것으로 기대됩니다.
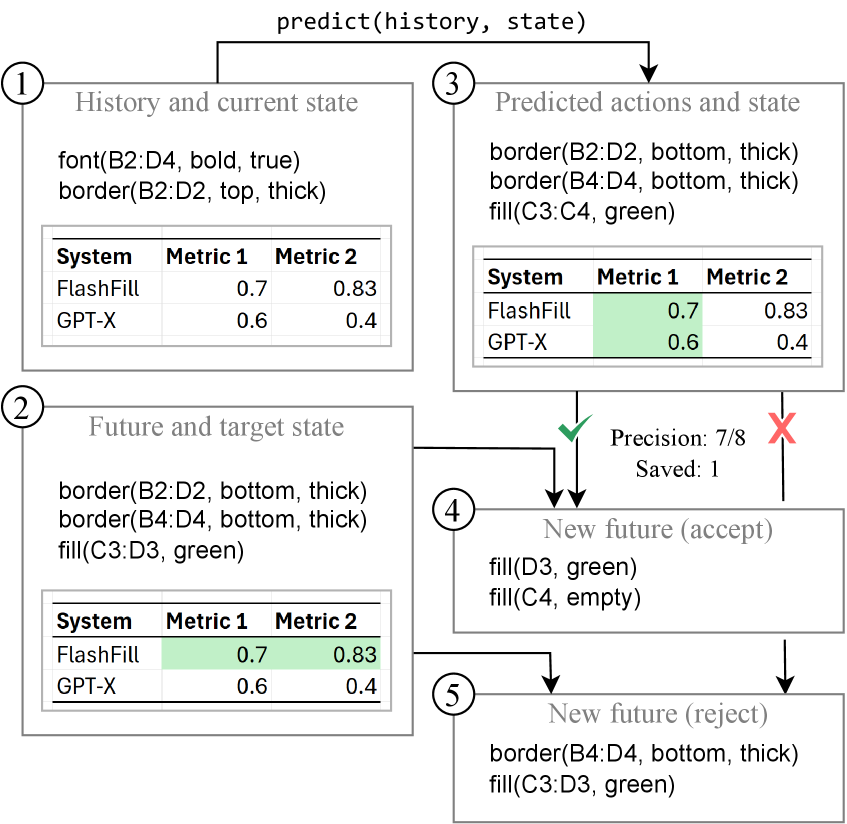
Figure 1 — 온라인 평가 예시
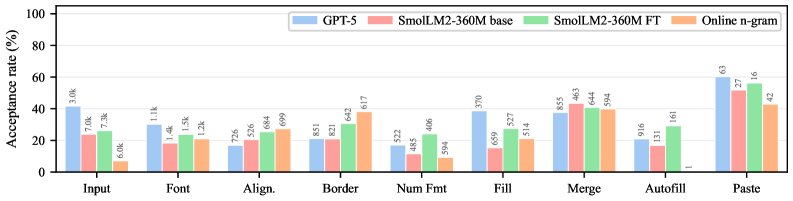
Figure 7 — 카테고리별 수용률 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] No Resource, No Benchmarks, No Problem? Evaluating and Improving LLMs for Code Generation in No-Resource Languages
- [논문리뷰] JAMER: Project-Level Code Framework Dataset and Benchmark on Professional Game Engines
- [논문리뷰] DF3DV-1K: A Large-Scale Dataset and Benchmark for Distractor-Free Novel View Synthesis
- [논문리뷰] Beyond Static Leaderboards: Predictive Validity for the Evaluation of LLM Agents
- [논문리뷰] Physics-IQ Verified
Review 의 다른글
- 이전글 [논문리뷰] Zone of Proximal Policy Optimization: Teacher in Prompts, Not Gradients
- 현재글 : [논문리뷰] A Benchmark and Framework for Evaluating Next Action Predictions in Spreadsheets
- 다음글 [논문리뷰] Bag of Dims: Training-Free Mechanistic Interpretability via Dimension-Level Sign Patterns
댓글