[논문리뷰] Running the Gauntlet: Re-evaluating the Capabilities of Agents Beyond Familiar Environments
링크: 논문 PDF로 바로 열기
저자: Mykola Vysotskyi, Runqi Lin, Grzegorz Biziel, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- GauntletBench: 본 논문에서 제안하는 웹 기반의 새로운 벤치마크로, 에이전트의 일반화 능력을 평가하기 위해 시각적 이해와 추론이 필수적인 5개의 전문 응용 프로그램을 포함함.
- Agentic Systems: 자율적인 상호작용과 복잡한 작업 수행을 위해 구축된 지능형 에이전트 시스템을 지칭함.
- Vision-Intensive Tasks: UI의 시각적 요소(스크린샷 등)를 해석하고 그에 따른 기하학적, 논리적 추론이 수반되어야 완료 가능한 고난도 작업을 의미함.
- MLLM (Multimodal Large Language Model): 텍스트뿐만 아니라 시각적 정보를 처리할 수 있는 대규모 언어 모델로, 본 연구에서는 에이전트의 중추적인 두뇌 역할을 수행함.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 기존 에이전트 벤치마크들이 지나치게 단순한 작업이나 친숙한 웹 환경에만 치중하여 현대 에이전트의 잠재적 한계를 적절히 탐지하지 못한다는 문제의식에서 출발한다. 기존 벤치마크는 주로 온라인 쇼핑이나 단순 정보 검색과 같은 소비자 중심의 작업을 대상으로 하므로, 에이전트의 성능이 조기에 포화되는 현상을 보인다. 저자들은 실제 복잡한 환경에서의 자율성을 평가하기 위해서는 Temporal perception, Graphical understanding, 3D reasoning과 같이 기존 벤치마크에서 간과된 영역의 평가가 필수적임을 강조하며, 이를 위한 새로운 전문적 응용 프로그램 테스트베드를 구축하였다. [Figure 1]은 이러한 배경 하에 설계된 5개 전문 응용 프로그램의 개요를 나타낸다.
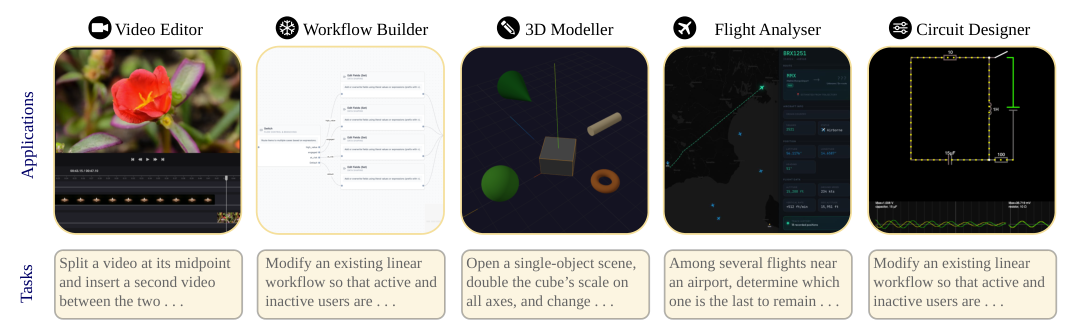
Figure 1 — 본 연구에서 구축한 5가지 핵심 전문 응용 프로그램 환경을 시각적으로 요약한 다이어그램
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 연구는 5개의 독창적인 웹 환경(Video Editor, Workflow Builder, 3D Modeller, Flight Analyser, Circuit Designer)과 총 100개의 과제로 구성된 GauntletBench를 도입하였다. 제안된 환경은 모듈화된 파이프라인을 통해 다양한 오픈소스 및 폐쇄형 에이전트 프레임워크와의 호환성을 제공하며, 개별 응용 프로그램에 특화된 정밀 평가 엔진을 포함한다. [Table 2]에서 제시된 정량적 실험 결과에 따르면, SOTA 모델인 Claude-Opus-4.6 Computer Use조차 본 벤치마크에서 19.1%의 낮은 성공률을 기록하여, 인간 참여자의 80%가 넘는 성공률과 극명한 대비를 보였다. 대부분의 오픈소스 MLLM은 사실상 0%에 가까운 성공률을 보였으며, 이는 기존 모델들이 고도의 시각적 추론과 다단계 복합 작업 수행 능력에서 여전히 큰 결함을 가지고 있음을 시사한다. 특히 시각 정보의 중요성을 입증한 실험에서, 시각 입력을 제거할 경우 작업 완료 능력이 급격히 저하되는 결과를 확인하였다.
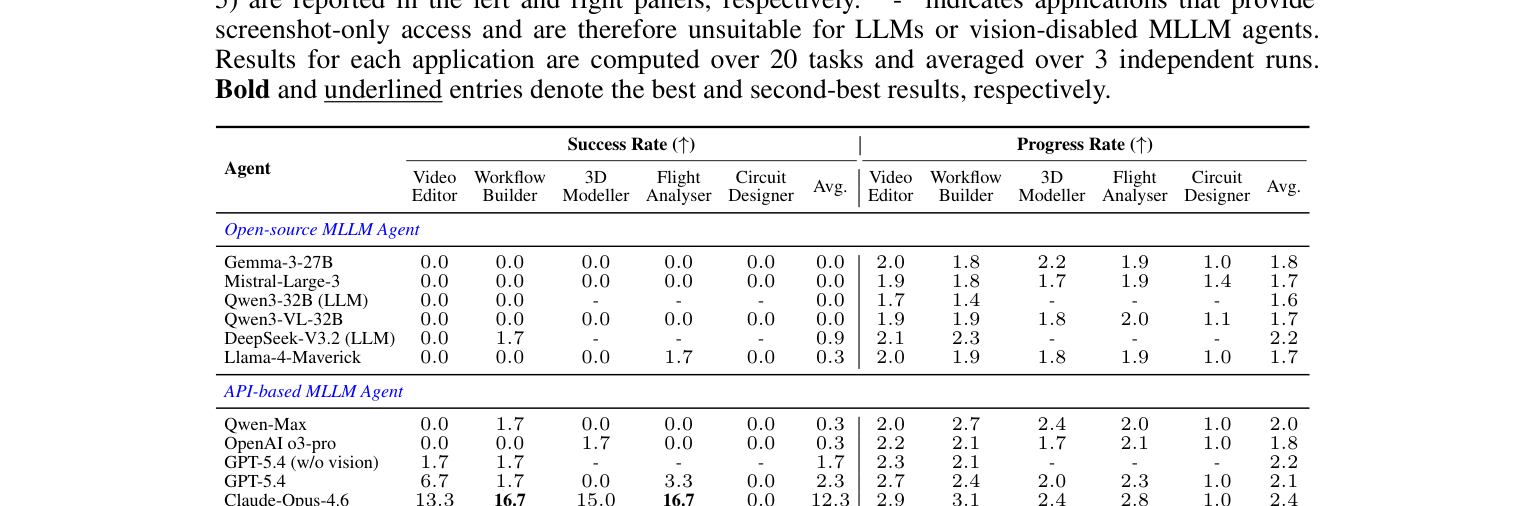
Table 2 — 다양한 모델별 성공률과 진척도를 비교한 핵심 실험 결과 테이블
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 현재의 최첨단 에이전트 시스템이 실제 복잡한 환경에서 요구되는 고차원적인 인지 능력을 발휘하기에는 인간 수준에 훨씬 미치지 못함을 실증적으로 입증하였다. 연구 결과는 단순한 모델 크기 확대나 추가 학습만으로는 해결할 수 없는 근본적인 추론 및 일반화의 한계를 지적하며, 향후 에이전트 연구가 보다 역동적이고 시각적으로 복잡한 환경에서의 신뢰성 확보에 집중해야 함을 제안한다. 본 연구는 차세대 지능형 에이전트 개발을 위한 보다 엄격하고 현실적인 평가 표준을 마련함으로써, 관련 분야의 학계 및 산업계 연구 방향에 중요한 이정표를 제시할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Act Wisely: Cultivating Meta-Cognitive Tool Use in Agentic Multimodal Models
- [논문리뷰] Illuminating Unified Multimodal Model for Free-form Interleaved Text-Image Generation
- [논문리뷰] ViQ: Text-Aligned Visual Quantized Representations at Any Resolution
- [논문리뷰] In-Context World Modeling for Robotic Control
- [논문리뷰] How Post-Training Shapes Biological Reasoning Models
Review 의 다른글
- 이전글 [논문리뷰] Qwen-Image-Agent: Bridging the Context Gap in Real-World Image Generation
- 현재글 : [논문리뷰] Running the Gauntlet: Re-evaluating the Capabilities of Agents Beyond Familiar Environments
- 다음글 [논문리뷰] The Verification Horizon: No Silver Bullet for Coding Agent Rewards
댓글