[논문리뷰] Are Video Reasoning Models Ready to Go Outside?
링크: 논문 PDF로 바로 열기
저자: Yangfan He, Changgyu Boo, Jaehong Yoon
키워: Video Reasoning, Robustness, Vision-Language Models (VLMs), Spatio-Temporal Corruption, Curriculum Learning, PVRBench, Dual-Branch Alignment
1. Key Terms & Definitions (핵심 용어 및 정의)
- ROVA (RObust Video Alignment) : 현실적인 시각적 교란(visual disturbances) 하에서 강건한 비전 추론(robust vision reasoning)을 위한 새로운 훈련 프레임워크입니다.
- PVRBench (Perturbed Video Reasoning Benchmark) : 다양한 현실적 교란(realistic perturbations) 하에서 비디오 추론 모델의 강건성(robustness)을 평가하기 위해 새로 도입된 벤치마크입니다.
- Structured Spatio-Temporal Corruption : 날씨, 조명, 폐색, 카메라 움직임 등 4가지 현실적 교란을 모델링하며, 공간적 기반(spatial grounding)과 시간적 일관성(temporal coherence)을 가진 마스크를 사용하여 비디오를 왜곡하는 기법입니다.
- Self-Reflective Difficulty-Aware Training : 모델의 변화하는 능력에 따라 정보성 샘플(informative samples)의 우선순위를 동적으로 조정하는 온라인 훈련 전략으로, 모델이 스스로 샘플 난이도를 재평가하여 적응적으로 학습합니다.
- Dual-Branch Alignment : 클린(clean) 입력과 교란된(perturbed) 입력 쌍 사이의 출력 일관성(output consistency)을 강제하는 목표 함수로, 강건성 인식 일관성 보상(robustness-aware consistency reward)에 의해 가이드됩니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
실제 환경에 배포된 Vision-Language Models (VLMs)는 날씨, 폐색, 카메라 움직임과 같은 방해 요소를 자주 마주칩니다. 이러한 조건에서 모델의 비디오 이해 및 추론 능력은 크게 저하되며, 이는 통제된(controlled) 평가 환경과 실제 환경에서의 강건성(robustness) 사이에 큰 간극이 있음을 보여줍니다. 기존 연구들은 데이터 증강이나 랜덤 프레임 마스킹 등을 통해 강건성을 개선하려 했지만, 다양한 교란이 유발하는 각기 다른 실패 모드를 간과하여 복잡한 현실 환경에 효과적으로 대응하지 못했습니다. 특히, 시간적 일관성(temporally coherent)과 공간적 기반(spatially grounded)이 있는 시각적 교란이 비디오 추론에 미치는 영향을 체계적으로 측정하는 표준 벤치마크가 부재하여, 모델 실패의 원인(인식 오류, 추론 취약성 등)을 진단하기 어려웠습니다.
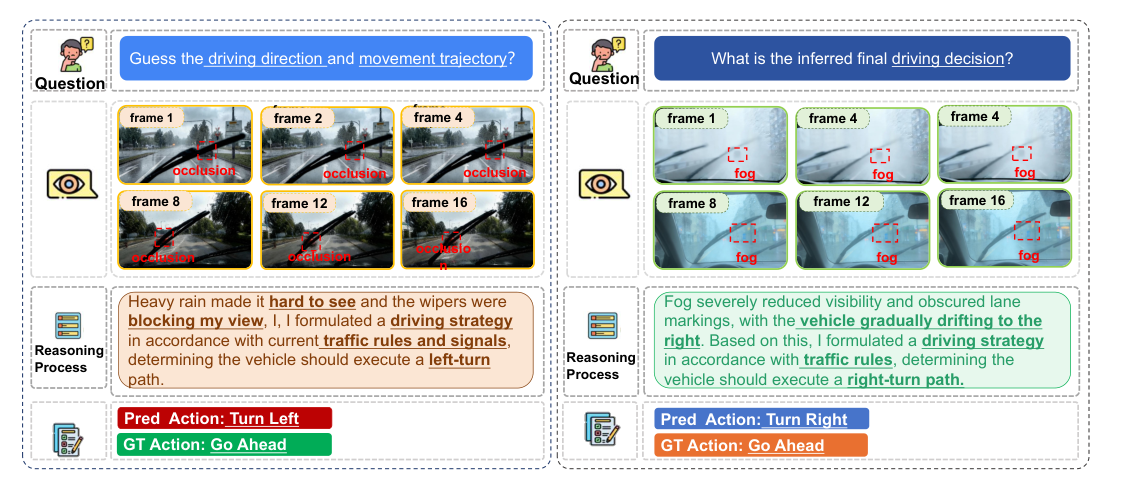 Figure 1: Failure cases of Qwen2.5-VL under two representative perturbations: (a) occlusion (left) and (b) adverse weather (right). The model incorrectly predicts Turn Left" under occlusion and Turn Right" under fog, despite the ground-truth being “Go Ahead" in both cases, demonstrating how realistic perturbations mislead reasoning and motivating the need for robustness-aware training.
Figure 1: Failure cases of Qwen2.5-VL under two representative perturbations: (a) occlusion (left) and (b) adverse weather (right). The model incorrectly predicts Turn Left" under occlusion and Turn Right" under fog, despite the ground-truth being “Go Ahead" in both cases, demonstrating how realistic perturbations mislead reasoning and motivating the need for robustness-aware training.
은 Qwen2.5-VL 모델이 폐색(occlusion)이나 안개(fog)와 같은 현실적인 교란 환경에서 "Go Ahead"라는 실제 정답 대신 "Turn Left" 또는 "Turn Right"를 잘못 예측하는 실패 사례를 보여주며, 이는 강건성 인식 훈련의 필요성을 강조합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 현실적인 시각적 교란 하에서 강건한 비디오 추론을 위한 새로운 훈련 프레임워크인 ROVA 를 제안합니다. ROVA는 세 가지 주요 단계로 구성됩니다. 첫째, Structured Spatio-Temporal Corruption 을 통해 동적이고 물리적으로 타당한 교란이 가해진 비디오-쿼리 쌍을 생성합니다. 이는 일반적인 이미지 증강과 달리 공간적 기반과 시간적 일관성을 가진 마스크를 사용하여 현실적인 왜곡을 모델링합니다. 둘째, Self-Reflective Difficulty-Aware Training 전략은 모델의 발전하는 능력에 맞춰 정보성 훈련 샘플(informative training samples)을 선별적으로 큐레이션합니다. 모델은 스스로 난이도를 재평가하여 중간 난이도의 샘플을 우선 처리하고, 너무 쉬운 샘플은 폐기하며, 너무 어려운 샘플은 임시 메모리 버퍼에 저장하여 나중에 재방문합니다. 셋째, Dual-Branch Alignment Optimization 은 클린 비디오 입력과 교란된 비디오 입력 간의 출력 일관성(output consistency)을 강건성 인식 보상(robustness-aware reward)과 Group Relative Policy Optimization (GRPO)를 통해 강제합니다.
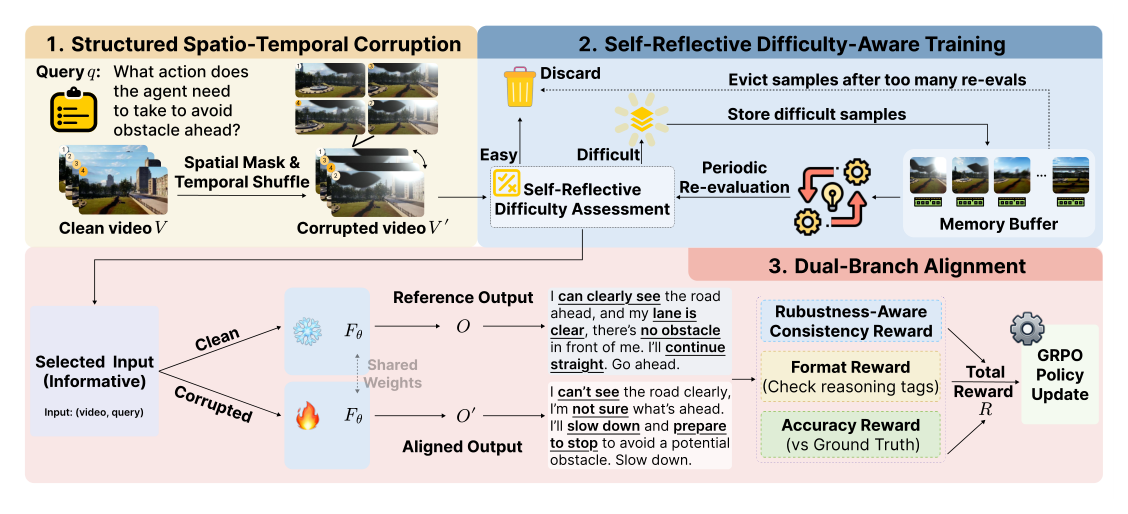 Figure 2: Overview of ROVA: (1) structured spatio-temporal corruption that generates realistic perturbations, (2) self-reflective evaluation with difficulty-aware online training that adaptively prioritizes informative samples, and (3) dual-branch alignment reward modeling that enforces output consistency between clean and perturbed inputs.
Figure 2: Overview of ROVA: (1) structured spatio-temporal corruption that generates realistic perturbations, (2) self-reflective evaluation with difficulty-aware online training that adaptively prioritizes informative samples, and (3) dual-branch alignment reward modeling that enforces output consistency between clean and perturbed inputs.
는 이 세 가지 단계의 개요를 보여줍니다.
실험 결과, ROVA는 PVRBench , UrbanVideo , VisBench 등 다양한 벤치마크에서 독점 및 오픈소스 모델들을 일관되게 능가했습니다. 특히, 현실적 교란 하에서 ROVA 7B 는 기존 베이스라인 모델인 Embodied-R 대비 평균 정확도(Avg. Acc.)를 0.42 에서 0.50 으로 17% 이상 향상시켰고, 추론 품질(Avg. Reasoning Quality)도 2.78 에서 3.12 로 9% 이상 높였습니다.
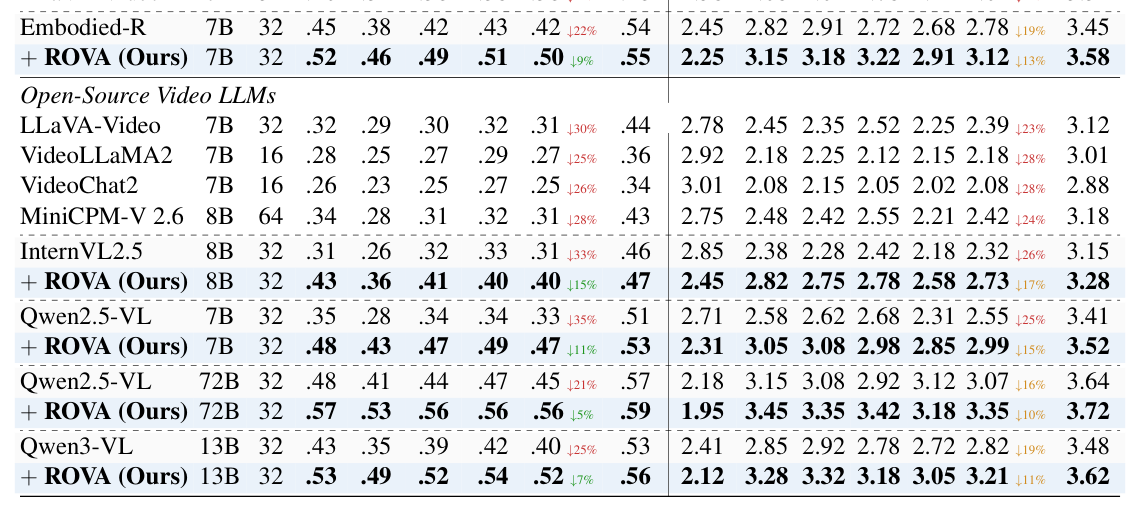 Table 2: Evaluation on PVRBench. We report accuracy under four visual perturbations (Lighting, Occlusion, camera Shake, Weather) on the left, and reasoning quality metrics on the right, including Fragility, Consistency, Belief, Recovery, and Attention (0 - 5 scale; Higher is better, except for Fra (↓)). #Fr: the number of frames, Avg.: the average performance, and Orig.: the average performance on clean (unperturbed) data. We exclude Fra. when computing Avg.† and Orig.†.
Table 2: Evaluation on PVRBench. We report accuracy under four visual perturbations (Lighting, Occlusion, camera Shake, Weather) on the left, and reasoning quality metrics on the right, including Fragility, Consistency, Belief, Recovery, and Attention (0 - 5 scale; Higher is better, except for Fra (↓)). #Fr: the number of frames, Avg.: the average performance, and Orig.: the average performance on clean (unperturbed) data. We exclude Fra. when computing Avg.† and Orig.†.
에 따르면, ROVA의 대규모 버전( 13B/72B )은 Gemini-3-Pro 및 GPT-4o 와 같은 선도적인 독점 모델과 동등하거나 그 이상의 성능을 보였습니다. 예를 들어, ROVA (Ours) 72B 는 평균 정확도 0.56 , 평균 추론 품질 3.35 를 달성하여 GPT-4o 의 0.51 및 3.39 에 필적합니다. 또한, ROVA 는 깨끗한(clean) 비디오에서도 일반화 성능(generalizability)이 향상되어 더욱 안정적이고 자신감 있는 추론을 제공합니다. 훈련 효율성 측면에서도 ROVA는 기존 방식 대비 GPU-hours 를 60.4% 절감하면서도 더 높은 정확도를 달성하여 리소스 효율성(resource-efficient)을 입증했습니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 현실적인 시각적 교란 하에서 비디오 추론 모델의 강건성(robustness)을 크게 향상시키는 ROVA 라는 훈련 프레임워크를 제안합니다. Structured Spatio-Temporal Corruption , Self-Reflective Difficulty-Aware Training , Dual-Branch Alignment 기법을 통합함으로써, ROVA는 모델이 교란에 강한 표현을 학습하고, 다양한 현실적 환경에서 신뢰할 수 있는 추론을 수행할 수 있도록 합니다. 또한, 현실적인 교란이 주입된 새로운 벤치마크인 PVRBench 를 도입하여, 기존 벤치마크의 한계점을 극복하고 비디오 추론 모델의 강건성을 체계적으로 평가할 수 있는 표준화된 도구를 제공합니다. ROVA의 성능 향상은 학계에 강건한 VLM 개발을 위한 실용적인 훈련 기법과 평가 프레임워크를 제시하며, 복잡한 실제 환경에서 자율주행, 로봇 공학 등 비디오 기반의 AI 시스템을 안정적으로 배포하는 데 중요한 시사점을 제공합니다. 이 연구는 미래의 광범위한 교란 유형과 복잡한 장기-수평적(long-horizon) embodied AI 태스크 연구를 위한 기반을 마련합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] Understanding the Behaviors of Environment-aware Information Retrieval
- [논문리뷰] Thinking with Visual Grounding
- [논문리뷰] Taylor-Calibrate: Principled Initialization for Hybrid Linear Attention Distillation
- [논문리뷰] Selective Synergistic Learning for Video Object-Centric Learning
Review 의 다른글
- 이전글 [논문리뷰] Accent Vector: Controllable Accent Manipulation for Multilingual TTS Without Accented Data
- 현재글 : [논문리뷰] Are Video Reasoning Models Ready to Go Outside?
- 다음글 [논문리뷰] Automatic Generation of High-Performance RL Environments
댓글