[논문리뷰] COrigami: An AI Pipeline for Co-Designing Flat-Foldable Visually Recognisable Origami
링크: 논문 PDF로 바로 열기
메타데이터
저자: Tom Zahavy, Shaobo Hou, Thomas Tumiel, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Computational Origami: 종이 접기의 수학적 모델링과 알고리즘을 활용하여 물리적으로 유효한 접기 구조를 설계하는 분야입니다.
- Box Pleating: 직사각형의 그리드(Grid)를 기반으로 축과 평행한 주름을 배치하여 복잡한 형태를 만드는 종이 접기 기법입니다.
- Flat-Foldability: 특정 crease pattern이 겹침이나 찢어짐 없이 2D 평면으로 완전히 접힐 수 있는 수학적 상태를 의미합니다.
- Stick Figure: 종이 접기 모델의 3D 골격 구조를 정의하는 추상화된 트리 데이터 구조입니다.
- VLM (Vision-Language Model): 생성된 3D 접기 모델을 시각적으로 평가하고, 물리적 실현 가능성과 미적 완성도에 대한 보상 신호를 제공하는 핵심 피드백 엔진입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대의 생성형 AI가 물리적인 제약 조건과 인간의 미적 취향을 동시에 만족시키는 물리적 예술 작품을 설계하는 데 한계가 있다는 점을 지적합니다. 기존의 computational origami 도구들은 주로 연속적인 공간 최적화에 의존하여 인간이 직접 수행하기 어려운 비현실적인 설계 결과를 도출하거나, 수작업이 많이 필요한 비효율성을 보입니다 [Table 1]. 특히, 복잡한 crease pattern을 생성할 때 발생하는 미세한 토큰 오류가 전체 구조의 Flat-Foldability를 파괴하는 현상이 고질적인 문제로 제기됩니다. 저자들은 이러한 한계를 극복하기 위해 자연어로부터 물리적으로 검증 가능한 구조를 생성하는 통합 파이프라인이 필요하다고 강조합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Gemini 기반의 신경망 모델과 고전적인 기하학적 알고리즘을 결합한 end-to-end neuro-symbolic 파이프라인 COrigami를 제안합니다 [Figure 4]. 이 파이프라인은 크게 1) 의미론적 Stick Figure 생성, 2) 그리드 기반의 최적화된 Packing 및 Solving, 3) Reinforcement Learning을 활용한 미학적 Shaping 단계로 구성됩니다. 제안된 방법론은 기존 연구들과 달리 Box Pleating 그리드 위에서 수학적으로 보장된 Flat-Foldable crease pattern을 자동으로 생성합니다 [Table 1]. 특히, VLM 평가 루프를 도입하여 물리적 타당성과 미적 일치도를 동시에 평가함으로써, 단순한 골격 재구성을 넘어선 고도로 실현 가능한 예술적 모델을 완성합니다 [Figure 4]. 실험 결과, COrigami는 수작업 보조 없이도 완벽한 2D tiling과 Flat-Foldability를 보장하며, 복잡한 형태 생성 시 기존 모델 대비 뛰어난 정성적 품질과 70% 이상의 높은 평가 정확도(Accuracy)를 달성하였습니다 [Table 2].
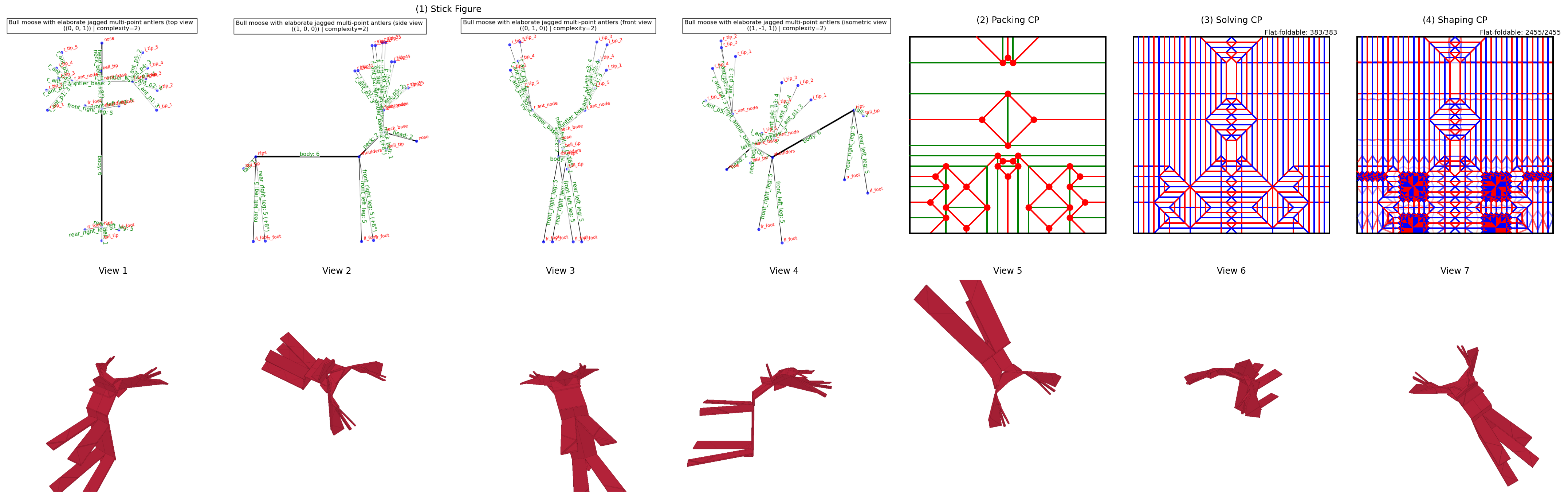
Figure 4 — COrigami 설계 프로세스
4. Conclusion & Impact (결론 및 시사점)
본 연구는 고도로 제약된 수학적 환경에서 AI가 인간과 협업하여 창의적이고 복잡한 물리적 형태를 설계할 수 있음을 입증했습니다. COrigami는 단순한 생성형 도구를 넘어, 구조적 무결성과 예술적 완성도를 동시에 만족시키는 차세대 설계 파이프라인으로서의 가능성을 제시합니다. 이러한 접근 방식은 물리적 제약이 중요한 건축, 로봇 공학 등 다양한 분야의 설계 자동화 연구에 중요한 방법론적 토대를 제공할 것으로 기대됩니다.
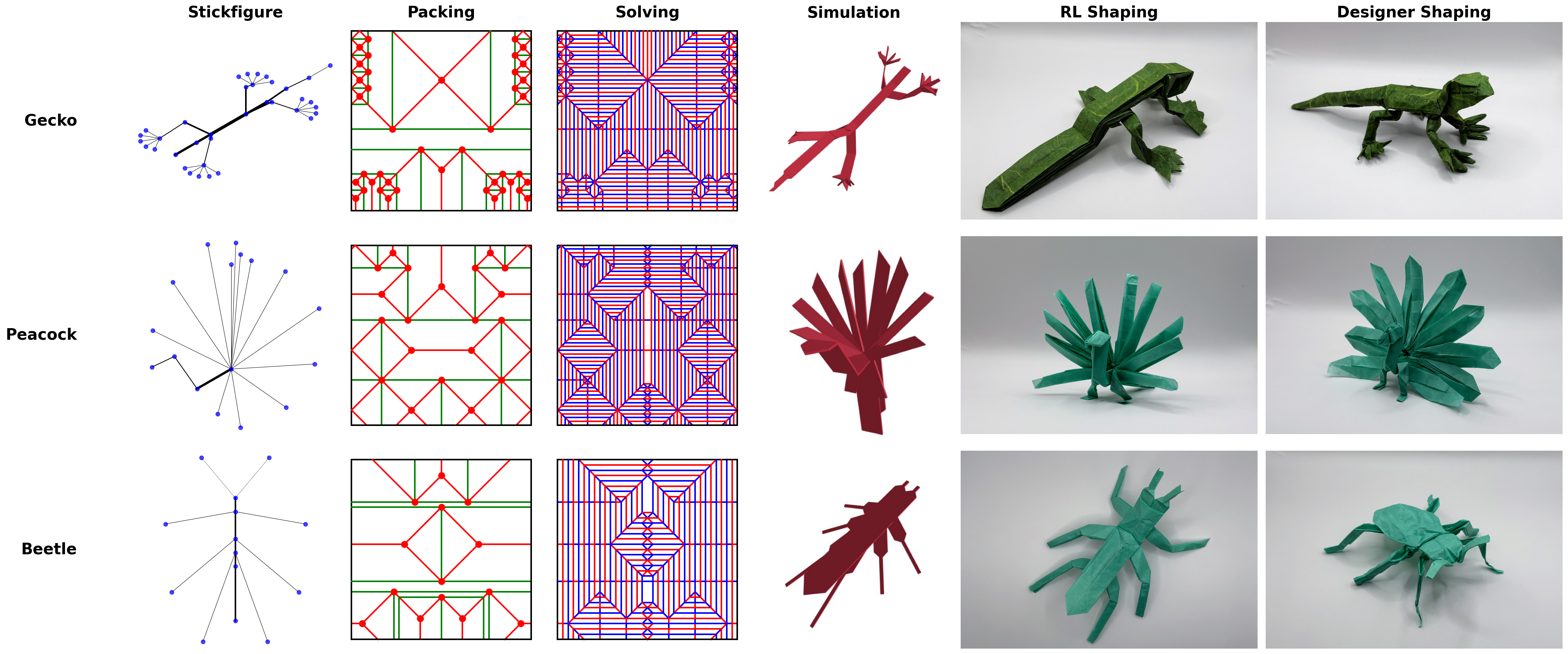
Figure 1 — COrigami 파이프라인 개요

Figure 5 — 결정론적 솔빙 단계
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Stable-Layers: Fine-Tuning Image Layer Decomposition Models with VLM-Scored Reinforcement Learning
- [논문리뷰] Code2World: A GUI World Model via Renderable Code Generation
- [논문리뷰] Innovator-VL: A Multimodal Large Language Model for Scientific Discovery
- [논문리뷰] LightOnOCR: A 1B End-to-End Multilingual Vision-Language Model for State-of-the-Art OCR
- [논문리뷰] Video-as-Answer: Predict and Generate Next Video Event with Joint-GRPO
Review 의 다른글
- 이전글 [논문리뷰] When Lower Privileges Suffice: Investigating Over-Privileged Tool Selection in LLM Agents
- 현재글 : [논문리뷰] COrigami: An AI Pipeline for Co-Designing Flat-Foldable Visually Recognisable Origami
- 다음글 [논문리뷰] CoffeeBench: Benchmarking Long-Horizon LLM Agents in Heterogeneous Multi-Agent Economies
댓글