[논문리뷰] QVal: Cheaply Evaluating Dense Supervision Signals for Long-Horizon LLM Agents
링크: 논문 PDF로 바로 열기
메타데이터
저자: Sergio Hernández-Gutiérrez, Matteo Merler, Ilze Amanda Auzina, Joschka Strüber, Ameya Prabhu, Matthias Bethge
1. Key Terms & Definitions (핵심 용어 및 정의)
- Q-alignment: 모델이 생성한 dense supervision 점수가 에이전트의 최종 성공 가능성을 반영하는 참조 정책의 Q-value와 얼마나 일관되게 순위를 매기는지 측정하는 지표입니다.
- Dense Supervision: 긴 호라이즌 작업에서 에이전트의 중간 단계 동작(intermediate steps)에 대해 보상을 부여하여 학습 효율을 높이는 피드백 신호입니다.
- Training-Free Testbed: 실제 RL 학습 과정을 거치지 않고도 사전에 정의된 데이터셋과 참조값을 기반으로 supervision 신호의 품질을 평가할 수 있는 프레임워크입니다.
- QVal-v1.0: 본 논문에서 제안한 21개의 dense supervision 방법을 4개의 환경과 6개의 모델 백본에서 평가하기 위해 구축한 벤치마크 데이터셋입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Long-horizon LLM Agent의 학습을 저해하는 희소 보상(Sparse Reward) 문제를 해결하기 위한 dense supervision 방법론들을 효율적으로 평가하고자 합니다 [Figure 1]. 기존에는 이러한 방법들을 평가하기 위해 방대한 컴퓨팅 자원을 소모하는 실제 RL 학습 파이프라인을 구축해야 했으며, 이는 평가 과정에 알고리즘, 최적화 방식 등 다양한 공학적 변수가 섞여 신호 자체의 품질을 독립적으로 측정하기 어렵게 만들었습니다. 결과적으로 서로 다른 방법론을 공정한 기준에서 비교하기가 매우 어려웠습니다. 저자들은 학습 과정 없이도 dense supervision 신호를 직접 평가할 수 있는 QVal 프레임워크를 통해 이러한 문제점을 해결하고자 합니다.
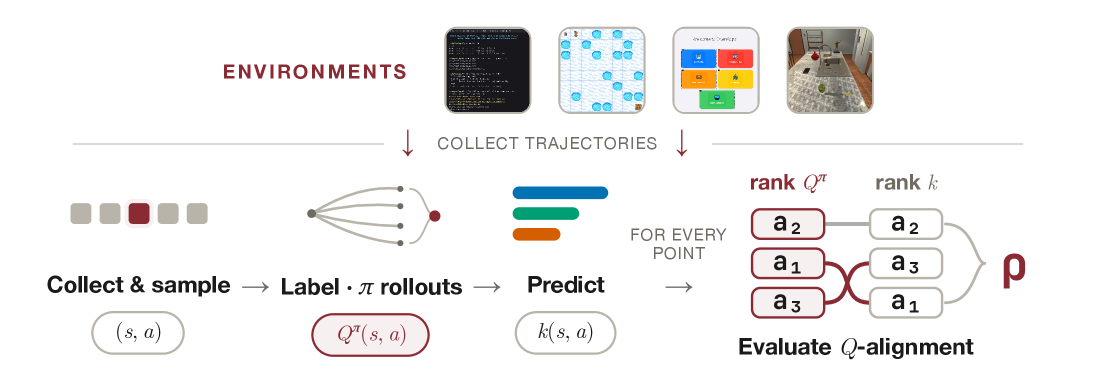
Figure 1 — QVal 디자인 파이프라인
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 에이전트의 상태-동작(state-action) 쌍을 수집하고, 이를 참조 정책(reference policy)의 Q-value로 라벨링한 뒤, 각 방법론이 예측한 점수와 실제 Q-value 간의 Spearman's ρ 및 Kendall's τ 상관관계를 측정하는 방식을 제안합니다 [Figure 1]. 이를 통해 총 7개 방법론 패밀리, 21개 방법을 평가한 결과, 단순한 Direct Prompting 방식이 복잡한 최신 방법론들보다 평균적으로 더 높은 Q-alignment 성능을 보였습니다 [Figure 2]. 실험 결과, 모델 백본의 크기나 환경의 복잡도 변화에도 불구하고 동일 패밀리 내의 방법론들은 유사한 성능 군집을 형성하는 경향이 나타났습니다 [Figure 3]. 또한, 추가적인 복잡성을 더하는 방식이 항상 성능 향상으로 이어지지 않음을 확인하였으며, 텍스트 기반 관찰 정보가 시각 정보보다 더 안정적인 신호를 제공하는 등 다양한 환경적 특성을 규명하였습니다 [Figure 4].
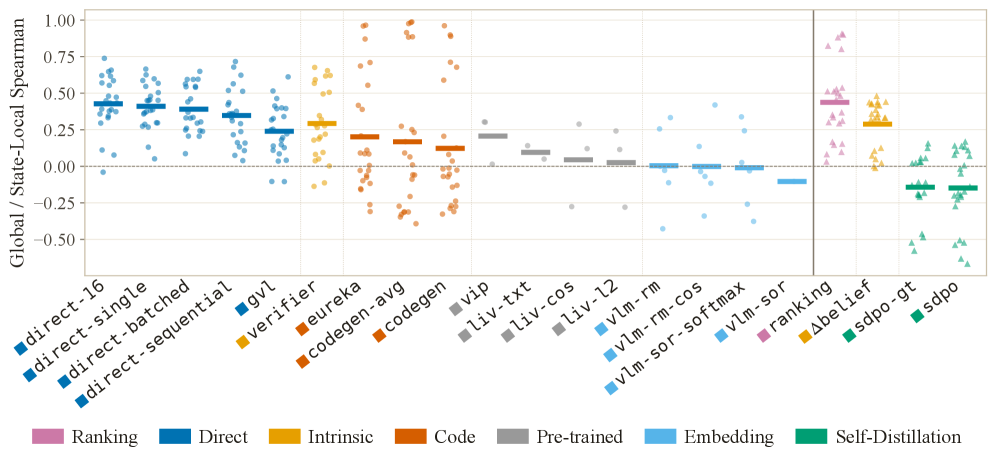
Figure 2 — 방법별 Q-alignment 분포
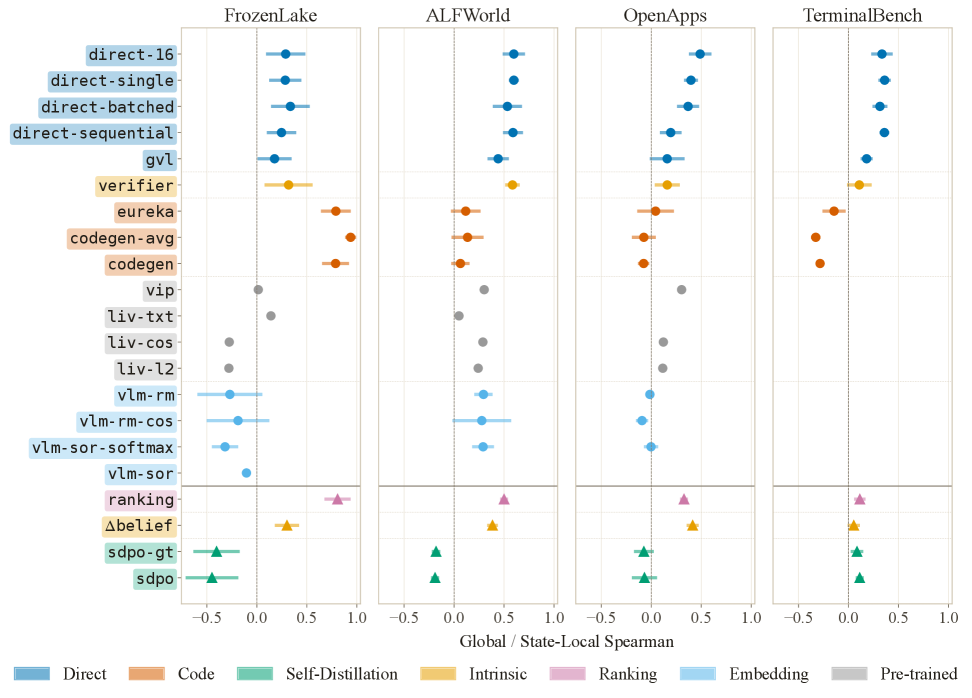
Figure 3 — 환경별 방법론 성능
4. Conclusion & Impact (결론 및 시사점)
본 연구는 dense supervision 방법론의 품질을 독립적으로 평가할 수 있는 Training-Free 테스트베드인 QVal을 성공적으로 제시하였습니다. 이 프레임워크는 비용 효율적인 조기 평가(early iteration)를 가능하게 하여, 연구자들이 복잡한 RL 파이프라인을 구축하기 전 최적의 신호 모델을 선별할 수 있도록 지원합니다. 본 연구는 방법론의 복잡성보다 신호 자체의 alignment를 검증하는 것이 필수적임을 시사하며, 에이전트 학습 생태계 전반의 효율적인 연구 방향을 제시했다는 점에서 높은 가치를 지닙니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] CoffeeBench: Benchmarking Long-Horizon LLM Agents in Heterogeneous Multi-Agent Economies
- [논문리뷰] Retrospective Harness Optimization: Improving LLM Agents via Self-Preference over Trajectory Rollouts
- [논문리뷰] Meta-Cognitive Memory Policy Optimization for Long-Horizon LLM Agents
- [논문리뷰] MemTrain: Self-Supervised Context Memory Training
- [논문리뷰] LongDS-Bench: On the Failure of Long-Horizon Agentic Data Analysis
Review 의 다른글
- 이전글 [논문리뷰] PolyFlow: Continuous Topology Embedding Flow Matching for Artist-style Mesh Generation
- 현재글 : [논문리뷰] QVal: Cheaply Evaluating Dense Supervision Signals for Long-Horizon LLM Agents
- 다음글 [논문리뷰] RedVox: Safety and Fairness Gaps in Speech Models Across Languages
댓글