[논문리뷰] OSWorld2.0: Benchmarking Computer Use Agents on Long-Horizon Real-World Tasks
링크: 논문 PDF로 바로 열기
메타데이터
저자: Mengqi Yuan, Zilong Zhou, Xinzhuang Xiong, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Computer-Use Agents: 자연어 명령을 기반으로 웹 브라우저, 데스크톱 앱, 문서 편집 등 실제 컴퓨터 환경에서 자율적으로 업무를 수행하는 인공지능 에이전트.
- Long-Horizon Tasks: 단순한 1~2회의 동작이 아니라, 여러 애플리케이션을 넘나들며 수백 단계의 중간 과정을 거쳐야 완성되는 장기적 업무 흐름.
- Challenge Phenomena: 실제 업무 환경에서 빈번하지만 기존 벤치마크에서는 간과되었던 고난도 수행 요소 (예:
Streaming Interaction,Implicit-State Inference,Conflict Disambiguation). - Binary Completion: 모든 단계가 완벽히 수행되어 최종 목표가 달성되었는지 여부를 판단하는 엄격한 평가 지표.
- Partial Score: 전체 작업 완료와 별개로, 작업 중간 단계에서 달성한 성취도를 측정하여 에이전트의 부분적 기여도를 평가하는 지표.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 컴퓨터 사용 벤치마크들이 지나치게 단기적이고 단순한 작업 위주로 구성되어 있어, 실제 실무 환경에서의 복잡한 Long-Horizon 업무를 평가하기에 한계가 있다는 점을 지적한다. 현재의 Frontier Agents들은 짧고 명확한 동작 수행에는 능숙하지만, 복합적인 실무 환경에서 요구되는 지속적인 의사결정이나 장기적 업무 완수에는 여전히 어려움을 겪고 있다 [Figure 1]. 이러한 불일치는 AI 에이전트의 실제 실무 능력을 과대평가하게 만들며, 정작 필요한 고난도 작업에서의 에이전트 성능을 측정하지 못하게 한다. 따라서 본 연구는 실제 실무 업무의 복잡성과 긴 호흡을 반영한 차세대 벤치마크 프레임워크인 OSWorld 2.0을 제안한다.
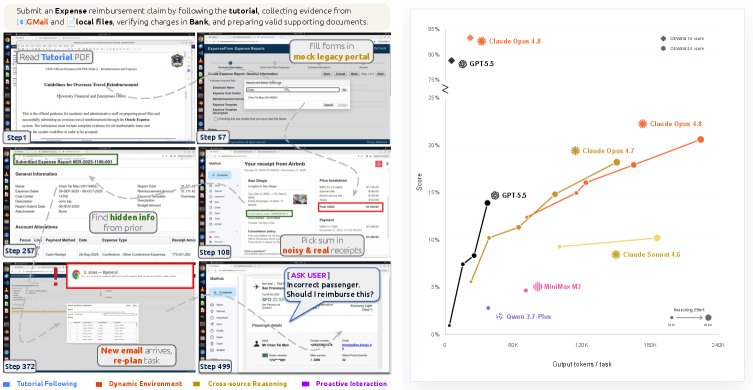
Figure 1 — OSWorld 2.0 개요 및 모델 성능 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 실제 전문가의 업무 흐름을 반영한 108개의 Long-Horizon 작업들로 구성된 OSWorld 2.0을 통해 에이전트를 평가하는 프레임워크를 제안한다 [Figure 2]. 각 작업은 실제 환경(웹 서비스, 데스크톱 앱)과 유기적으로 연동되며, 에이전트가 중간에 발생하는 환경 변화나 새로운 제약 조건을 실시간으로 추적해야 하도록 설계되었다 [Figure 2]. 성능 평가를 위해 기존의 이분법적 평가 방식을 탈피하여 Fine-grained partial reward 시스템을 도입하였으며, 모델 기반 평가와 기능적 상태 검증을 결합하여 평가의 객관성을 확보하였다. 실험 결과, Claude Opus 4.8이 가장 우수한 성능을 보였으나 Binary Completion 기준으로는 20.6%의 성공률에 그쳤으며, GPT-5.5는 훨씬 적은 토큰 비용으로 13% 내외의 성공률을 기록하였다 [Figure 1]. 결과적으로, 에이전트들은 개별 UI 조작은 성공해도 복잡한 작업 흐름 전체를 관통하는 제약 조건을 유지하거나, 중간에 누락된 정보를 스스로 발견하여 수정하는 능력(Error Detection & Repair)이 크게 부족함이 드러났다.

Figure 2 — OSWorld 2.0 작업 구축 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 논문은 OSWorld 2.0을 통해 현재의 최첨단 AI 에이전트들이 실무 수준의 장기 업무를 수행하기에는 아직 큰 격차가 존재함을 명확히 입증하였다. 에이전트 성능 향상을 위해서는 단순히 컴퓨팅 리소스나 작업 시간(Horizon)을 늘리는 것보다, 복잡한 환경 상태를 장기 기억하고 스스로의 실수를 수정할 수 있는 메커니즘을 내재화하는 것이 필수적이다. 이 연구는 향후 범용 에이전트 개발이 나아가야 할 방향성을 제시하며, 학계와 산업계 모두에 실무 중심의 고차원 AI 에이전트 평가 체계를 제공한다는 점에서 의의가 크다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] AgentVista: Evaluating Multimodal Agents in Ultra-Challenging Realistic Visual Scenarios
- [논문리뷰] OSWorld-MCP: Benchmarking MCP Tool Invocation In Computer-Use Agents
- [논문리뷰] MyPCBench: A Benchmark for Personally Intelligent Computer-Use Agents
- [논문리뷰] AutoMedBench: Towards Medical AutoResearch with Agentic AI Models
- [논문리뷰] TerminalWorld: Benchmarking Agents on Real-World Terminal Tasks
Review 의 다른글
- 이전글 [논문리뷰] Nemotron-Labs-Diffusion-Image: Advancing Masked Discrete Diffusion for High-Resolution Image Synthesis
- 현재글 : [논문리뷰] OSWorld2.0: Benchmarking Computer Use Agents on Long-Horizon Real-World Tasks
- 다음글 [논문리뷰] One Forward Beats Two: InnerZoom for Accurate and Efficient GUI Grounding
댓글