[논문리뷰] Automatic Generation of High-Performance RL Environments
링크: 논문 PDF로 바로 열기
저자: Seth Karten, Rahul Dev Appapogu, Chi Jin
키워: Reinforcement Learning (RL), High-Performance Environments, Code Generation, Large Language Models (LLMs), Hierarchical Verification, JAX, Rust, Sim-to-sim Gap
1. Key Terms & Definitions (핵심 용어 및 정의)
- SPS (Steps Per Second) : RL 환경의 Throughput을 나타내는 지표로, 초당 처리할 수 있는 환경 Step 수를 의미합니다.
- Hierarchical Verification : Reference 환경과 Performance 환경 간의 Semantic Equivalence를 검증하기 위한 다단계(Level 1-4) 테스트 전략입니다.
- Sim-to-sim Gap : 하나의 Backend (Eperf)에서 학습된 Policy가 다른 Backend (Eref)에서 평가될 때 발생하는 성능 불일치로, Semantic Equivalence 부족을 나타냅니다.
- JAX : GPU 병렬 Pure Function에 주로 사용되는 고성능 머신러닝을 위한 수치 계산 라이브러리입니다.
- Rayon : Rust에서 CPU 병렬 처리를 위한 Data-Parallelism 라이브러리로, 멀티코어 CPU 환경에서 높은 확장성을 제공합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
일반적인 Reinforcement Learning (RL) 훈련에서 환경 시뮬레이션은 전체 Wall-Clock Time의 50-90% 를 소비하며, 이는 학습 Process의 주요 Bottleneck으로 작용합니다. 특히 Pokémon Showdown 과 같은 복잡한 시뮬레이터나 Cycle-Accurate Game Boy 에뮬레이터의 경우 이러한 오버헤드가 더욱 심각합니다. 기존에는 Brax , Gymnax , Pgx 등 고성능 RL 환경 구현을 위해 특정 도메인에 특화된 수개월의 노동 집약적 전문 엔지니어링이 요구되었습니다. 이러한 방식은 비용이 많이 들고 시간 소모적이어서, RL 연구자들이 새로운 환경을 실험하는 데 큰 제약이 됩니다. 본 연구는 이러한 문제를 해결하고, 고성능 RL 환경을 저렴하고 일상적인 RL Workflow의 표준 단계로 생산하는 방법론을 제시합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Complex RL Environments 를 고성능 구현으로 변환하기 위한 재사용 가능한 Recipe 를 제안합니다. 이 Recipe는 Generic Prompt Template , Hierarchical Verification , 그리고 Iterative Agent-Assisted Repair 로 구성됩니다
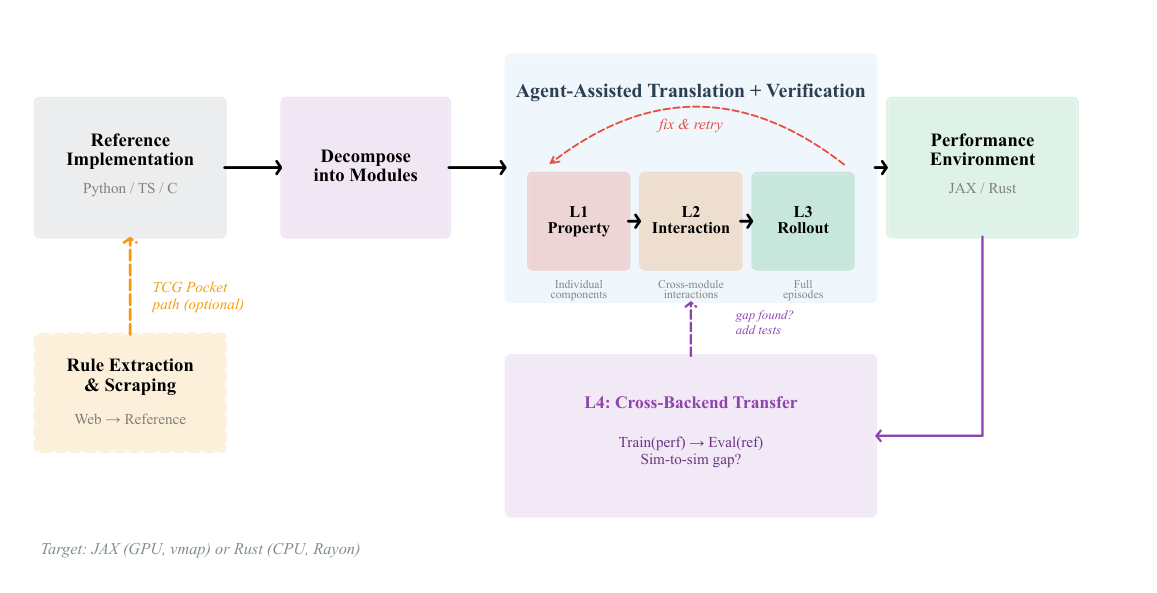 Figure 2: Translation and verification pipeline.
Figure 2: Translation and verification pipeline.
. 이 방법론은 Coding Agents ( Gemini 3 Flash Preview , Claude Sonnet 4.6 , Claude Opus 4.6 )를 활용하여 Semantic Equivalence를 유지하면서 고성능 환경을 생성합니다. Hierarchical Verification 은 네 가지 Level로 구성되어 있습니다:
- Level 1 (Property tests) : 개별 Component의 Input-Output 쌍을 검증합니다.
- Level 2 (Interaction tests) : Cross-Module 상태 의존성 및 이벤트 순서를 검증합니다.
- Level 3 (Rollout comparison) : Matched Seed 및 Action Sequence 하에 전체 Episode를 실행하여 Step-Level Output을 비교합니다.
- Level 4 (Cross-backend policy transfer) : Eperf에서 훈련된 Policy를 Eref에서 평가하여 Sim-to-sim Gap 이 없음을 확인합니다.
이러한 계층적 검증은 복잡한 환경에서 Agent가 Convergence하는 데 필수적이며, 오류 발생 시 Root Cause를 Localize하여 Targeted Repair를 가능하게 합니다.
핵심 결과는 다음과 같습니다:
- 비용 효율성 : 5가지 환경을 변환하는 데 $10 미만 의 컴퓨팅 비용이 들었으며 [Table 4], 이는 기존 방식보다 훨씬 저렴합니다.
- Throughput 및 Speedup :
- EmuRust (C/Python → Rust): Rust Parallelism 을 통해 1.5x PPO Speedup 을 달성했습니다.
- PokeJAX (TypeScript → JAX): 최초의 GPU-Parallel Pokémon Battle Simulator 로, TypeScript Reference 대비 22,320x PPO Speedup ( 681 SPS 에서 15.2M SPS 로)을 기록하며, 이전에는 비실용적이었던 훈련을 가능하게 했습니다
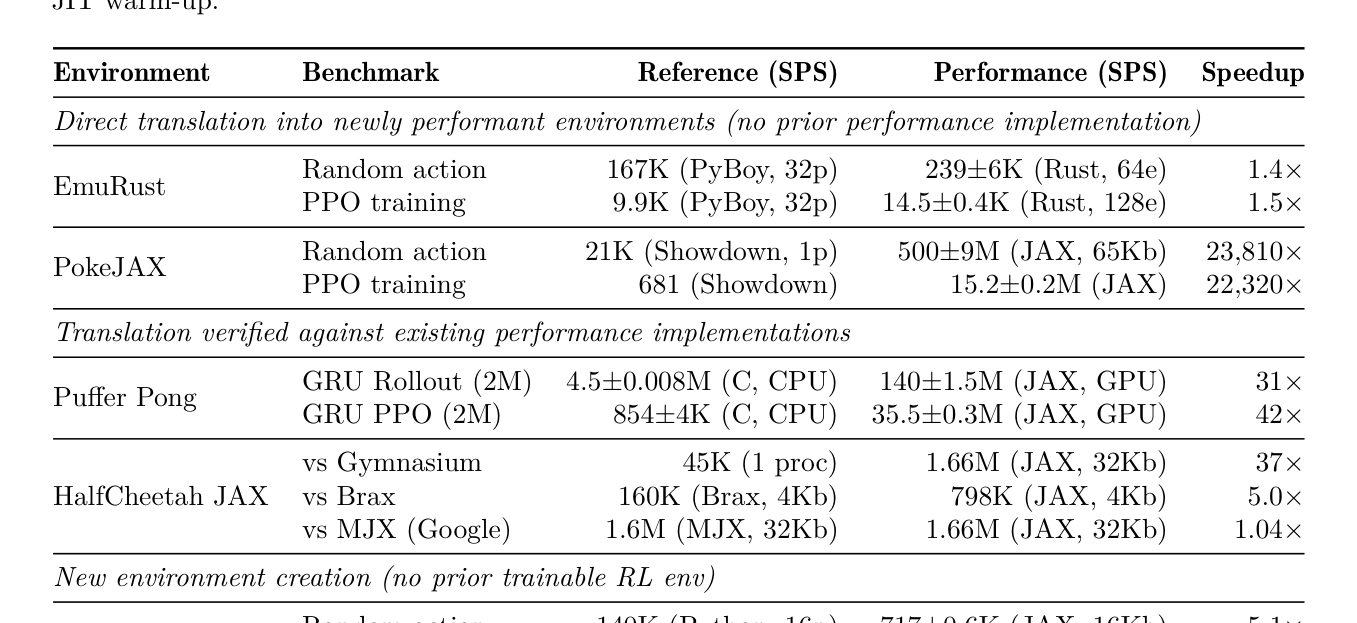 Table 2: Throughput comparison. Mean ± std from N=5 runs (CVs <3%); ~2M models; JAX excludes JIT warm-up.
Table 2: Throughput comparison. Mean ± std from N=5 runs (CVs <3%); ~2M models; JAX excludes JIT warm-up.
. - HalfCheetah JAX (MuJoCo/Gymnasium → JAX): Matched GPU Batch Size에서 MJX 와 Throughput Parity ( 1.04x )를 달성하고, Brax 대비 5x 더 빠른 성능을 보였습니다 [Table 2]. - Puffer Pong (C → JAX): Scan-Fused GPU 훈련을 통해 42x PPO Speedup 을 달성했습니다 [Table 2]. - TCGJax (Web rules → Python → JAX): 웹에서 추출된 Specification으로 생성된 최초의 Deployable JAX Pokémon TCG Engine 으로, Python Reference 대비 6.6x PPO Speedup 을 보였습니다 [Table 2].
- 훈련 오버헤드 감소 : 200M Parameter 모델에서 환경 오버헤드가 전체 훈련 시간의 4% 미만 으로 감소했습니다
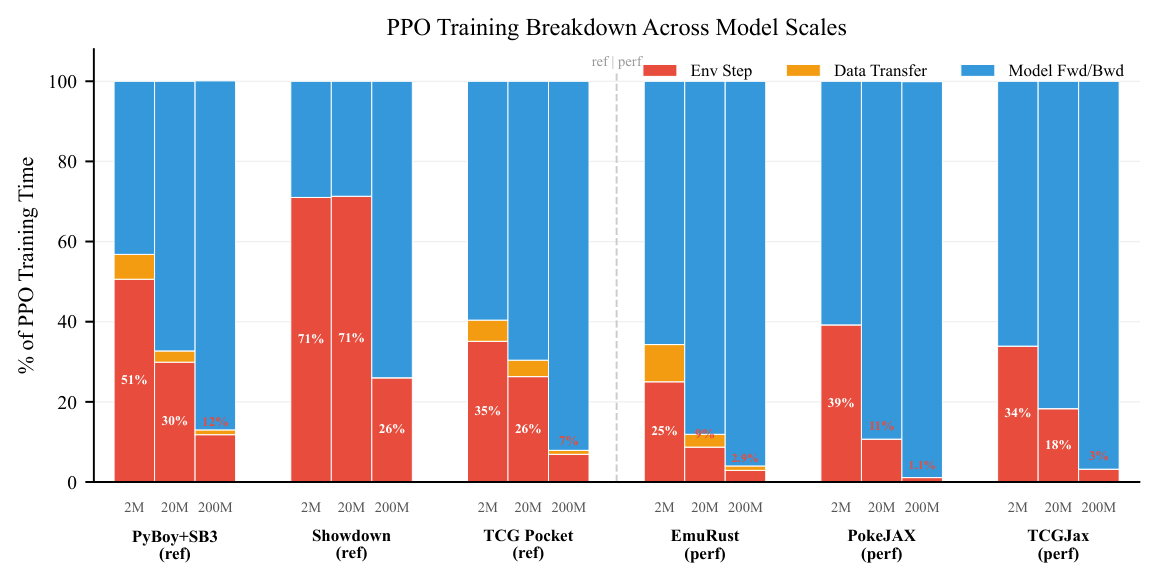 Figure 3: PPO training time breakdown across model scales. Three bars per implementation show 2M, 20M, 200M parameter models. Performance implementations drop to ≤4% env overhead at 200M. All on 1x RTX 5090.
Figure 3: PPO training time breakdown across model scales. Three bars per implementation show 2M, 20M, 200M parameter models. Performance implementations drop to ≤4% env overhead at 200M. All on 1x RTX 5090.
.
- Semantic Equivalence : 모든 5개 환경에서 Hierarchical Verification 을 통과했으며, Cross-Backend Policy Transfer (L4) 를 통해 Zero Sim-to-sim Gap 을 확인했습니다 [Table 3, Figure 4].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Coding Agents 가 Hierarchical Verification Recipe의 지침에 따라 Complex RL Environments 를 Semantic Equivalence 를 유지하면서 고성능 구현으로 저렴하게 변환할 수 있음을 입증했습니다. 이 방법론은 환경의 복잡성과 훈련 비용을 분리하여, 연구자들이 기존 JAX Port 에 제한받지 않고 필요한 환경의 성능 버전을 신속하게 생성할 수 있도록 합니다. 결과적으로 환경 생성은 RL Workflow의 Routine하고 저렴한 단계가 되어, 시뮬레이션 Bottleneck을 제거하고 RL 연구를 가속화하는 데 기여합니다. 이는 학계와 산업계 모두에서 새로운 환경 기반 연구 및 개발을 촉진할 중요한 시사점을 가집니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] Understanding the Behaviors of Environment-aware Information Retrieval
- [논문리뷰] Thinking with Visual Grounding
- [논문리뷰] Taylor-Calibrate: Principled Initialization for Hybrid Linear Attention Distillation
- [논문리뷰] Selective Synergistic Learning for Video Object-Centric Learning
Review 의 다른글
- 이전글 [논문리뷰] Are Video Reasoning Models Ready to Go Outside?
- 현재글 : [논문리뷰] Automatic Generation of High-Performance RL Environments
- 다음글 [논문리뷰] Coarse-Guided Visual Generation via Weighted h-Transform Sampling
댓글