[논문리뷰] Focusing on What Matters: Saliency-Harnessing Accurate Routing for Diffusion MoE
링크: 논문 PDF로 바로 열기
메타데이터
저자: Haoyou Deng, Keyu Yan, Chaojie Mao, Xiang Wang, Yu Liu, Changxin Gao, Nong Sang
1. Key Terms & Definitions (핵심 용어 및 정의)
- SharpMoE: 노이즈가 제거된 Clean Latent를 활용하여 Saliency 기반의 정밀한 Expert Routing을 수행하는 post-training 프레임워크입니다.
- Noisy Routing Problem: 기존 Diffusion MoE 모델들이 노이즈가 섞인 Latent를 Routing 입력으로 사용하여, 중요도가 높은 Salient Token을 제대로 식별하지 못하고 비효율적인 연산을 수행하는 문제를 지칭합니다.
- Recursive Full-Trajectory Training: 이전 Denoising Step에서 예측된 Clean Latent를 현재 Step의 Routing에 활용하기 위해 전체 Denoising 과정을 재귀적으로 시뮬레이션하며 학습하는 방법론입니다.
- Trajectory Routing Loss: 전체 Denoising 궤적에 걸쳐 Expert 할당이 이미지의 Saliency 분포와 일치하도록 제약하는 손실 함수입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 기존 Diffusion MoE 프레임워크에서 발생하는 불균형한 계산 자원 배분 문제를 해결하고자 합니다. 최근 Diffusion 모델의 규모를 키우기 위해 MoE 아키텍처가 도입되었으나, 기존 라우터(Router)들은 Denoising 과정의 노이즈(Noise)에 오염된 Latent를 사용하여 Salient Token을 정확하게 구별하지 못합니다 [Figure 1]. 이러한 'Noisy Routing'은 결과적으로 구조적·질감적 상세 정보가 필요한 영역에 충분한 Expert를 할당하지 못하게 만들어, 최종적인 이미지 생성 품질을 저하시키는 원인이 됩니다. 따라서 본 연구는 노이즈로부터 자유로운 명확한 Saliency 가이던스를 라우터에 제공할 새로운 메커니즘을 제안합니다.
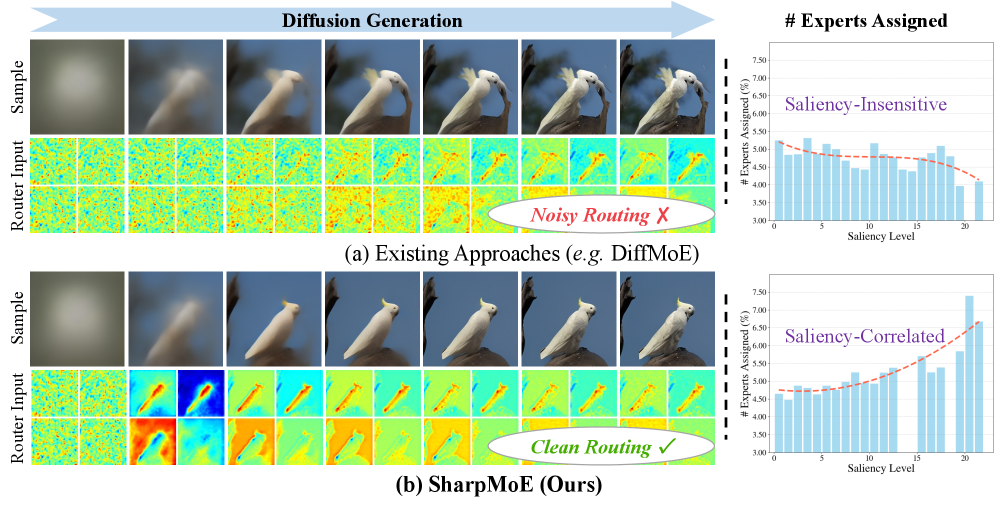
Figure 1 — 기존 라우팅 문제와 SharpMoE의 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Clean Latent인 $\hat{\mathbf{x}}_0$ 예측값을 라우팅의 입력으로 사용하는 Saliency-Harnessing Accurate Routing 메커니즘을 도입합니다 [Figure 2]. 제안된 SharpMoE는 기존 Pretrained 라우터와 새로 추가된 Saliency-Harnessing 라우터의 출력을 결합하여, 이미지의 구조적 골격을 기반으로 한 정밀한 Expert 배분을 수행합니다. 또한, Re-cursive Full-Trajectory Training을 통해 이전 Step의 예측값을 활용하여 학습하며, Trajectory Routing Loss를 통해 전체 생성 과정에서의 자원 배분을 Saliency 수준에 맞게 최적화합니다. 실험 결과, SharpMoE는 DiffMoE-L 기반 환경에서 기존 모델 대비 FID 점수를 유의미하게 개선하며 SOTA 성능을 달성했습니다 [Table 1]. 특히, cfg=1.5 조건에서 FID를 3.10까지 낮추고 IS를 228.88로 향상시키는 등, 모든 모델 스케일과 CFG 스케일에서 일관된 성능 우위를 보였습니다 [Table 1]. 또한, Saliency-Harnessing Routing과 Trajectory Routing Loss를 각각 적용했을 때 FID가 8.03에서 6.95, 그리고 최종적으로 6.66으로 개선됨을 확인하였습니다 [Table 2].
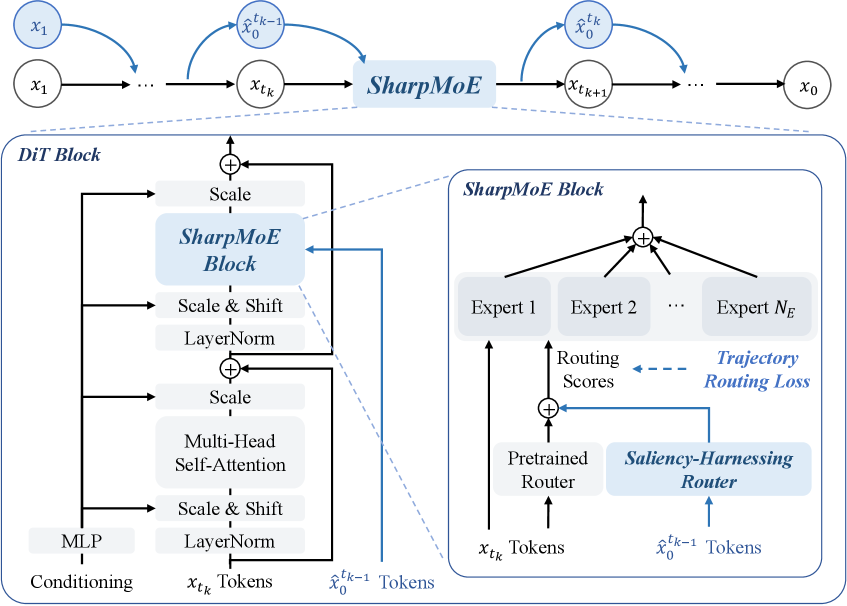
Figure 2 — SharpMoE 전체 아키텍처
4. Conclusion & Impact (결론 및 시사점)
본 논문은 노이즈에 강인한 Clean Latent 기반의 라우팅 기법인 SharpMoE를 통해 Diffusion MoE 모델의 자원 배분 효율성을 극대화하였습니다. 이 연구는 기존의 수렴된 Pretrained 모델에 추가적인 Fine-tuning 없이 Plug-and-Play 방식으로 성능 향상을 끌어낼 수 있다는 점에서 높은 실용성을 가집니다. 제안된 방법론은 고해상도 시각 생성 분야에서 계산 효율성과 생성 품질이라는 두 마리 토끼를 잡을 수 있는 핵심적인 아키텍처 개선책으로 기여할 것으로 기대됩니다.

Figure 3 — SharpMoE 정성적 생성 결과
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] PISCES: Annotation-free Text-to-Video Post-Training via Optimal Transport-Aligned Rewards
- [논문리뷰] What about gravity in video generation? Post-Training Newton's Laws with Verifiable Rewards
- [논문리뷰] PhotoQuilt: Training-Free Arbitrary-Resolution Photomosaics via Bootstrapped Tiled Denoising
- [논문리뷰] Scaling the Horizon, Not the Parameters: Reaching Trillion-Parameter Performance with a 35B Agent
- [논문리뷰] LiveEdit: Towards Real-Time Diffusion-Based Streaming Video Editing
Review 의 다른글
- 이전글 [논문리뷰] DreamForge-World 0.1 Preview: A Low-Compute Real-Time Controllable World Model
- 현재글 : [논문리뷰] Focusing on What Matters: Saliency-Harnessing Accurate Routing for Diffusion MoE
- 다음글 [논문리뷰] GUICrafter: Weakly-Supervised GUI Agent Leveraging Massive Unannotated Screenshots
댓글