[논문리뷰] PixelEyes: Decoupling Perception and Reasoning for Pinpoint Visual Evidence Seeking
링크: 논문 PDF로 바로 열기
메타데이터
저자: Dengxian Gong, Yuanzheng Wu, Haobo Yuan, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- PixelEyes: 인지(Perception)와 추론(Reasoning)을 명시적으로 분리하여 시각적 증거를 탐색하는 다중 턴(multi-turn) 시각 추론 에이전트입니다.
- SAMTok: 텍스트 형태의 referring expression을 입력받아 픽셀 단위의 정밀한 마스크를 생성하는 외부 참조 세그멘테이션(referring-segmentation) 도구입니다.
- Inattentional Blindness: 모델이 타겟을 포함하는 영역을 방문(crop)했음에도 불구하고, 타겟을 인식하거나 활용하지 못하는 현상을 의미합니다.
- Semantic-Region BFS: 중복된 영역 재방문을 방지하고 효율적으로 탐색하기 위해, 탐색 경로를 너비 우선 탐색(Breadth-First Search) 방식으로 설계한 전략입니다.
- Pinpoint-Bench: 위치 단서(hint)가 없는 초고해상도 이미지 데이터셋으로, localization 실패와 reasoning 실패를 엄격히 분리하여 평가할 수 있는 벤치마크입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 MLLM 기반 시각 추론 에이전트들이 인지와 추론을 단일 모델 내에서 결합함으로써 발생하는 성능 저하 문제를 해결하고자 합니다. 기존 방법론들은 타겟을 찾기 위한 grounding 능력과 추론 능력을 동시에 요구받는데, 이 결합된 구조는 종종 부정확한 위치 파악을 야기하고, 이로 인해 길고 비효율적인 탐색 궤적을 생성합니다 [Figure 1]. 특히, 모델이 정답 영역을 방문하더라도 인지 실패로 인해 정답을 도출하지 못하는 'Inattentional Blindness' 현상이 빈번하게 발생하며, 이는 기존 연구의 주요 한계점으로 지적됩니다. 따라서 저자들은 인지 기능을 외부 도구로 분리하고 추론 에이전트가 오직 '무엇을 찾아야 하는지'에만 집중하도록 하는 새로운 패러다임의 필요성을 강조합니다.
Figure 1 — 시각 탐색 패러다임 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 인지와 추론을 분리하고 Mask-guided Visual Search 및 Semantic-Region BFS를 도입한 PixelEyes 프레임워크를 제안합니다 [Figure 2]. PixelEyes는 SAMTok을 활용하여 픽셀 수준의 정밀한 마스크를 얻음으로써 grounding 정확도를 높이고, 이 정보를 바탕으로 타겟 중심의 crop을 수행하여 불필요한 배경 노이즈를 제거합니다 [Figure 3]. 또한 Semantic-Region BFS를 통해 탐색 중인 지역을 추적하여 중복 탐색을 회피하고 전체 탐색 효율을 극대화합니다. 실험 결과, PixelEyes-8B 모델은 Pinpoint-Bench에서 Accuracy 55.20%, TAE(Turn-to-Answer Efficiency) 26.64를 기록하며, 기존의 전문 에이전트 및 베이스라인 모델 대비 압도적인 성능 우위를 점했습니다 [Table 2]. 특히 LSR(Localization Success Rate)과 Accuracy 간의 격차를 분석함으로써 기존 에이전트들의 심각한 Inattentional Blindness를 정량적으로 증명하였으며, 본 기법이 이를 효과적으로 완화함을 입증했습니다.
Figure 2 — PixelEyes 파이프라인
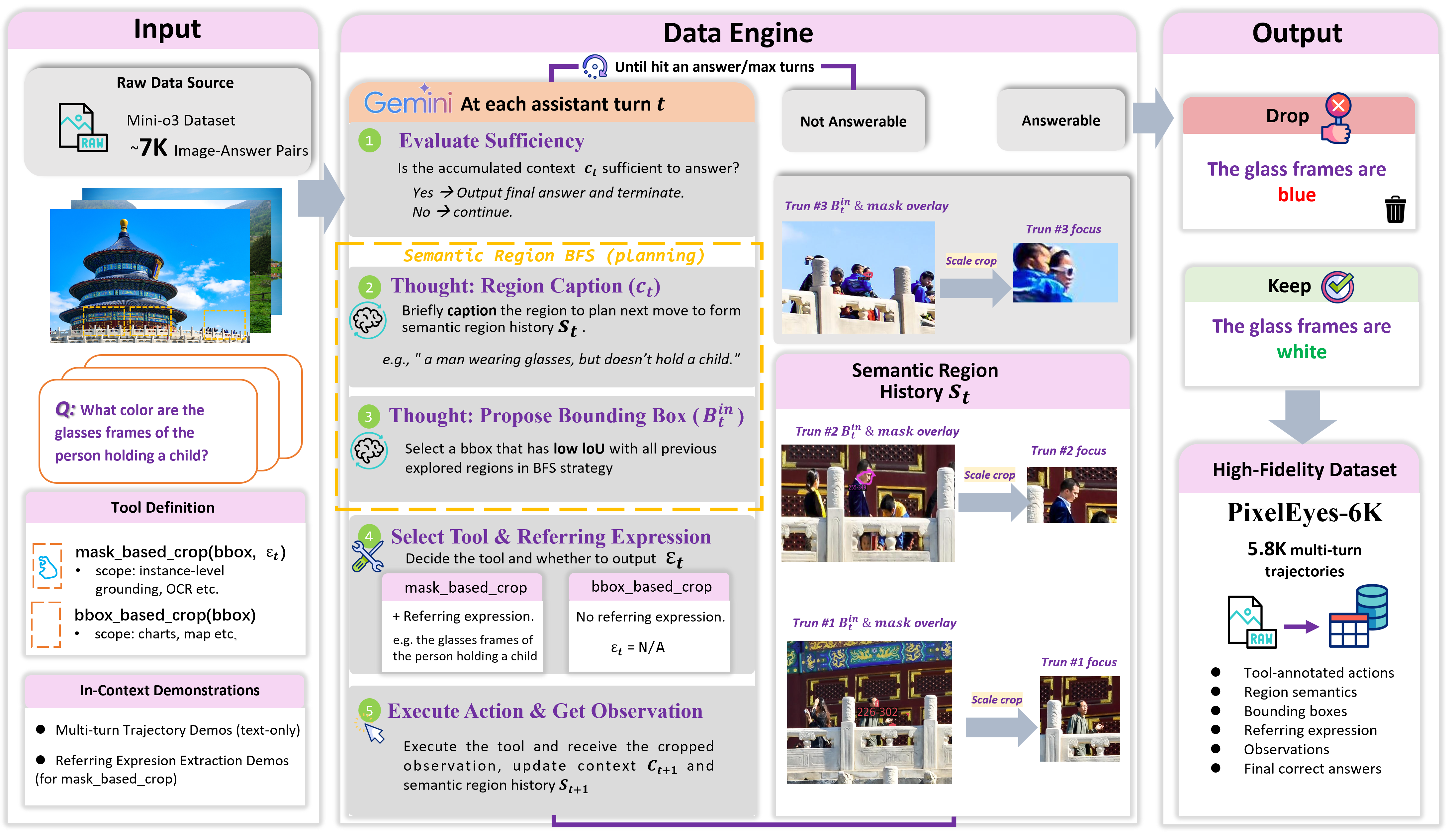
Figure 3 — 데이터셋 구축 프로세스
4. Conclusion & Impact (결론 및 시사점)
본 연구는 인지와 추론의 분리가 시각적 증거 탐색 효율을 획기적으로 개선할 수 있음을 입증하며, MLLM 에이전트 설계의 새로운 방향성을 제시합니다. 특히 제안된 Pinpoint-Bench와 관련 지표들은 향후 시각 추론 에이전트의 정밀한 성능 평가와 진단에 필수적인 기준이 될 것입니다. 이 연구는 복잡하고 고해상도인 이미지 환경에서도 높은 효율과 정확도를 보장하는 에이전트 개발을 가능케 하여, 향후 멀티모달 지능 연구 분야에 중대한 기여를 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] PerceptionRubrics: Calibrating Multimodal Evaluation to Human Perception
- [논문리뷰] Multimodal Continuous Reasoning via Asymmetric Mutual Variational Learning
- [논문리뷰] Illuminating Unified Multimodal Model for Free-form Interleaved Text-Image Generation
- [논문리뷰] ViQ: Text-Aligned Visual Quantized Representations at Any Resolution
- [논문리뷰] Running the Gauntlet: Re-evaluating the Capabilities of Agents Beyond Familiar Environments
Review 의 다른글
- 이전글 [논문리뷰] Personalization as Inverse Planning: Learning Latent Design Intents for Agentic Slide Generation via Structural Denoising
- 현재글 : [논문리뷰] PixelEyes: Decoupling Perception and Reasoning for Pinpoint Visual Evidence Seeking
- 다음글 [논문리뷰] Seed2.0 Model Card: Towards Intelligence Frontier for Real-World Complexity
댓글