[논문리뷰] DataEvolver: Self-Evolving Multi-Agent Data Construction for Text-Rich Image Generation
링크: 논문 PDF로 바로 열기
저자: Siyu Yan, Yizhen Gao, Yilin Wang, Dongxing Mao, Alex Jinpeng Wang
1. Key Terms & Definitions (핵심 용어 및 정의)
- DataEvolver: Text-rich image 생성을 위한 다중 에이전트(Multi-Agent) 데이터 구축 프레임워크로, 실패한 샘플을 단순 폐기하지 않고 학습 피드백으로 활용하여 구축 정책을 반복적으로 진화시킴.
- Construction Policy ($\pi_t$): 데이터 수집 및 생성을 제어하는 정책으로, Retriever(쿼리 정책), Generator(프롬프트 정책), 그리고 Experience Library(과거 경험 메모리)로 구성됨.
- Critic: 구축 라운드별 피드백($s_t$)을 분석하여 모델 파라미터 업데이트 없이 자연어 기반의 의미론적 피드백(Semantic Feedback)을 생성하고, 이를 통해 다음 라운드의 정책을 개선하는 핵심 에이전트.
- OCR-F1: 텍스트가 포함된 이미지 생성 품질을 측정하기 위한 지표로, PaddleOCR을 활용해 텍스트 정밀도(Precision)와 재현율(Recall)을 종합하여 산출함.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존의 Text-rich image 데이터 구축 방식은 고정된 텍스트 크롤링 및 필터링(Crawl-filter-freeze paradigm)에 의존하고 있어, 데이터 구축 과정에서 발생하는 다양한 실패 사례를 유의미한 정보로 활용하지 못하는 한계가 있습니다. 특히 OCR 오류나 의미론적 불일치와 같은 반복적인 실패 유형들이 데이터 구성의 질적 저하를 초래함에도 불구하고 단순 폐기되는 실정입니다. 본 연구는 이러한 실패 사례가 데이터 구축 정책을 개선할 수 있는 강력한 진단 도구가 될 수 있다는 점에 주목합니다. 따라서 저자들은 폐기되는 샘플들을 능동적인 피드백 루프로 변환하여 데이터 구축 과정을 스스로 진화시키는 프레임워크를 제안합니다 [Figure 1].
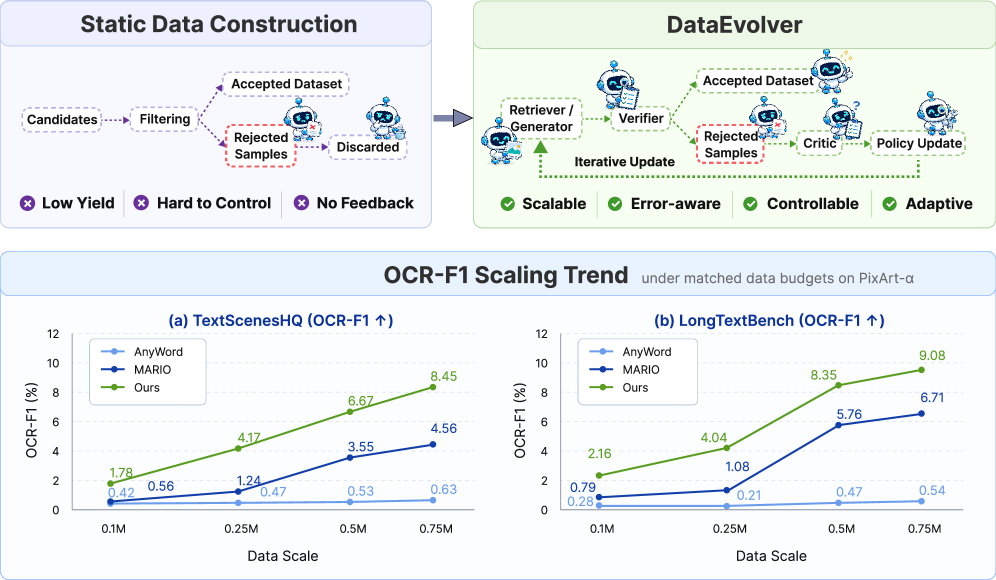
Figure 1 — DataEvolver 피드백 루프 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Retriever, Verifier, Critic, Generator라는 4개의 협력 에이전트로 구성된 DataEvolver를 제안하며, 이들은 폐쇄형 루프(Closed-loop)를 통해 지속적으로 구축 정책을 업데이트합니다 [Figure 2]. Retriever는 정책에 따라 후보군을 수집하고, Verifier는 필터링을 수행함과 동시에 실패 원인을 기록하며, Critic은 이 피드백을 바탕으로 쿼리와 프롬프트를 개선합니다 [Figure 3]. 마지막으로, Generator는 데이터 커버리지가 부족한 영역(Coverage Gaps)을 타겟팅하여 합성 데이터로 보완합니다. PixArt-α 기반 0.75M 데이터 규모 실험 결과, DataEvolver는 기존 최강 Baseline 대비 TextScenesHQ에서 OCR-F1을 85.3%, LongTextBench에서 35.3% 향상시키는 성과를 거두었습니다 [Table 1]. 이러한 개선은 Show-o2와 같은 다른 모델에서도 일관되게 관찰되어, 특정 모델에 국한되지 않는 범용적인 데이터 구축 기법임을 입증하였습니다.
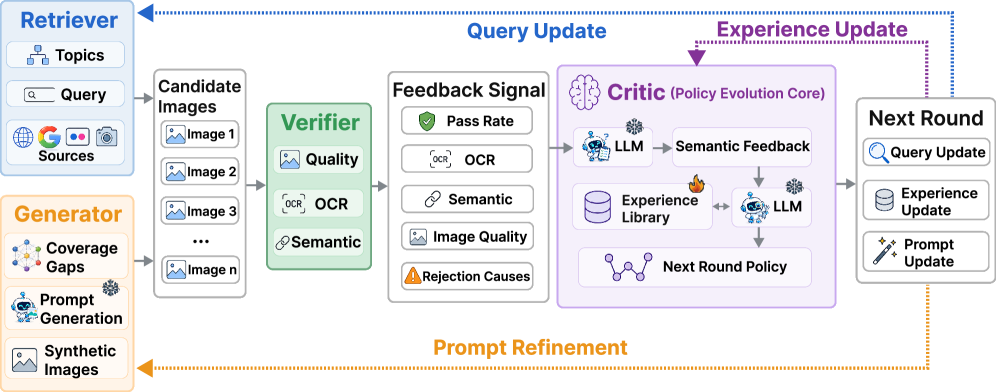
Figure 2 — DataEvolver 4단계 워크플로우

Figure 3 — Critic 기반 정책 업데이트 예시
4. Conclusion & Impact (결론 및 시사점)
본 논문은 데이터 구축을 고정된 파이프라인이 아닌 피드백 기반의 정책 진화 과정으로 재정의하였습니다. 제안하는 DataEvolver는 rejected samples의 정보를 성공적으로 추출하여 구축 효율을 높이고 데이터의 커버리지를 비약적으로 개선했습니다. 이 연구는 고품질의 텍스트 생성 모델을 위해 데이터셋 구축 방식 자체가 어떻게 능동적으로 개선될 수 있는지를 보여주며, 향후 멀티모달 데이터 생성 분야에서 데이터 중심(Data-centric) AI 방법론의 새로운 방향을 제시합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Data Journalist Agent: Transforming Data into Verifiable Multimodal Stories
- [논문리뷰] Orchestra-o1: Omnimodal Agent Orchestration
- [논문리뷰] DuMate-DeepResearch: An Auditable Multi-Agent System with Recursive Search and Rubric-Grounded Reasoning
- [논문리뷰] EvoDS: Self-Evolving Autonomous Data Science Agent with Skill Learning and Context Management
- [논문리뷰] Economy of Minds: Emerging Multi-Agent Intelligence with Economic Interactions
Review 의 다른글
- 이전글 [논문리뷰] DOPD: Dual On-policy Distillation
- 현재글 : [논문리뷰] DataEvolver: Self-Evolving Multi-Agent Data Construction for Text-Rich Image Generation
- 다음글 [논문리뷰] Dockerless: Environment-Free Program Verifier for Coding Agents
댓글