[논문리뷰] ENPIRE: Agentic Robot Policy Self-Improvement in the Real World
링크: 논문 PDF로 바로 열기
메타데이터
저자: Wenli Xiao, Jia Xie, Tonghe Zhang, Haotian Lin, Letian "Max" Fu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Physical Autoresearch: 코딩 에이전트가 실제 물리 환경 내에서 정책을 평가, 검증 및 개선하는 반복적인 폐루프(closed-loop) 연구 과정을 의미합니다.
- ENPIRE: 로봇이 물리적 환경에서 스스로 정책을 개선할 수 있도록 설계된 하네스 프레임워크로, Environment Construction (EN), Policy Improvement (PI), Rollout (R), Evolution (E) 모듈로 구성됩니다.
- MRU (Mean Robot Utilization): 로봇이 연구 목적의 실험 실행에 활발하게 투입된 전체 시간의 비율을 나타내는 지표입니다.
- MTU (Mean Token Utilization): 로봇 함대(fleet)의 전체 오토리스치(autoresearch) 과정에서 소모되는 평균 토큰 소비량을 측정한 지표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 로봇의 Dexterous Manipulation 기술을 습득함에 있어 인간의 개입이 필수적인 현재의 병목 현상을 해결하고자 합니다. 기존의 코딩 에이전트는 디지털 환경에서는 성공적인 성과를 보였으나, 실제 물리적 세계에서는 자동화된 정책 배포, 평가 및 리셋(reset)을 위한 인터페이스가 부족하다는 한계가 있습니다. 이러한 문제를 해결하기 위해 저자들은 물리적 환경에서 반복 가능한 피드백 루프를 실현하는 ENPIRE 프레임워크를 제안합니다 [Figure 2]. 이는 인간의 노동력을 최소화하면서 로봇 스스로 물리 환경과 상호작용하며 성능을 최적화할 수 있도록 지원합니다.
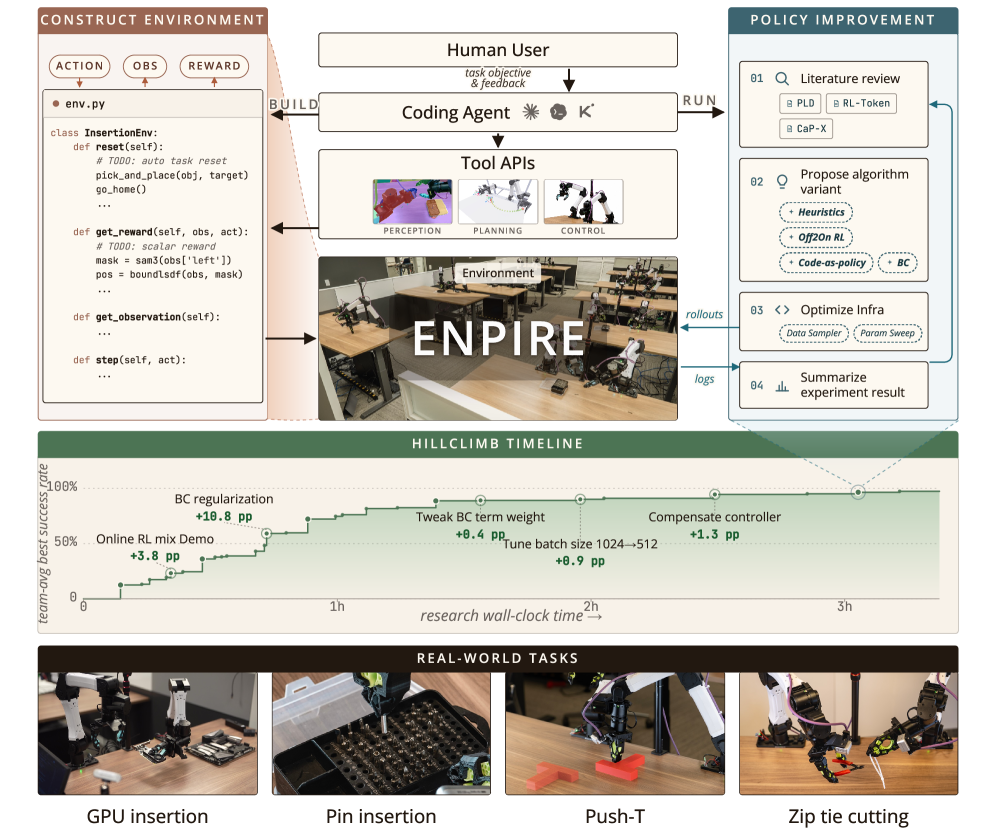
Figure 2 — ENPIRE 프레임워크 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 환경 구성 단계와 정책 개선 단계로 나뉘는 2단계 자동화 연구 방법론을 제안합니다. 첫 번째 단계에서 코딩 에이전트는 인간의 피드백을 바탕으로 자동 리셋 및 검증 메커니즘을 포함한 Environment Module을 구축합니다 [Figure 2]. 두 번째 단계에서는 Policy Improvement Module을 통해 에이전트가 휴리스틱 학습, Behavior Cloning (BC), 강화 학습(RL) 등 다양한 기법을 실험하며 성능을 스스로 hill-climb 합니다. 실험 결과, ENPIRE를 도입한 코딩 에이전트는 Pin Insertion, PushT, Zip-tie cutting과 같은 정교한 작업에서 99% 이상의 성공률을 달성했습니다. 특히 로봇 함대(fleet) 규모를 1대에서 8대로 확장할 경우, Pin Insertion 과업의 성공률 도달 시간이 약 1.5시간에서 40분으로 단축되는 등 파라미터 최적화 및 학습 속도 면에서 뛰어난 효율을 입증했습니다 [Figure 3].
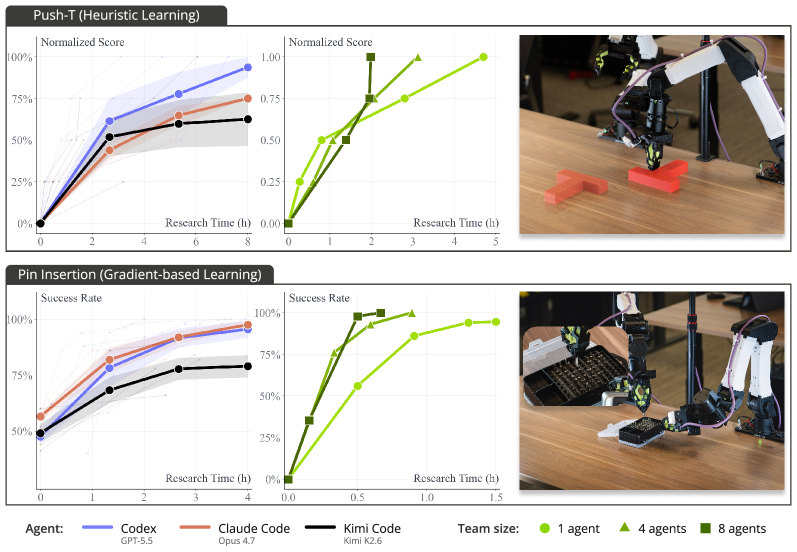
Figure 3 — 로봇 함대 기반 성능 향상 그래프
4. Conclusion & Impact (결론 및 시사점)
본 논문은 물리적 로봇 학습을 에이전트 중심의 제어 가능한 최적화 절차로 전환함으로써 범용 물리 지능(General Physical Intelligence)을 향한 실용적이고 확장 가능한 경로를 제시합니다. 제안된 ENPIRE 프레임워크는 로봇의 하드웨어와 에이전트의 컴퓨팅 자원을 결합하여 로봇 연구의 속도를 비약적으로 향상시킵니다. 본 연구는 향후 로봇공학 분야에서 인간의 개입을 최소화하면서 자율적인 고난도 조작 기술을 습득하게 하는 핵심 인프라로 작용할 것으로 기대됩니다.
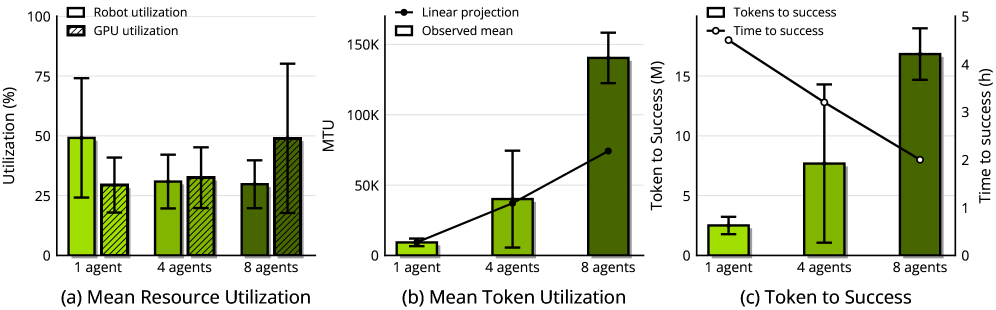
Figure 7 — 에이전트 자원 활용 지표 분석
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] From Trainee to Trainer: LLM-Designed Training Environment for RL with Multi-Agent Reasoning
- [논문리뷰] BenchEvolver: Frontier Task Synthesis via Solution-Centric Evolution
- [논문리뷰] Language Models Need Sleep: Learning to Self-Modify and Consolidate Memories
- [논문리뷰] References Improve LLM Alignment in Non-Verifiable Domains
- [논문리뷰] Self-Improving World Modelling with Latent Actions
Review 의 다른글
- 이전글 [논문리뷰] Duration Aware Scheduling for ASR Serving Under Workload Drift
- 현재글 : [논문리뷰] ENPIRE: Agentic Robot Policy Self-Improvement in the Real World
- 다음글 [논문리뷰] FAPO: Fully Autonomous Prompt Optimization of Multi-Step LLM Pipelines
댓글