[논문리뷰] Multi-LCB: Extending LiveCodeBench to Multiple Programming Languages
링크: 논문 PDF로 바로 열기
메타데이터
저자: Maria Ivanova, Pavel Zadorozhny, Rodion Levichev, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Multi-LCB: 기존 LiveCodeBench(LCB)의 평가 범위를 12개 프로그래밍 언어로 확장한 다국어 코드 생성 벤치마크.
- Pass@1: 모델이 생성한 첫 번째 솔루션이 모든 테스트 케이스를 통과하는 비율로, 코드 생성 모델의 정량적 성능을 측정하는 핵심 Metric.
- STDIN/STDOUT format: 함수 호출 방식이 아닌, 표준 입출력을 통해 데이터를 처리하는 방식으로, 언어 간 차이를 최소화한 통합 평가 포맷.
- Contamination-aware: 모델의 사전 학습 데이터에 평가 데이터가 포함되는 것을 방지하기 위해, 문제의 공개 날짜를 기준으로 테스트셋을 필터링하는 방법론.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 코드 생성 평가가 특정 언어에 편향되어 있어 LLM의 실질적인 다국어 코딩 능력을 측정하지 못하는 한계를 해결하고자 한다. LiveCodeBench(LCB)는 지속적인 업데이트와 엄격한 오염 방지 제어를 통해 우수한 성능을 입증했으나, 오직 Python 언어만을 지원한다는 결정적인 단점이 존재한다 [Figure 1]. 이러한 Python 중심의 평가는 실제 소프트웨어 엔지니어링 환경에서 요구되는 다양한 언어에 대한 일반화 능력을 왜곡할 위험이 있다. 저자들은 이러한 Python 편향성 및 언어별 성능 격차를 체계적으로 진단하기 위해 Multi-LCB를 제안한다.

Figure 1 — Multi-LCB 파이프라인 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 LeetCode, AtCoder, CodeForces에서 수집된 문제를 12개 프로그래밍 언어(C++, C#, Java, Go, JS, TS, Rust, Ruby, PHP, Kotlin, Scala 등)로 변환하여 동일한 STDIN/STDOUT 포맷으로 평가하는 파이프라인을 구축했다 [Figure 1]. 24개의 주요 LLM을 대상으로 한 실험 결과, 대부분의 모델이 Python에서 높은 성능을 보이지만 타 언어에서는 급격한 성능 저하를 보이는 'Python Overfitting' 현상이 확인되었다 [Figure 3]. 특히, 최상위권 모델조차 언어별로 상당한 Pass@1 성능 격차를 나타냈으며, Scala와 같은 언어에서는 성능이 유의미하게 낮게 측정되었다 [Figure 4]. 또한, 제안된 방법론이 기존 LCB의 평가 체계와 높은 일관성을 유지함을 검증하였으며, Pass@1 지표 기준으로 기존 LCB 결과와의 편차는 평균 3% 내외로 안정적임을 확인하였다 [Table 1].
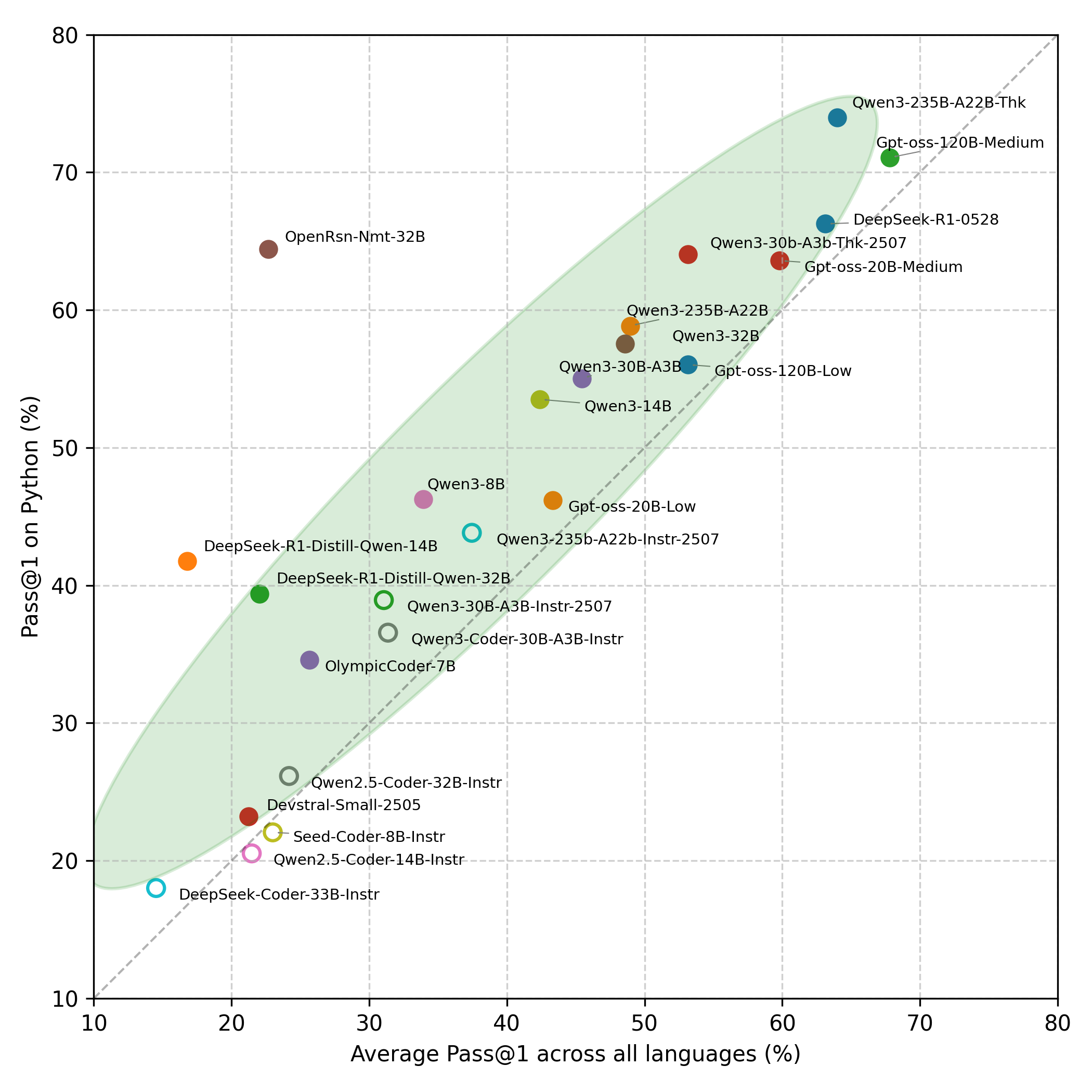
Figure 3 — Python 대 평균 성능 비교
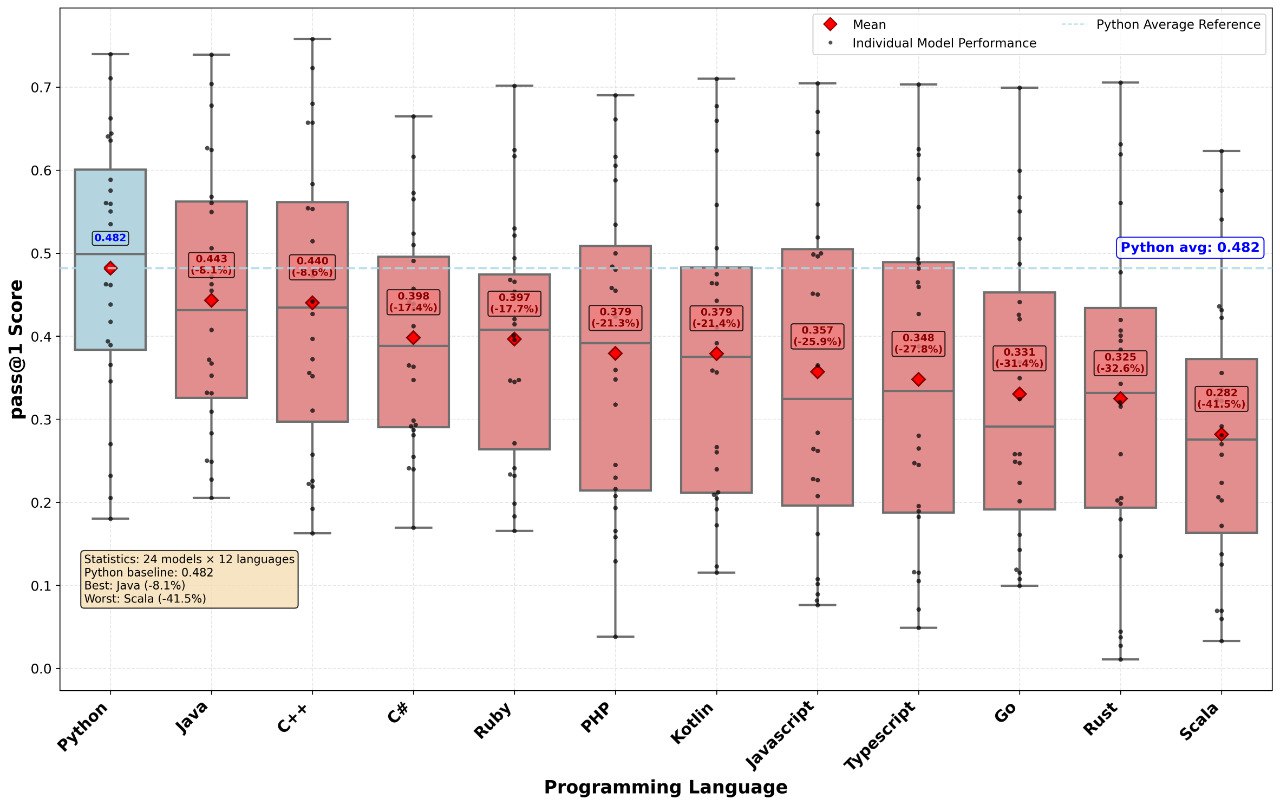
Figure 4 — 언어별 Pass@1 분포
4. Conclusion & Impact (결론 및 시사점)
Multi-LCB는 언어에 종속되지 않는 엄격하고 공정한 코드 생성 평가 환경을 제공함으로써 LLM의 다국어 코딩 역량을 객관적으로 측정할 수 있는 새로운 표준을 제시한다. 이 연구는 단순히 언어별 성능을 비교하는 것을 넘어, 현재 LLM들이 보유한 다국어 코딩 지식의 불균형을 드러내고 향후 모델 개발 방향성에 대한 시사점을 제공한다. 본 연구 결과는 더 나은 다국어 일반화 능력을 갖춘 코드 생성 모델을 설계하고, 효율적인 학습 데이터를 구축하는 데 있어 중요한 기초 자료로 활용될 것이다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] No Resource, No Benchmarks, No Problem? Evaluating and Improving LLMs for Code Generation in No-Resource Languages
- [논문리뷰] Latent Reasoning with Normalizing Flows
- [논문리뷰] Solvita: Enhancing Large Language Models for Competitive Programming via Agentic Evolution
- [논문리뷰] QuantCode-Bench: A Benchmark for Evaluating the Ability of Large Language Models to Generate Executable Algorithmic Trading Strategies
- [논문리뷰] Embarrassingly Simple Self-Distillation Improves Code Generation
Review 의 다른글
- 이전글 [논문리뷰] Moebius: 0.2B Lightweight Image Inpainting Framework with 10B-Level Performance
- 현재글 : [논문리뷰] Multi-LCB: Extending LiveCodeBench to Multiple Programming Languages
- 다음글 [논문리뷰] No Resource, No Benchmarks, No Problem? Evaluating and Improving LLMs for Code Generation in No-Resource Languages
댓글