[논문리뷰] ELDR: Expert-Locality-Aware Decode Routing for PD-Disaggregated MoE Serving
링크: 논문 PDF로 바로 열기
Part 1: 요약 본문
저자: Sangjin Choi, Sukmin Cho, Yifan Xiong, Ziyue Yang, Youngjin Kwon, Peng Cheng
1. Key Terms & Definitions (핵심 용어 및 정의)
- PD (Prefill-Decode) Disaggregation: LLM 추론 시
prefill과decode단계를 서로 다른 워커 풀에서 독립적으로 수행하여 리소스 활용도를 최적화하는 아키텍처. - MoE (Mixture-of-Experts): 전체 모델 파라미터 중 일부만 활성화하는 sparse 모델 아키텍처로, decode 시 어떤 전문가(Expert)를 활성화하느냐에 따라 메모리 대역폭 점유 및 latency가 결정됨.
- Expert Signature: 특정 요청의
prefill단계에서 수집된 전문가 활성화 정보를 바탕으로,decode단계에서의 전문가 활성화 경향을 예측하는 벡터 표현. - Locality-Band Routing:
expert signature의 유사도 기반 군집화(Clustering)와 워커의 실시간 부하(Load)를 동시에 고려하여, 전문가를 공유할 가능성이 높은 요청을 동일 워커로 라우팅하는 기법. - TPOT (Time-per-Output-Token): LLM 생성 단계에서 토큰 하나를 생성하는 데 걸리는 시간으로, MoE 모델의 성능을 결정짓는 핵심 지표.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 PD-disaggregated MoE 서빙 환경에서 기존 라우팅 방식이 단순히 부하 분산(Load balancing)에만 집중하여 발생하는 비효율을 해결하고자 합니다. MoE 모델의 decode 단계는 메모리 대역폭 의존적이며, 배치 내 요청들이 공유하는 전문가의 집합(Union)이 클수록 latency가 급증합니다 [Figure 2]. 기존 라우터는 요청 간의 이러한 '전문가 공유(Expert overlap)' 현상을 고려하지 않고 부하만 분산하여, 전문가 분포가 불균형한 배치로 인해 불필요한 메모리 액세스가 발생하고 latency가 증가하는 문제를 겪습니다. 이를 위해 prefill 단계의 정보로 decode 시의 전문가 활성화를 예측하고, 요청들의 '전문가 지역성(Expert locality)'을 활용한 새로운 라우팅 설계가 필요합니다.
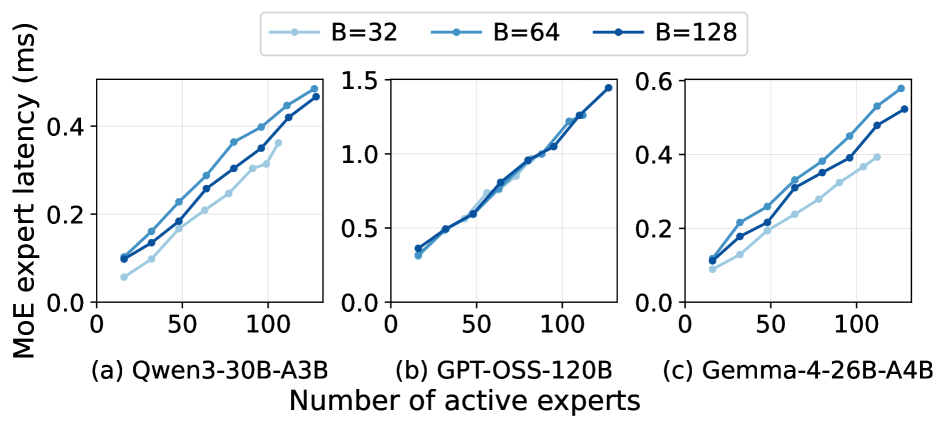
Figure 2 — 전문가 활성화와 latency 상관관계
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 expert locality를 라우팅의 핵심 지표로 활용하는 ELDR (Expert-Locality-Aware Decode Routing) 프레임워크를 제안합니다. ELDR은 요청의 prefill 단계에서 발생하는 전문가 활성화를 수집하여 Expert Signature를 생성하고, 이를 통해 요청 간의 전문가 공유 가능성을 예측합니다 [Figure 6]. 오프라인 단계에서는 Balanced K-Means를 통해 워커별로 전문가 군집을 할당하고, 온라인에서는 워커의 부하와 함께 Locality-band 내 최적 워커를 선택하여 라우팅을 수행합니다. 특히 prefix caching 상황에서도 일관된 signature를 유지하기 위해, KV cache와 동일한 블록 단위로 전문가 footprint를 기록하는 coherent cache 전략을 도입합니다. 실험 결과, ELDR은 다양한 MoE 모델(Qwen3-30B, GPT-OSS-120B 등) 환경에서 최상의 기존 라우팅 방식 대비 median TPOT을 5.9%에서 최대 13.9%까지 감소시키는 성능 향상을 달성했습니다. 이는 모델의 수정이나 추가적인 재학습 없이도 실질적인 latency 개선이 가능함을 보여줍니다.
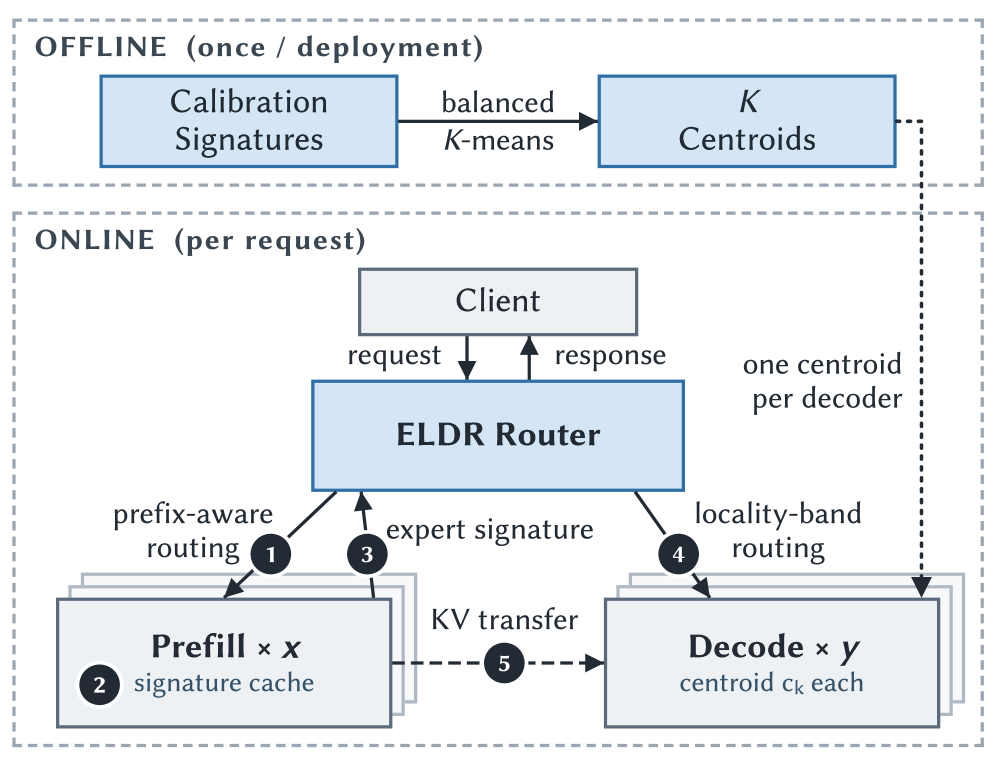
Figure 6 — ELDR 전체 아키텍처
4. Conclusion & Impact (결론 및 시사점)
본 연구는 MoE 모델의 decode latency가 요청 간의 전문가 지역성에 크게 좌우된다는 점을 규명하고, 이를 라우팅 전략에 효과적으로 통합한 ELDR을 성공적으로 제시했습니다. ELDR은 요청의 전문가 footprint를 라우팅 시점에 가시화하고, prefix caching과 같은 현대적인 서빙 기법과도 완벽하게 통합되는 유연성을 보여줍니다. 이 연구는 대규모 MoE 모델을 상용 환경에서 효율적으로 운영하고자 하는 인프라 연구 분야에 있어, 시스템 수준의 성능 최적화를 위한 새로운 아키텍처적 접근 방향을 제시했다는 점에서 중요한 시사점을 가집니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Scaling the Horizon, Not the Parameters: Reaching Trillion-Parameter Performance with a 35B Agent
- [논문리뷰] Focusing on What Matters: Saliency-Harnessing Accurate Routing for Diffusion MoE
- [논문리뷰] Cluster, Route, Escalate: Cascaded Framework for Cost-Aware LLM Serving
- [논문리뷰] Nemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
- [논문리뷰] Pruning and Distilling Mixture-of-Experts into Dense Language Models
Review 의 다른글
- 이전글 [논문리뷰] Domain Arithmetic: One-Shot VLA Adaptation under Environmental Shifts
- 현재글 : [논문리뷰] ELDR: Expert-Locality-Aware Decode Routing for PD-Disaggregated MoE Serving
- 다음글 [논문리뷰] Graph-Native Reinforcement Learning Enables Traceable Scientific Hypothesis Generation through Conceptual Recombination
댓글